Dotfiles config update (2022-03-06)
This commit is contained in:
parent
4480129d15
commit
820c26cff4
123
.bashrc.save
123
.bashrc.save
@ -1,123 +0,0 @@
|
||||
# ~/.bashrc: executed by bash(1) for non-login shells.
|
||||
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
|
||||
# for examples
|
||||
|
||||
# If not running interactively, don't do anything
|
||||
case $- in
|
||||
*i*) ;;
|
||||
*) return;;
|
||||
esac
|
||||
|
||||
# don't put duplicate lines or lines starting with space in the history.
|
||||
# See bash(1) for more options
|
||||
HISTCONTROL=ignoreboth
|
||||
|
||||
# append to the history file, don't overwrite it
|
||||
shopt -s histappend
|
||||
|
||||
# for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
|
||||
HISTSIZE=1000
|
||||
HISTFILESIZE=2000
|
||||
|
||||
# check the window size after each command and, if necessary,
|
||||
# update the values of LINES and COLUMNS.
|
||||
shopt -s checkwinsize
|
||||
|
||||
# If set, the pattern "**" used in a pathname expansion context will
|
||||
# match all files and zero or more directories and subdirectories.
|
||||
#shopt -s globstar
|
||||
|
||||
# make less more friendly for non-text input files, see lesspipe(1)
|
||||
#[ -x /usr/bin/lesspipe ] && eval "$(SHELL=/bin/sh lesspipe)"
|
||||
|
||||
# set variable identifying the chroot you work in (used in the prompt below)
|
||||
if [ -z "${debian_chroot:-}" ] && [ -r /etc/debian_chroot ]; then
|
||||
debian_chroot=$(cat /etc/debian_chroot)
|
||||
fi
|
||||
|
||||
# set a fancy prompt (non-color, unless we know we "want" color)
|
||||
case "$TERM" in
|
||||
xterm-color|*-256color) color_prompt=yes;;
|
||||
esac
|
||||
|
||||
# uncomment for a colored prompt, if the terminal has the capability; turned
|
||||
# off by default to not distract the user: the focus in a terminal window
|
||||
# should be on the output of commands, not on the prompt
|
||||
#force_color_prompt=yes
|
||||
|
||||
if [ -n "$force_color_prompt" ]; then
|
||||
if [ -x /usr/bin/tput ] && tput setaf 1 >&/dev/null; then
|
||||
# We have color support; assume it's compliant with Ecma-48
|
||||
# (ISO/IEC-6429). (Lack of such support is extremely rare, and such
|
||||
# a case would tend to support setf rather than setaf.)
|
||||
color_prompt=yes
|
||||
else
|
||||
color_prompt=
|
||||
fi
|
||||
fi
|
||||
|
||||
if [ "$color_prompt" = yes ]; then
|
||||
PS1='${debian_chroot:+($debian_chroot)}\[\033[01;32m\]\u@\h\[\033[00m\]:\[\033[01;34m\]\w\[\033[00m\]\$ '
|
||||
else
|
||||
PS1='${debian_chroot:+($debian_chroot)}\u@\h:\w\$ '
|
||||
fi
|
||||
unset color_prompt force_color_prompt
|
||||
|
||||
# If this is an xterm set the title to user@host:dir
|
||||
case "$TERM" in
|
||||
xterm*|rxvt*)
|
||||
PS1="\[\e]0;${debian_chroot:+($debian_chroot)}\u@\h: \w\a\]$PS1"
|
||||
;;
|
||||
*)
|
||||
;;
|
||||
esac
|
||||
|
||||
# enable color support of ls and also add handy aliases
|
||||
if [ -x /usr/bin/dircolors ]; then
|
||||
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dircolors -b)"
|
||||
alias ls='ls --color=auto'
|
||||
#alias dir='dir --color=auto'
|
||||
#alias vdir='vdir --color=auto'
|
||||
|
||||
#alias grep='grep --color=auto'
|
||||
#alias fgrep='fgrep --color=auto'
|
||||
#alias egrep='egrep --color=auto'fi
|
||||
|
||||
# colored GCC warnings and errors
|
||||
#export GCC_COLORS='error=01;31:warning=01;35:note=01;36:caret=01;32:locus=01:quote=01'
|
||||
|
||||
# some more ls aliases
|
||||
alias ll='ls -l'
|
||||
alias la='ls -A'
|
||||
alias l='ls -CF'
|
||||
|
||||
# Alias definitions.
|
||||
# You may want to put all your additions into a separate file like
|
||||
# ~/.bash_aliases, instead of adding them here directly.
|
||||
# See /usr/share/doc/bash-doc/examples in the bash-doc package.
|
||||
|
||||
if [ -f ~/.bash_aliases ]; then
|
||||
. ~/.bash_aliases
|
||||
fi
|
||||
|
||||
# enable programmable completion features (you don't need to enable
|
||||
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
|
||||
# sources /etc/bash.bashrc).
|
||||
if ! shopt -oq posix; then
|
||||
if [ -f /usr/share/bash-completion/bash_completion ]; then
|
||||
. /usr/share/bash-completion/bash_completion
|
||||
elif [ -f /etc/bash_completion ]; then
|
||||
. /etc/bash_completion
|
||||
fi
|
||||
fi
|
||||
|
||||
PATH=${PATH}:/opt/qt515/bin
|
||||
echo ""
|
||||
echo ""
|
||||
#screenfetch -p
|
||||
neofetch --color_blocks off
|
||||
echo ""
|
||||
zsh
|
||||
|
||||
#[ -f ~/.fzf.bash ] && source ~/.fzf.bash
|
||||
|
||||
13
.fzf.zsh
13
.fzf.zsh
@ -1,13 +0,0 @@
|
||||
# Setup fzf
|
||||
# ---------
|
||||
if [[ ! "$PATH" == */home/q3aql/.fzf/bin* ]]; then
|
||||
export PATH="${PATH:+${PATH}:}/home/q3aql/.fzf/bin"
|
||||
fi
|
||||
|
||||
# Auto-completion
|
||||
# ---------------
|
||||
[[ $- == *i* ]] && source "/home/q3aql/.fzf/shell/completion.zsh" 2> /dev/null
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
source "/home/q3aql/.fzf/shell/key-bindings.zsh"
|
||||
@ -1,119 +0,0 @@
|
||||
---
|
||||
project_name: fzf
|
||||
|
||||
before:
|
||||
hooks:
|
||||
- go mod download
|
||||
|
||||
builds:
|
||||
- id: fzf-macos
|
||||
binary: fzf
|
||||
goos:
|
||||
- darwin
|
||||
goarch:
|
||||
- amd64
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
hooks:
|
||||
post: |
|
||||
sh -c '
|
||||
cat > /tmp/fzf-gon-amd64.hcl << EOF
|
||||
source = ["./dist/fzf-macos_darwin_amd64/fzf"]
|
||||
bundle_id = "kr.junegunn.fzf"
|
||||
apple_id {
|
||||
username = "junegunn.c@gmail.com"
|
||||
password = "@env:AC_PASSWORD"
|
||||
}
|
||||
sign {
|
||||
application_identity = "Developer ID Application: Junegunn Choi (Y254DRW44Z)"
|
||||
}
|
||||
zip {
|
||||
output_path = "./dist/fzf-{{ .Version }}-darwin_amd64.zip"
|
||||
}
|
||||
EOF
|
||||
gon /tmp/fzf-gon-amd64.hcl
|
||||
'
|
||||
|
||||
- id: fzf-macos-arm
|
||||
binary: fzf
|
||||
goos:
|
||||
- darwin
|
||||
goarch:
|
||||
- arm64
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
hooks:
|
||||
post: |
|
||||
sh -c '
|
||||
cat > /tmp/fzf-gon-arm64.hcl << EOF
|
||||
source = ["./dist/fzf-macos-arm_darwin_arm64/fzf"]
|
||||
bundle_id = "kr.junegunn.fzf"
|
||||
apple_id {
|
||||
username = "junegunn.c@gmail.com"
|
||||
password = "@env:AC_PASSWORD"
|
||||
}
|
||||
sign {
|
||||
application_identity = "Developer ID Application: Junegunn Choi (Y254DRW44Z)"
|
||||
}
|
||||
zip {
|
||||
output_path = "./dist/fzf-{{ .Version }}-darwin_arm64.zip"
|
||||
}
|
||||
EOF
|
||||
gon /tmp/fzf-gon-arm64.hcl
|
||||
'
|
||||
|
||||
- id: fzf
|
||||
goos:
|
||||
- linux
|
||||
- windows
|
||||
- freebsd
|
||||
- openbsd
|
||||
goarch:
|
||||
- amd64
|
||||
- arm
|
||||
- arm64
|
||||
goarm:
|
||||
- 5
|
||||
- 6
|
||||
- 7
|
||||
ldflags:
|
||||
- "-s -w -X main.version={{ .Version }} -X main.revision={{ .ShortCommit }}"
|
||||
ignore:
|
||||
- goos: freebsd
|
||||
goarch: arm
|
||||
- goos: openbsd
|
||||
goarch: arm
|
||||
- goos: freebsd
|
||||
goarch: arm64
|
||||
- goos: openbsd
|
||||
goarch: arm64
|
||||
|
||||
archives:
|
||||
- name_template: "{{ .ProjectName }}-{{ .Version }}-{{ .Os }}_{{ .Arch }}{{ if .Arm }}v{{ .Arm }}{{ end }}"
|
||||
builds:
|
||||
- fzf
|
||||
format: tar.gz
|
||||
format_overrides:
|
||||
- goos: windows
|
||||
format: zip
|
||||
files:
|
||||
- non-existent*
|
||||
|
||||
release:
|
||||
github:
|
||||
owner: junegunn
|
||||
name: fzf
|
||||
prerelease: auto
|
||||
name_template: '{{ .Tag }}'
|
||||
extra_files:
|
||||
- glob: ./dist/fzf-*darwin*.zip
|
||||
|
||||
snapshot:
|
||||
name_template: "{{ .Tag }}-devel"
|
||||
|
||||
changelog:
|
||||
sort: asc
|
||||
filters:
|
||||
exclude:
|
||||
- README
|
||||
- test
|
||||
@ -1,28 +0,0 @@
|
||||
Layout/LineLength:
|
||||
Enabled: false
|
||||
Metrics:
|
||||
Enabled: false
|
||||
Lint/ShadowingOuterLocalVariable:
|
||||
Enabled: false
|
||||
Style/MethodCallWithArgsParentheses:
|
||||
Enabled: true
|
||||
IgnoredMethods:
|
||||
- assert
|
||||
- exit
|
||||
- paste
|
||||
- puts
|
||||
- raise
|
||||
- refute
|
||||
- require
|
||||
- send_keys
|
||||
IgnoredPatterns:
|
||||
- ^assert_
|
||||
- ^refute_
|
||||
Style/NumericPredicate:
|
||||
Enabled: false
|
||||
Style/StringConcatenation:
|
||||
Enabled: false
|
||||
Style/OptionalBooleanParameter:
|
||||
Enabled: false
|
||||
Style/WordArray:
|
||||
MinSize: 1
|
||||
565
.fzf/ADVANCED.md
565
.fzf/ADVANCED.md
@ -1,565 +0,0 @@
|
||||
Advanced fzf examples
|
||||
======================
|
||||
|
||||
*(Last update: 2021/05/22)*
|
||||
|
||||
<!-- vim-markdown-toc GFM -->
|
||||
|
||||
* [Introduction](#introduction)
|
||||
* [Screen Layout](#screen-layout)
|
||||
* [`--height`](#--height)
|
||||
* [`fzf-tmux`](#fzf-tmux)
|
||||
* [Popup window support](#popup-window-support)
|
||||
* [Dynamic reloading of the list](#dynamic-reloading-of-the-list)
|
||||
* [Updating the list of processes by pressing CTRL-R](#updating-the-list-of-processes-by-pressing-ctrl-r)
|
||||
* [Toggling between data sources](#toggling-between-data-sources)
|
||||
* [Ripgrep integration](#ripgrep-integration)
|
||||
* [Using fzf as the secondary filter](#using-fzf-as-the-secondary-filter)
|
||||
* [Using fzf as interative Ripgrep launcher](#using-fzf-as-interative-ripgrep-launcher)
|
||||
* [Switching to fzf-only search mode](#switching-to-fzf-only-search-mode)
|
||||
* [Log tailing](#log-tailing)
|
||||
* [Key bindings for git objects](#key-bindings-for-git-objects)
|
||||
* [Files listed in `git status`](#files-listed-in-git-status)
|
||||
* [Branches](#branches)
|
||||
* [Commit hashes](#commit-hashes)
|
||||
* [Color themes](#color-themes)
|
||||
* [Generating fzf color theme from Vim color schemes](#generating-fzf-color-theme-from-vim-color-schemes)
|
||||
|
||||
<!-- vim-markdown-toc -->
|
||||
|
||||
Introduction
|
||||
------------
|
||||
|
||||
fzf is an interactive [Unix filter][filter] program that is designed to be
|
||||
used with other Unix tools. It reads a list of items from the standard input,
|
||||
allows you to select a subset of the items, and prints the selected ones to
|
||||
the standard output. You can think of it as an interactive version of *grep*,
|
||||
and it's already useful even if you don't know any of its options.
|
||||
|
||||
```sh
|
||||
# 1. ps: Feed the list of processes to fzf
|
||||
# 2. fzf: Interactively select a process using fuzzy matching algorithm
|
||||
# 3. awk: Take the PID from the selected line
|
||||
# 3. kill: Kill the process with the PID
|
||||
ps -ef | fzf | awk '{print $2}' | xargs kill -9
|
||||
```
|
||||
|
||||
[filter]: https://en.wikipedia.org/wiki/Filter_(software)
|
||||
|
||||
While the above example succinctly summarizes the fundamental concept of fzf,
|
||||
you can build much more sophisticated interactive workflows using fzf once you
|
||||
learn its wide variety of features.
|
||||
|
||||
- To see the full list of options and features, see `man fzf`
|
||||
- To see the latest additions, see [CHANGELOG.md](CHANGELOG.md)
|
||||
|
||||
This document will guide you through some examples that will familiarize you
|
||||
with the advanced features of fzf.
|
||||
|
||||
Screen Layout
|
||||
-------------
|
||||
|
||||
### `--height`
|
||||
|
||||
fzf by default opens in fullscreen mode, but it's not always desirable.
|
||||
Oftentimes, you want to see the current context of the terminal while using
|
||||
fzf. `--height` is an option for opening fzf below the cursor in
|
||||
non-fullscreen mode so you can still see the previous commands and their
|
||||
results above it.
|
||||
|
||||
```sh
|
||||
fzf --height=40%
|
||||
```
|
||||
|
||||
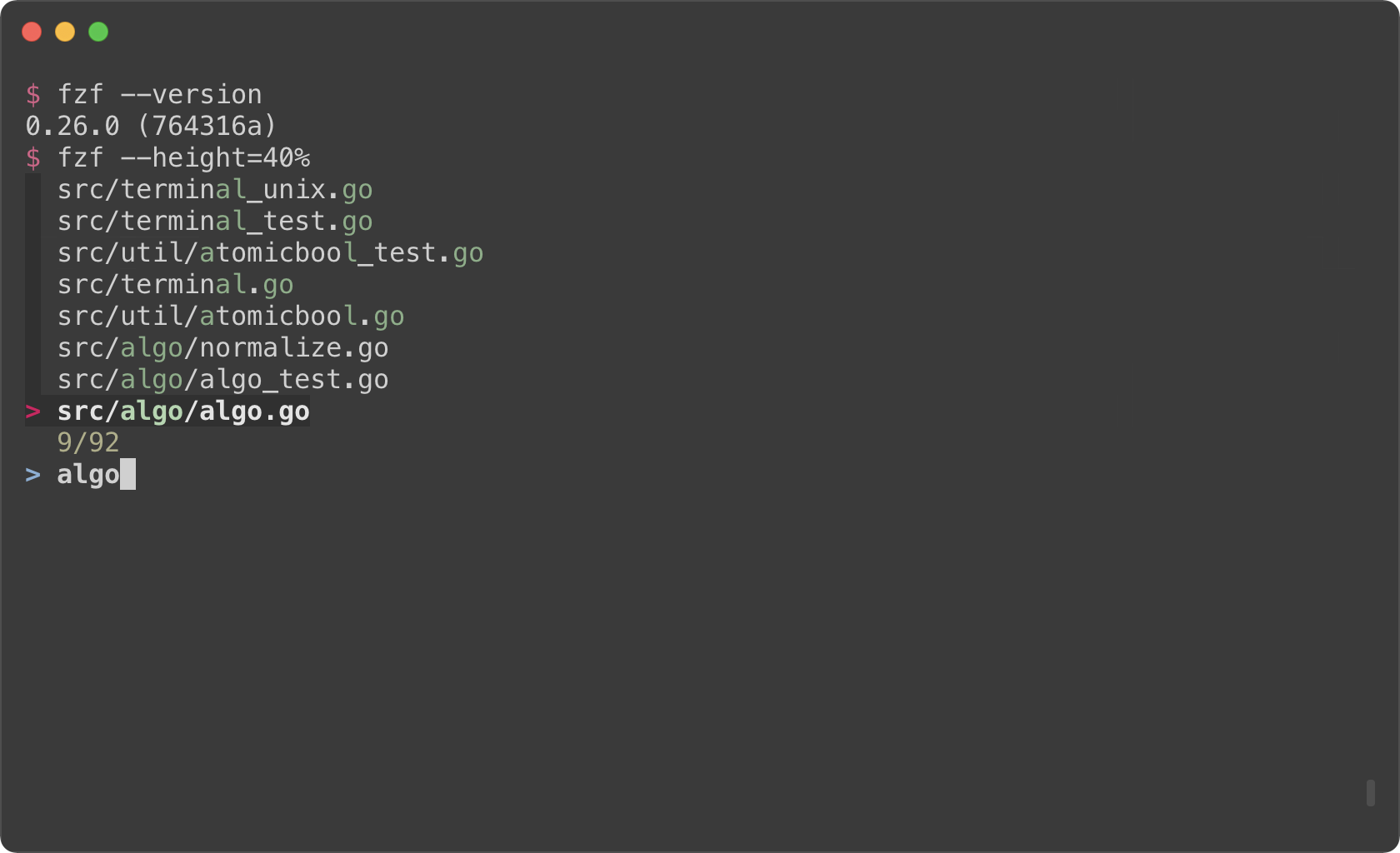
|
||||
|
||||
You might also want to experiment with other layout options such as
|
||||
`--layout=reverse`, `--info=inline`, `--border`, `--margin`, etc.
|
||||
|
||||
```sh
|
||||
fzf --height=40% --layout=reverse
|
||||
fzf --height=40% --layout=reverse --info=inline
|
||||
fzf --height=40% --layout=reverse --info=inline --border
|
||||
fzf --height=40% --layout=reverse --info=inline --border --margin=1
|
||||
fzf --height=40% --layout=reverse --info=inline --border --margin=1 --padding=1
|
||||
```
|
||||
|
||||
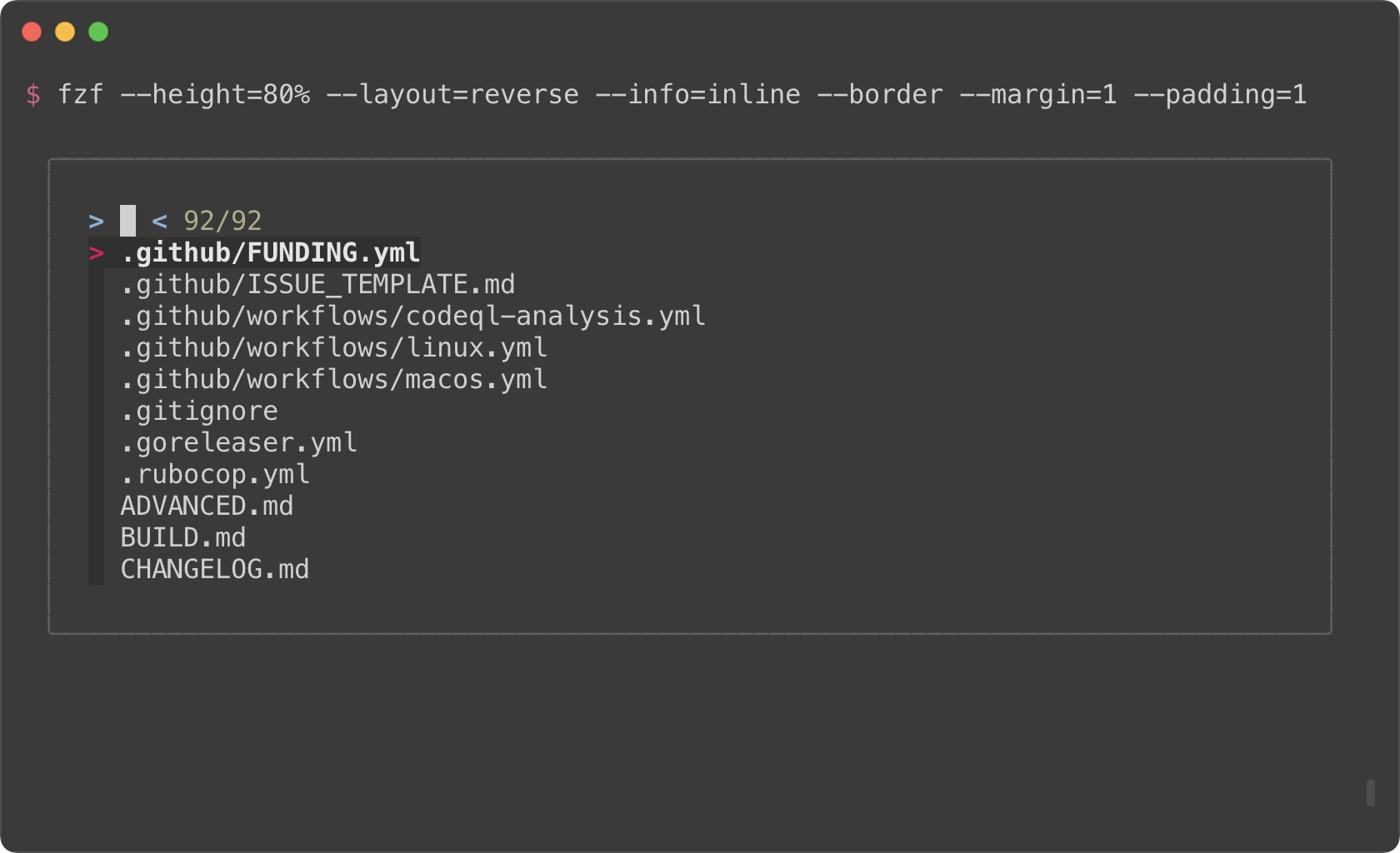
|
||||
|
||||
*(See `Layout` section of the man page to see the full list of options)*
|
||||
|
||||
But you definitely don't want to repeat `--height=40% --layout=reverse
|
||||
--info=inline --border --margin=1 --padding=1` every time you use fzf. You
|
||||
could write a wrapper script or shell alias, but there is an easier option.
|
||||
Define `$FZF_DEFAULT_OPTS` like so:
|
||||
|
||||
```sh
|
||||
export FZF_DEFAULT_OPTS="--height=40% --layout=reverse --info=inline --border --margin=1 --padding=1"
|
||||
```
|
||||
|
||||
### `fzf-tmux`
|
||||
|
||||
Before fzf had `--height` option, we would open fzf in a tmux split pane not
|
||||
to take up the whole screen. This is done using `fzf-tmux` script.
|
||||
|
||||
```sh
|
||||
# Open fzf on a tmux split pane below the current pane.
|
||||
# Takes the same set of options.
|
||||
fzf-tmux --layout=reverse
|
||||
```
|
||||
|
||||
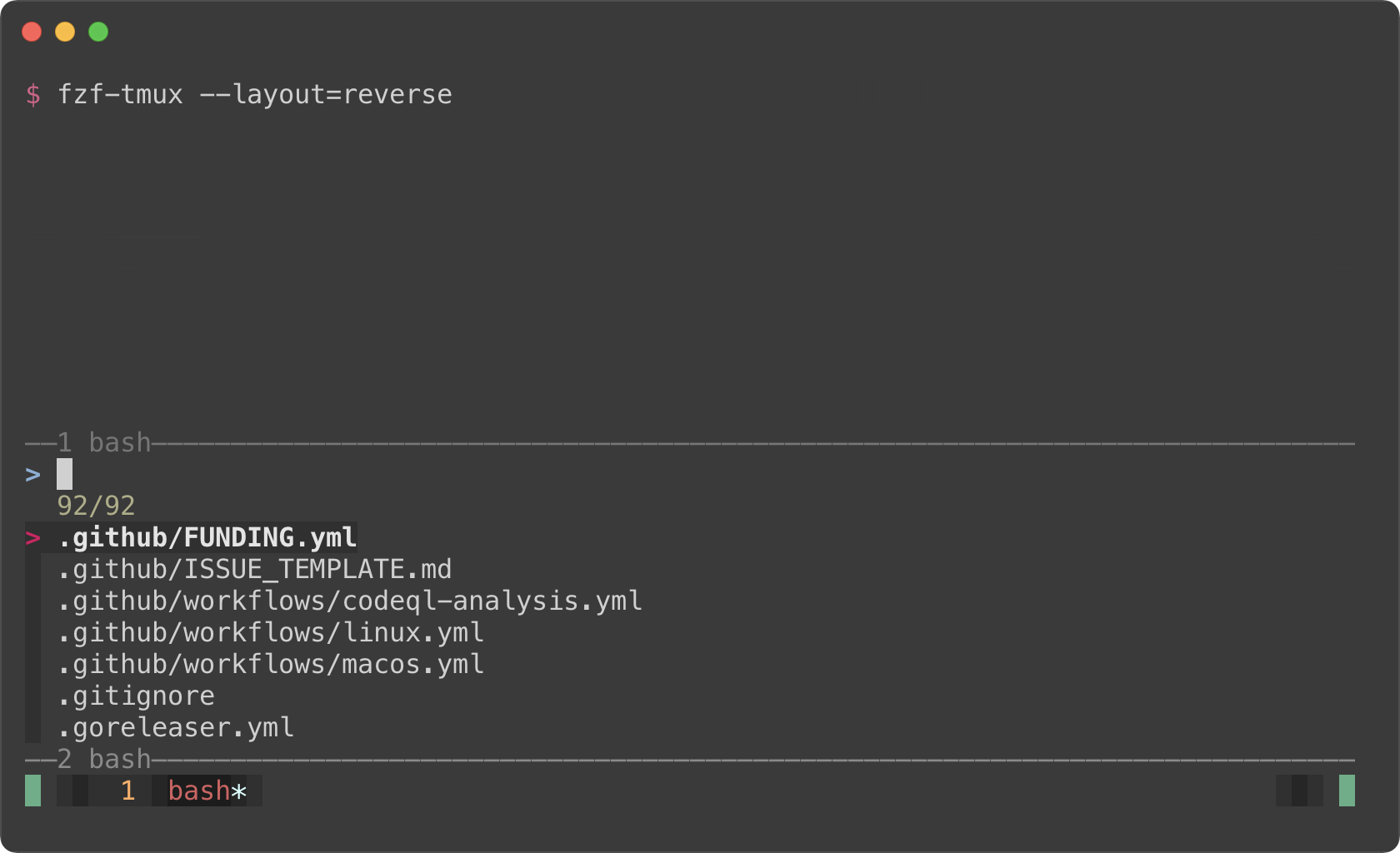
|
||||
|
||||
The limitation of `fzf-tmux` is that it only works when you're on tmux unlike
|
||||
`--height` option. But the advantage of it is that it's more flexible.
|
||||
(See `man fzf-tmux` for available options.)
|
||||
|
||||
```sh
|
||||
# On the right (50%)
|
||||
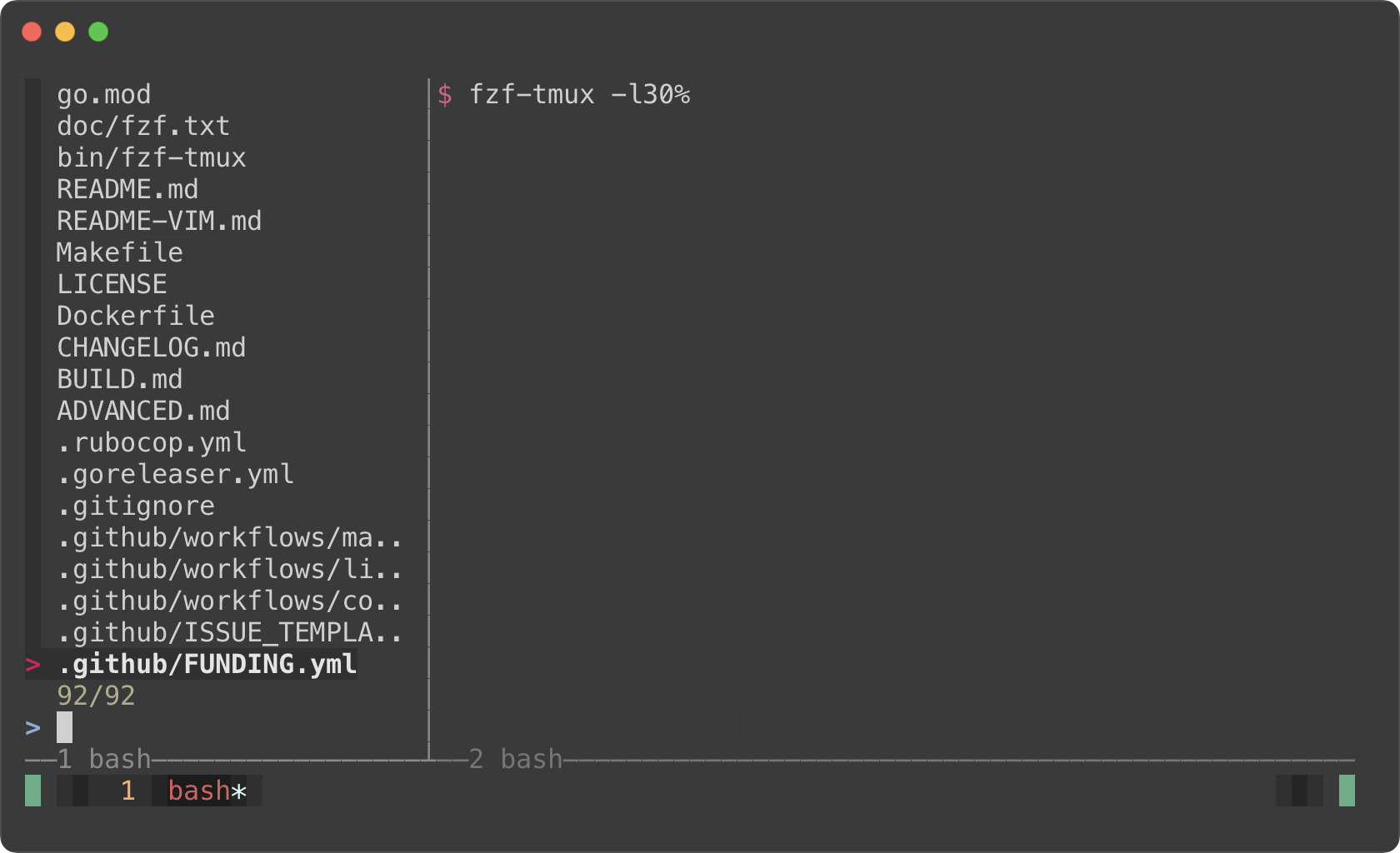
fzf-tmux -r
|
||||
|
||||
# On the left (30%)
|
||||
fzf-tmux -l30%
|
||||
|
||||
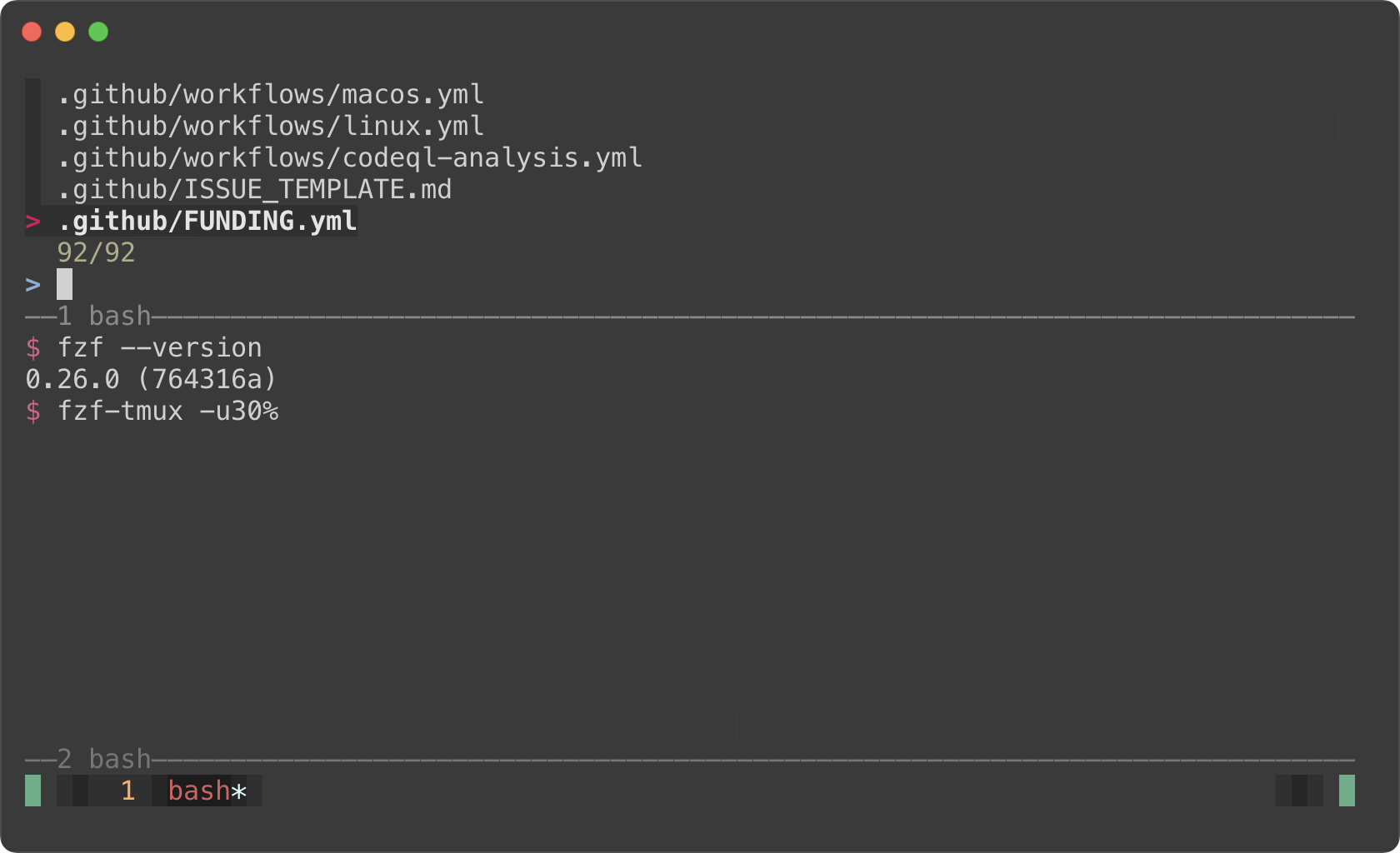
# Above the cursor
|
||||
fzf-tmux -u30%
|
||||
```
|
||||
|
||||
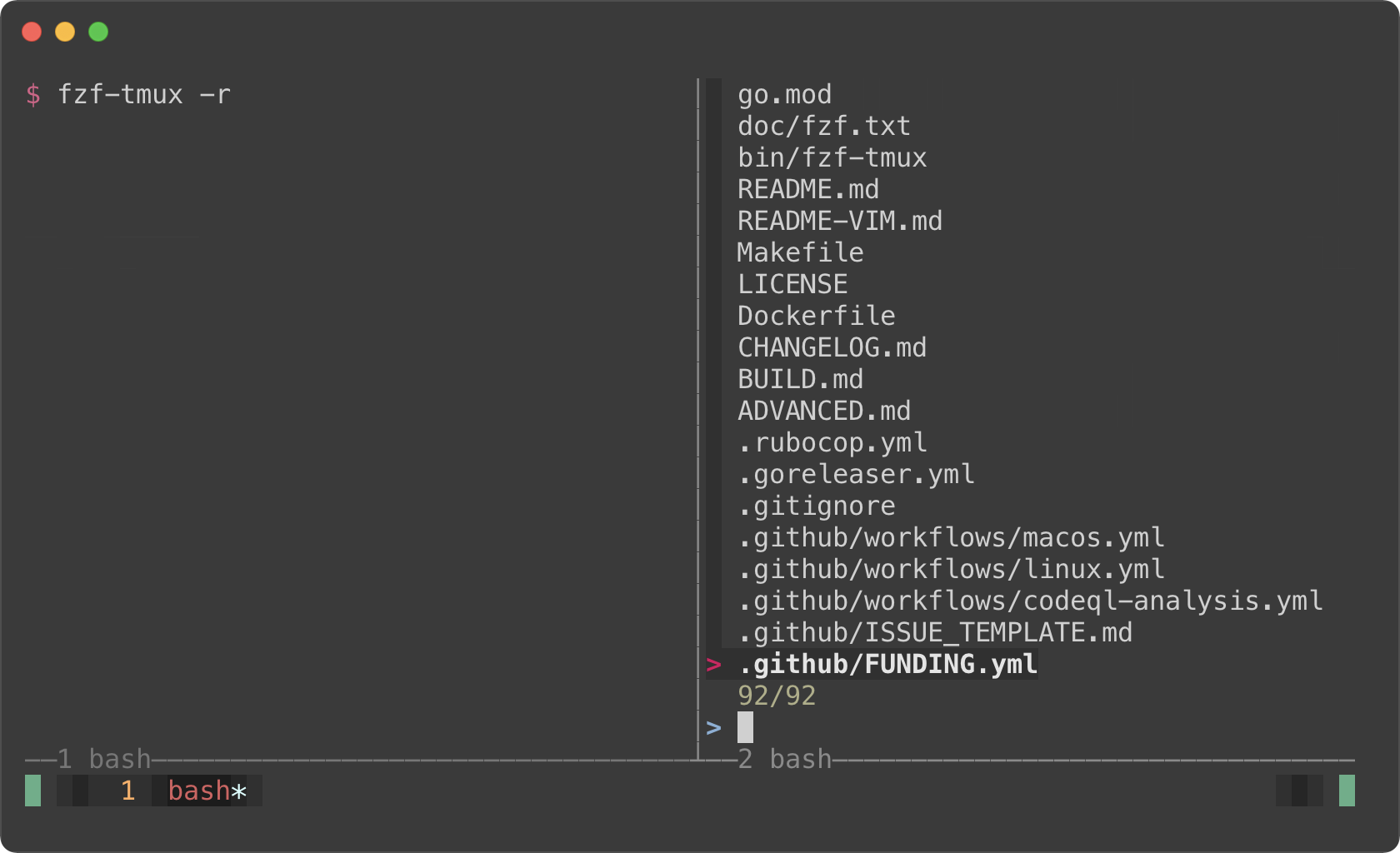
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
#### Popup window support
|
||||
|
||||
But here's the really cool part; tmux 3.2 added support for popup windows. So
|
||||
you can open fzf in a popup window, which is quite useful if you frequently
|
||||
use split panes.
|
||||
|
||||
```sh
|
||||
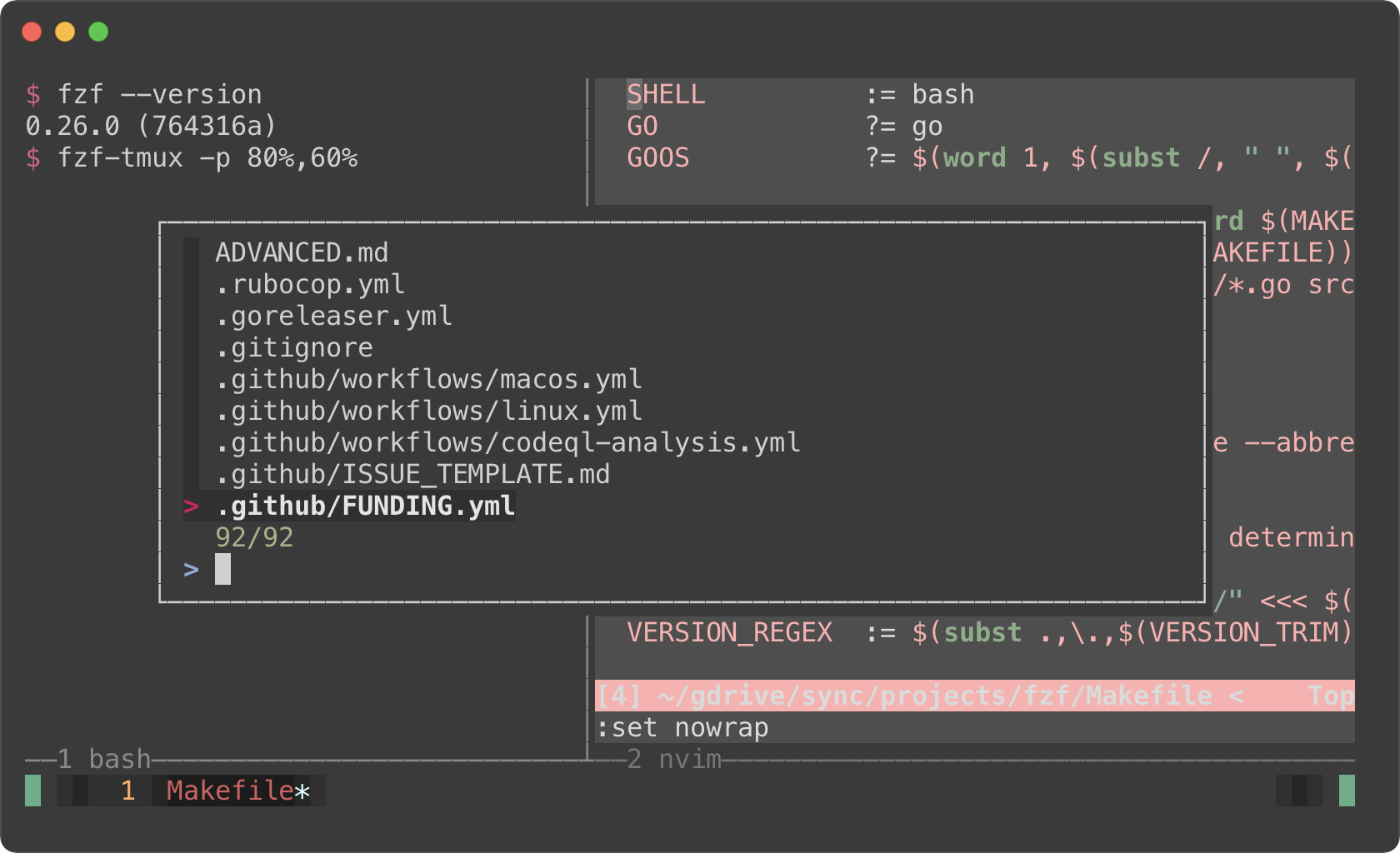
# Open tmux in a tmux popup window (default size: 50% of the screen)
|
||||
fzf-tmux -p
|
||||
|
||||
# 80% width, 60% height
|
||||
fzf-tmux -p 80%,60%
|
||||
```
|
||||
|
||||
|
||||
|
||||
> You might also want to check out my tmux plugins which support this popup
|
||||
> window layout.
|
||||
>
|
||||
> - https://github.com/junegunn/tmux-fzf-url
|
||||
> - https://github.com/junegunn/tmux-fzf-maccy
|
||||
|
||||
Dynamic reloading of the list
|
||||
-----------------------------
|
||||
|
||||
fzf can dynamically update the candidate list using an arbitrary program with
|
||||
`reload` bindings (The design document for `reload` can be found
|
||||
[here][reload]).
|
||||
|
||||
[reload]: https://github.com/junegunn/fzf/issues/1750
|
||||
|
||||
### Updating the list of processes by pressing CTRL-R
|
||||
|
||||
This example shows how you can set up a binding for dynamically updating the
|
||||
list without restarting fzf.
|
||||
|
||||
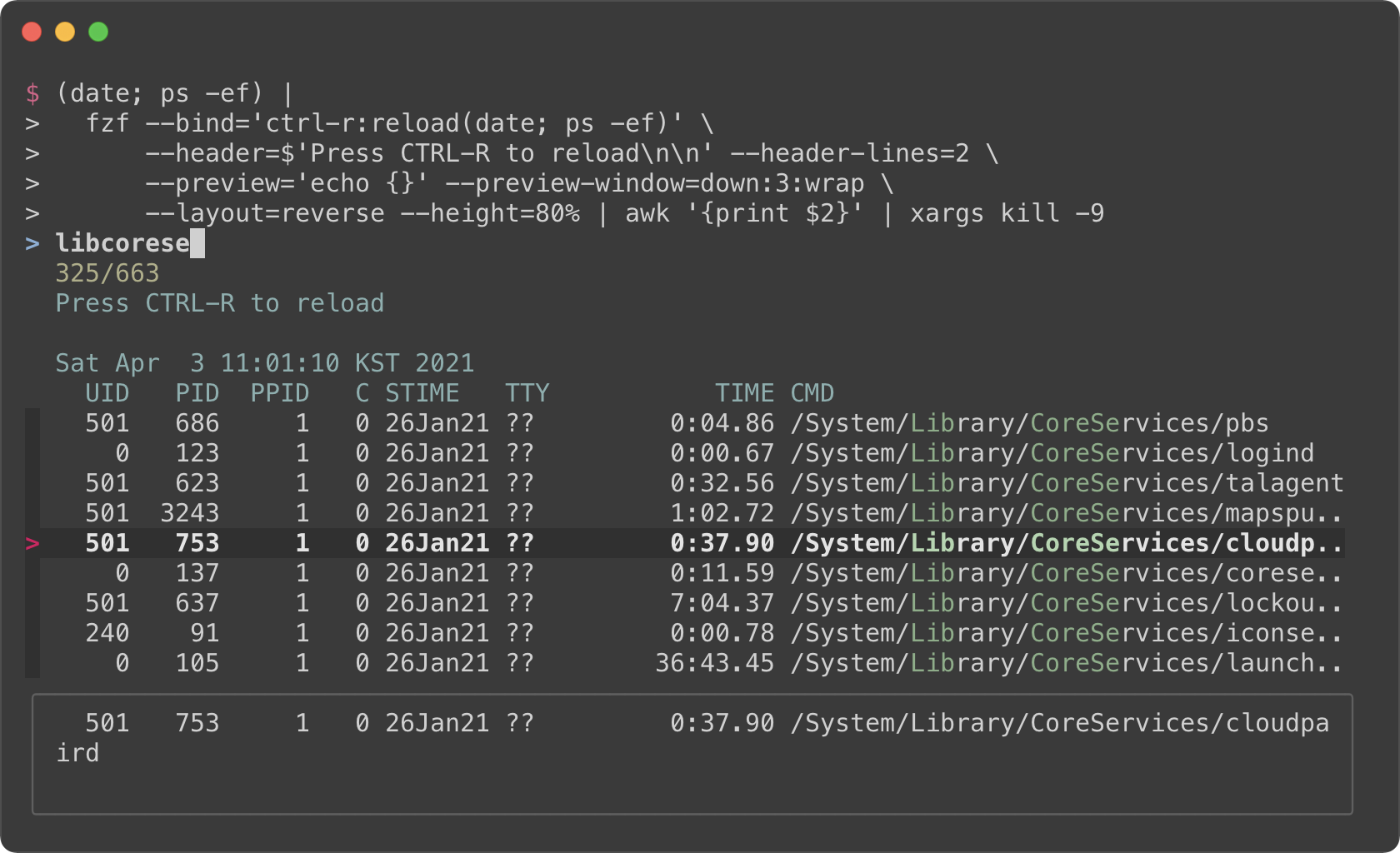
```sh
|
||||
(date; ps -ef) |
|
||||
fzf --bind='ctrl-r:reload(date; ps -ef)' \
|
||||
--header=$'Press CTRL-R to reload\n\n' --header-lines=2 \
|
||||
--preview='echo {}' --preview-window=down,3,wrap \
|
||||
--layout=reverse --height=80% | awk '{print $2}' | xargs kill -9
|
||||
```
|
||||
|
||||
|
||||
|
||||
- The initial command is `(date; ps -ef)`. It prints the current date and
|
||||
time, and the list of the processes.
|
||||
- With `--header` option, you can show any message as the fixed header.
|
||||
- To disallow selecting the first two lines (`date` and `ps` header), we use
|
||||
`--header-lines=2` option.
|
||||
- `--bind='ctrl-r:reload(date; ps -ef)'` binds CTRL-R to `reload` action that
|
||||
runs `date; ps -ef`, so we can update the list of the processes by pressing
|
||||
CTRL-R.
|
||||
- We use simple `echo {}` preview option, so we can see the entire line on the
|
||||
preview window below even if it's too long
|
||||
|
||||
### Toggling between data sources
|
||||
|
||||
You're not limited to just one reload binding. Set up multiple bindings so
|
||||
you can switch between data sources.
|
||||
|
||||
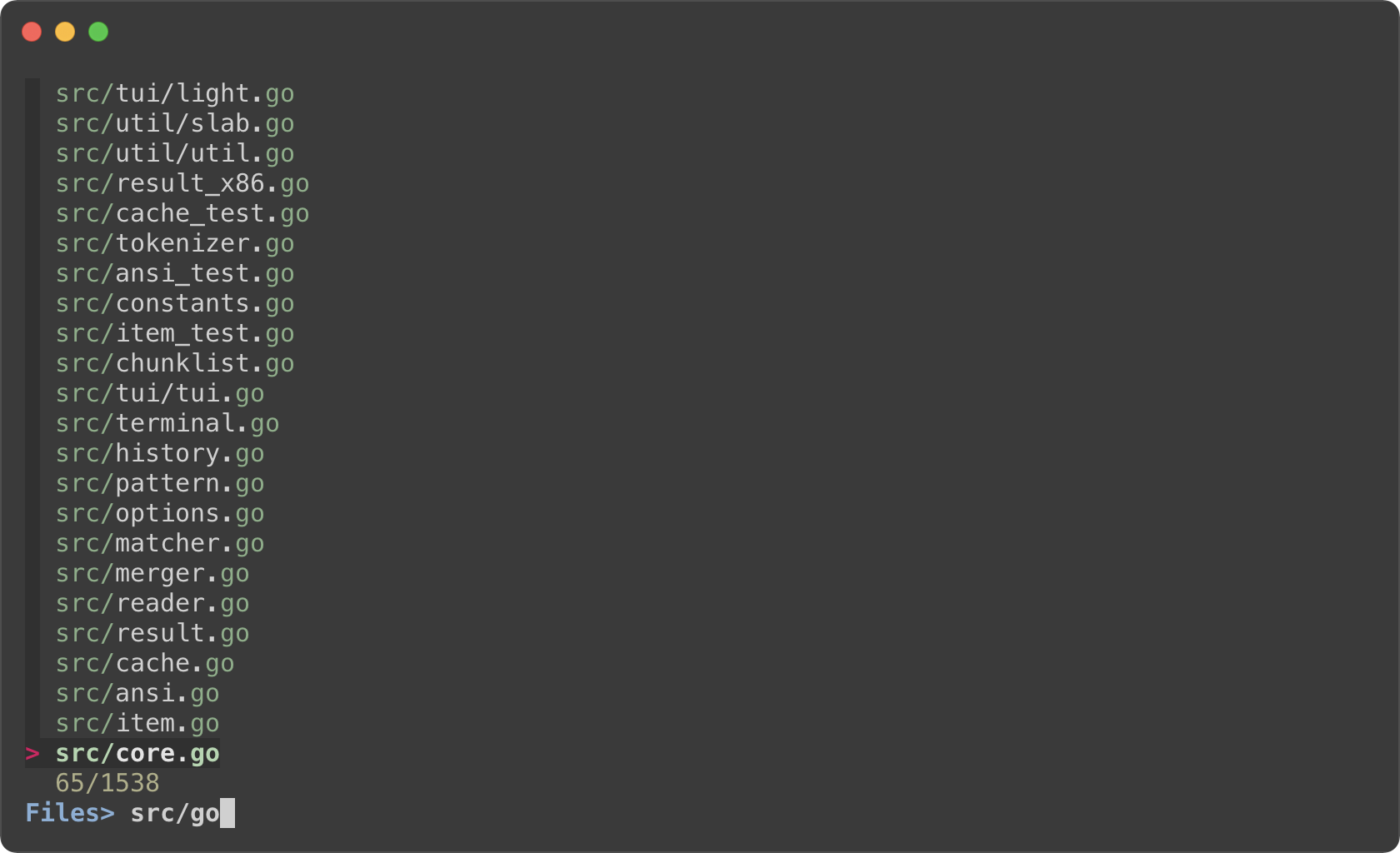
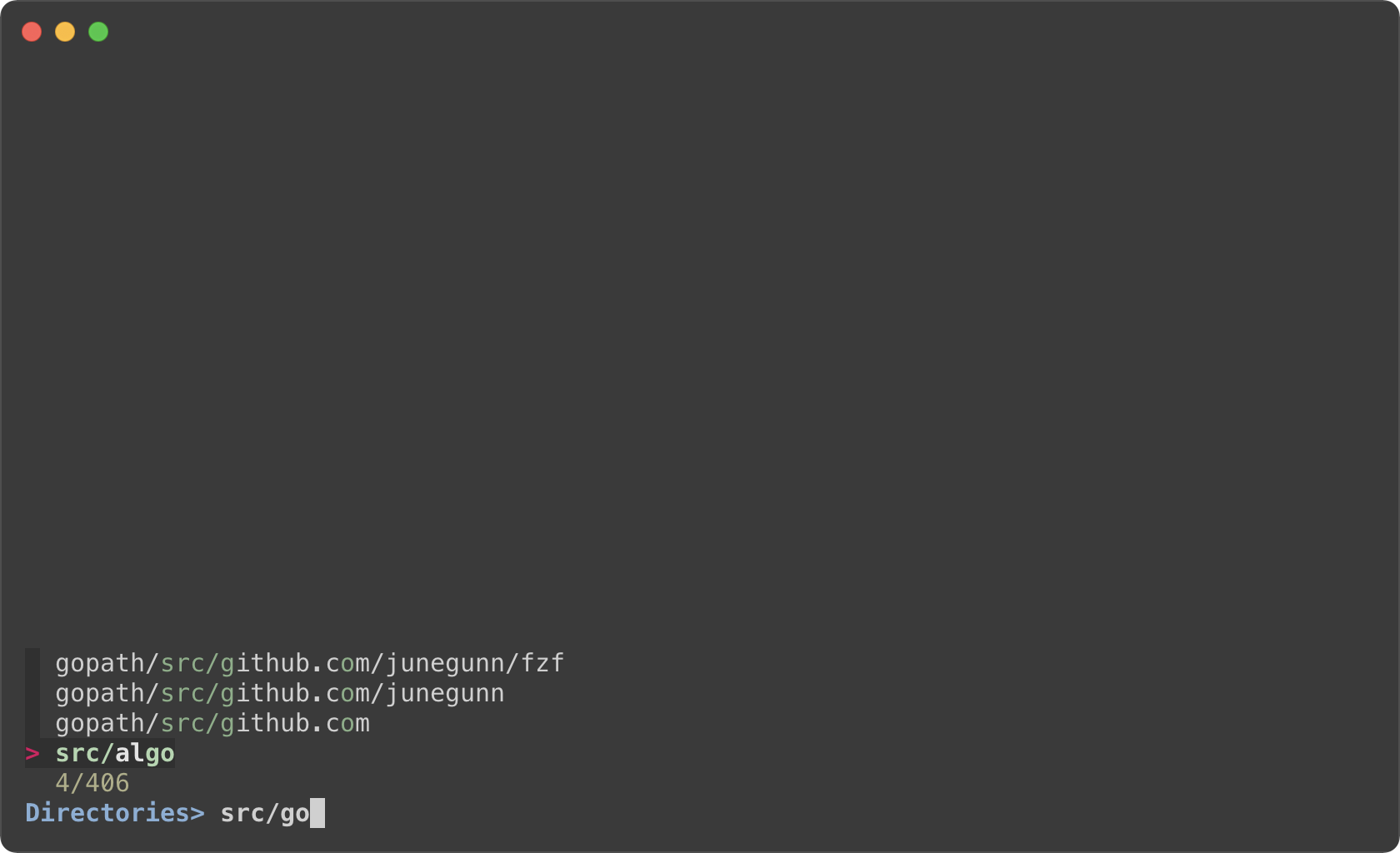
```sh
|
||||
find * | fzf --prompt 'All> ' \
|
||||
--header 'CTRL-D: Directories / CTRL-F: Files' \
|
||||
--bind 'ctrl-d:change-prompt(Directories> )+reload(find * -type d)' \
|
||||
--bind 'ctrl-f:change-prompt(Files> )+reload(find * -type f)'
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Ripgrep integration
|
||||
-------------------
|
||||
|
||||
### Using fzf as the secondary filter
|
||||
|
||||
* Requires [bat][bat]
|
||||
* Requires [Ripgrep][rg]
|
||||
|
||||
[bat]: https://github.com/sharkdp/bat
|
||||
[rg]: https://github.com/BurntSushi/ripgrep
|
||||
|
||||
fzf is pretty fast for filtering a list that you will rarely have to think
|
||||
about its performance. But it is not the right tool for searching for text
|
||||
inside many large files, and in that case you should definitely use something
|
||||
like [Ripgrep][rg].
|
||||
|
||||
In the next example, Ripgrep is the primary filter that searches for the given
|
||||
text in files, and fzf is used as the secondary fuzzy filter that adds
|
||||
interactivity to the workflow. And we use [bat][bat] to show the matching line in
|
||||
the preview window.
|
||||
|
||||
This is a bash script and it will not run as expected on other non-compliant
|
||||
shells. To avoid the compatibility issue, let's save this snippet as a script
|
||||
file called `rfv`.
|
||||
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# 1. Search for text in files using Ripgrep
|
||||
# 2. Interactively narrow down the list using fzf
|
||||
# 3. Open the file in Vim
|
||||
IFS=: read -ra selected < <(
|
||||
rg --color=always --line-number --no-heading --smart-case "${*:-}" |
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
And run it with an initial query string.
|
||||
|
||||
```sh
|
||||
# Make the script executable
|
||||
chmod +x rfv
|
||||
|
||||
# Run it with the initial query "algo"
|
||||
./rfv algo
|
||||
```
|
||||
|
||||
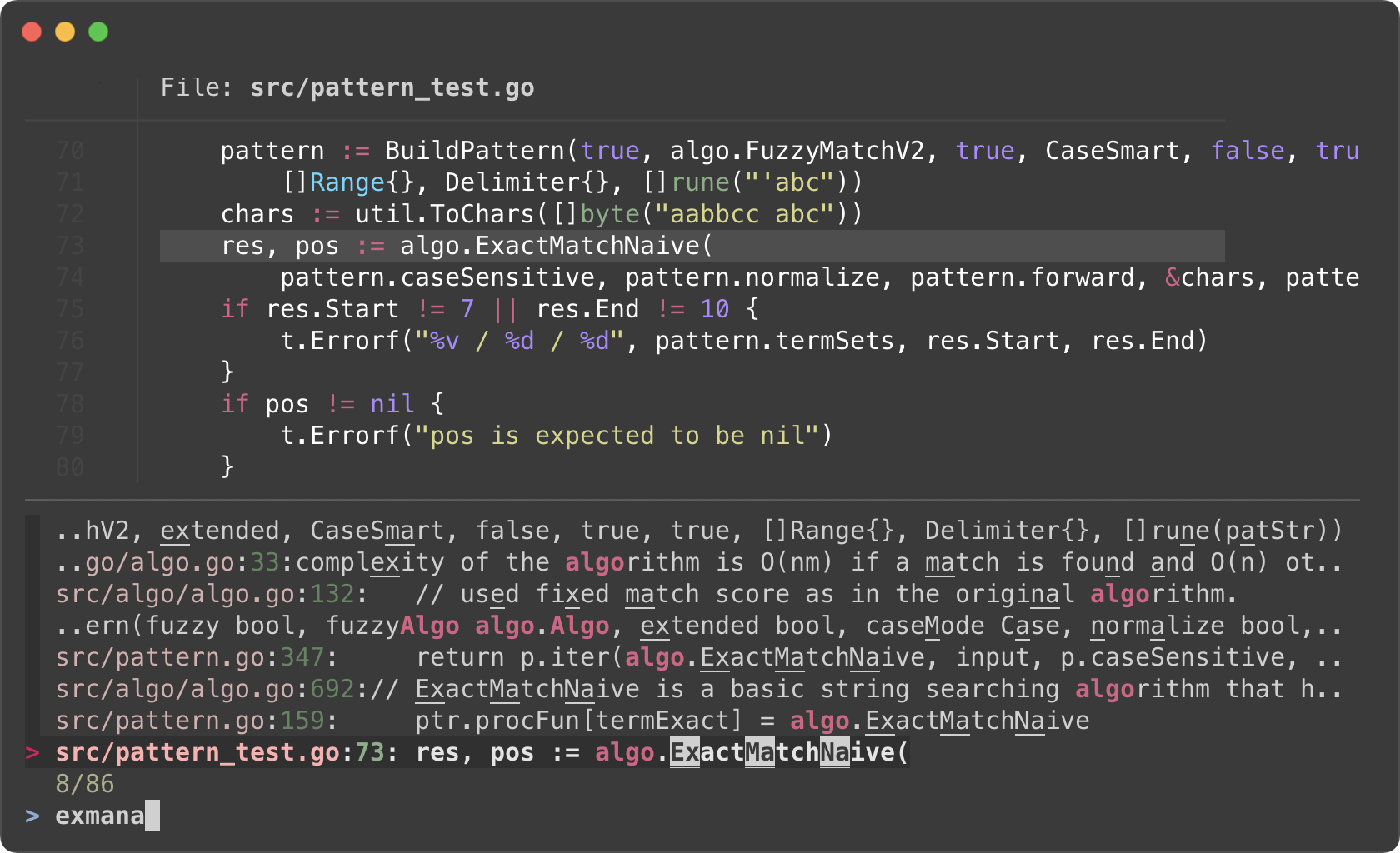
> Ripgrep will perform the initial search and list all the lines that contain
|
||||
`algo`. Then we further narrow down the list on fzf.
|
||||
|
||||
|
||||
|
||||
I know it's a lot to digest, let's try to break down the code.
|
||||
|
||||
- Ripgrep prints the matching lines in the following format
|
||||
```
|
||||
man/man1/fzf.1:54:.BI "--algo=" TYPE
|
||||
man/man1/fzf.1:55:Fuzzy matching algorithm (default: v2)
|
||||
man/man1/fzf.1:58:.BR v2 " Optimal scoring algorithm (quality)"
|
||||
src/pattern_test.go:7: "github.com/junegunn/fzf/src/algo"
|
||||
```
|
||||
The first token delimited by `:` is the file path, and the second token is
|
||||
the line number of the matching line. They respectively correspond to `{1}`
|
||||
and `{2}` in the preview command.
|
||||
- `--preview 'bat --color=always {1} --highlight-line {2}'`
|
||||
- As we run `rg` with `--color=always` option, we should tell fzf to parse
|
||||
ANSI color codes in the input by setting `--ansi`.
|
||||
- We customize how fzf colors various text elements using `--color` option.
|
||||
`-1` tells fzf to keep the original color from the input. See `man fzf` for
|
||||
available color options.
|
||||
- The value of `--preview-window` option consists of 5 components delimited
|
||||
by `,`
|
||||
1. `up` — Position of the preview window
|
||||
1. `60%` — Size of the preview window
|
||||
1. `border-bottom` — Preview window border only on the bottom side
|
||||
1. `+{2}+3/3` — Scroll offset of the preview contents
|
||||
1. `~3` — Fixed header
|
||||
- Let's break down the latter two. We want to display the bat output in the
|
||||
preview window with a certain scroll offset so that the matching line is
|
||||
positioned near the center of the preview window.
|
||||
- `+{2}` — The base offset is extracted from the second token
|
||||
- `+3` — We add 3 lines to the base offset to compensate for the header
|
||||
part of `bat` output
|
||||
- ```
|
||||
───────┬──────────────────────────────────────────────────────────
|
||||
│ File: CHANGELOG.md
|
||||
───────┼──────────────────────────────────────────────────────────
|
||||
1 │ CHANGELOG
|
||||
2 │ =========
|
||||
3 │
|
||||
4 │ 0.26.0
|
||||
5 │ ------
|
||||
```
|
||||
- `/3` adjusts the offset so that the matching line is shown at a third
|
||||
position in the window
|
||||
- `~3` makes the top three lines fixed header so that they are always
|
||||
visible regardless of the scroll offset
|
||||
- Once we selected a line, we open the file with `vim` (`vim
|
||||
"${selected[0]}"`) and move the cursor to the line (`+${selected[1]}`).
|
||||
|
||||
### Using fzf as interative Ripgrep launcher
|
||||
|
||||
We have learned that we can bind `reload` action to a key (e.g.
|
||||
`--bind=ctrl-r:execute(ps -ef)`). In the next example, we are going to **bind
|
||||
`reload` action to `change` event** so that whenever the user *changes* the
|
||||
query string on fzf, `reload` action is triggered.
|
||||
|
||||
Here is a variation of the above `rfv` script. fzf will restart Ripgrep every
|
||||
time the user updates the query string on fzf. Searching and filtering is
|
||||
completely done by Ripgrep, and fzf merely provides the interactive interface.
|
||||
So we lose the "fuzziness", but the performance will be better on larger
|
||||
projects, and it will free up memory as you narrow down the results.
|
||||
|
||||
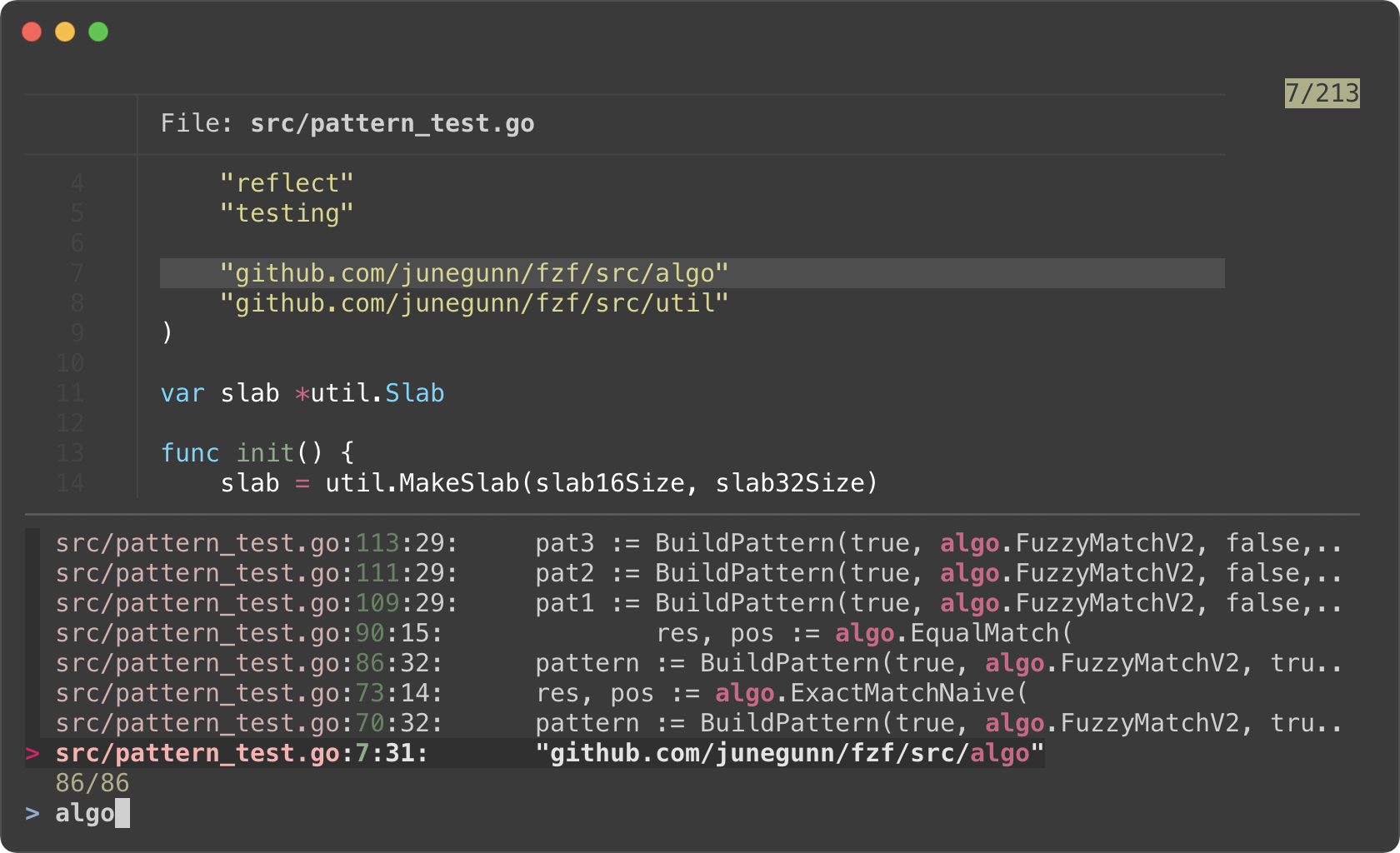
```bash
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# 1. Search for text in files using Ripgrep
|
||||
# 2. Interactively restart Ripgrep with reload action
|
||||
# 3. Open the file in Vim
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
IFS=: read -ra selected < <(
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX $(printf %q "$INITIAL_QUERY")" \
|
||||
fzf --ansi \
|
||||
--disabled --query "$INITIAL_QUERY" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
|
||||
|
||||
- Instead of starting fzf in `rg ... | fzf` form, we start fzf without an
|
||||
explicit input, but with a custom `FZF_DEFAULT_COMMAND` variable. This way
|
||||
fzf can kill the initial Ripgrep process it starts with the initial query.
|
||||
Otherwise, the initial Ripgrep process will keep consuming system resources
|
||||
even after `reload` is triggered.
|
||||
- Filtering is no longer a responsibility of fzf; hence `--disabled`
|
||||
- `{q}` in the reload command evaluates to the query string on fzf prompt.
|
||||
- `sleep 0.1` in the reload command is for "debouncing". This small delay will
|
||||
reduce the number of intermediate Ripgrep processes while we're typing in
|
||||
a query.
|
||||
|
||||
### Switching to fzf-only search mode
|
||||
|
||||
*(Requires fzf 0.27.1 or above)*
|
||||
|
||||
In the previous example, we lost fuzzy matching capability as we completely
|
||||
delegated search functionality to Ripgrep. But we can dynamically switch to
|
||||
fzf-only search mode by *"unbinding"* `reload` action from `change` event.
|
||||
|
||||
```sh
|
||||
#!/usr/bin/env bash
|
||||
|
||||
# Two-phase filtering with Ripgrep and fzf
|
||||
#
|
||||
# 1. Search for text in files using Ripgrep
|
||||
# 2. Interactively restart Ripgrep with reload action
|
||||
# * Press alt-enter to switch to fzf-only filtering
|
||||
# 3. Open the file in Vim
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
INITIAL_QUERY="${*:-}"
|
||||
IFS=: read -ra selected < <(
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX $(printf %q "$INITIAL_QUERY")" \
|
||||
fzf --ansi \
|
||||
--color "hl:-1:underline,hl+:-1:underline:reverse" \
|
||||
--disabled --query "$INITIAL_QUERY" \
|
||||
--bind "change:reload:sleep 0.1; $RG_PREFIX {q} || true" \
|
||||
--bind "alt-enter:unbind(change,alt-enter)+change-prompt(2. fzf> )+enable-search+clear-query" \
|
||||
--prompt '1. ripgrep> ' \
|
||||
--delimiter : \
|
||||
--preview 'bat --color=always {1} --highlight-line {2}' \
|
||||
--preview-window 'up,60%,border-bottom,+{2}+3/3,~3'
|
||||
)
|
||||
[ -n "${selected[0]}" ] && vim "${selected[0]}" "+${selected[1]}"
|
||||
```
|
||||
|
||||
* Phase 1. Filtering with Ripgrep
|
||||
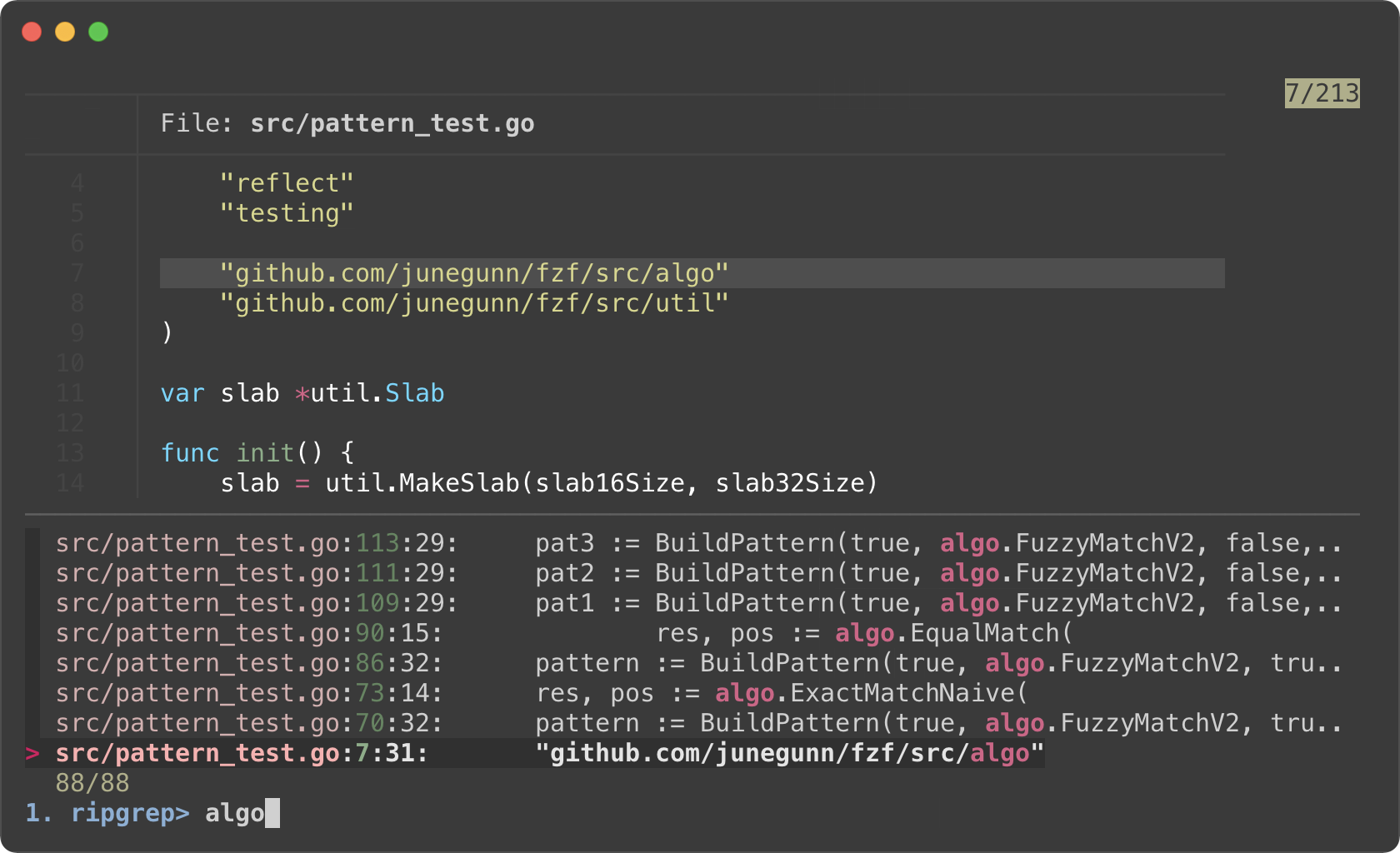
|
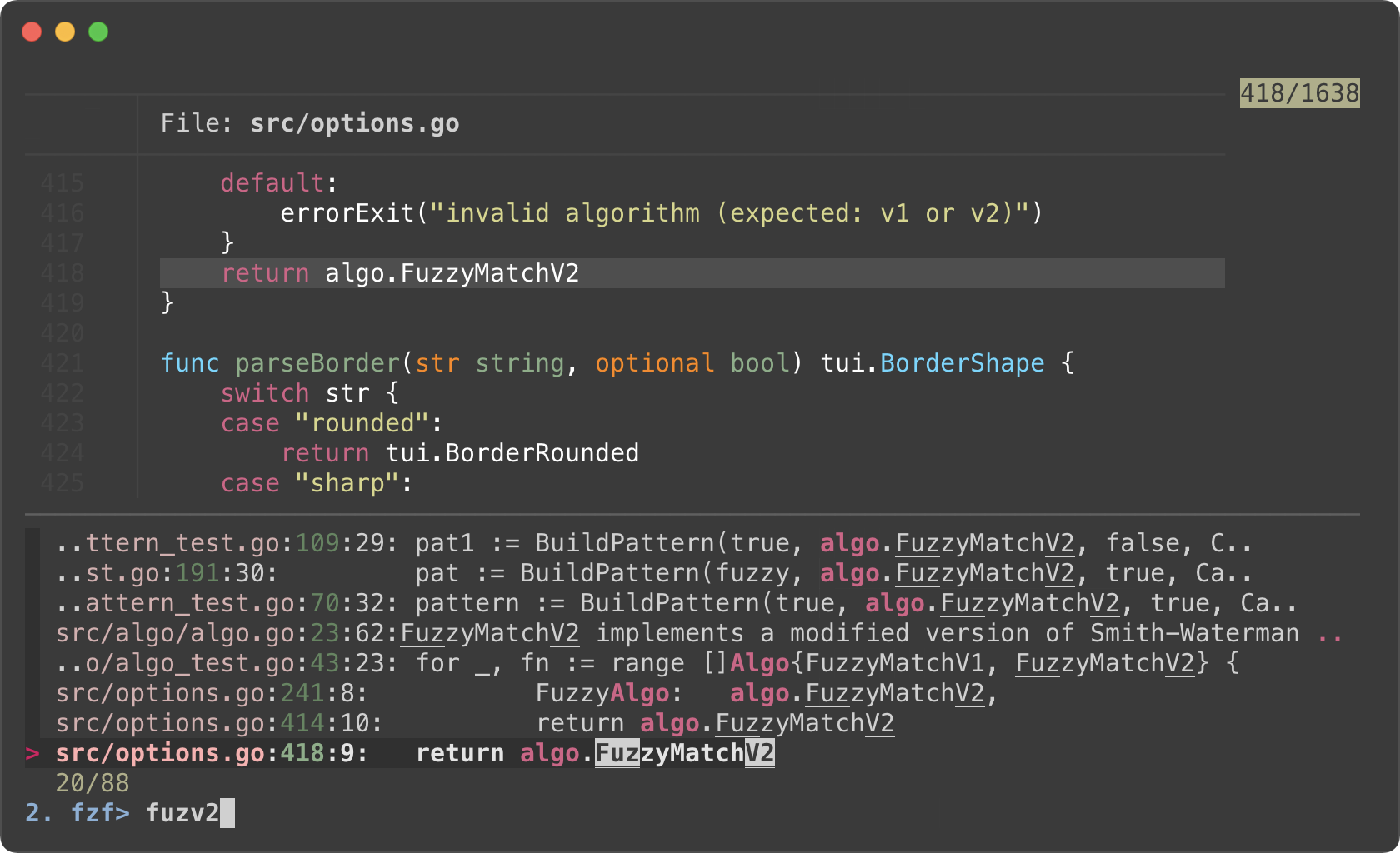
||||
* Phase 2. Filtering with fzf
|
||||
|
||||
|
||||
- We added `--prompt` option to show that fzf is initially running in "Ripgrep
|
||||
launcher mode".
|
||||
- We added `alt-enter` binding that
|
||||
1. unbinds `change` event, so Ripgrep is no longer restarted on key press
|
||||
2. changes the prompt to `2. fzf>`
|
||||
3. enables search functionality of fzf
|
||||
4. clears the current query string that was used to start Ripgrep process
|
||||
5. and unbinds `alt-enter` itself as this is a one-off event
|
||||
- We reverted `--color` option for customizing how the matching chunks are
|
||||
displayed in the second phase
|
||||
|
||||
Log tailing
|
||||
-----------
|
||||
|
||||
fzf can run long-running preview commands and render partial results before
|
||||
completion. And when you specify `follow` flag in `--preview-window` option,
|
||||
fzf will "`tail -f`" the result, automatically scrolling to the bottom.
|
||||
|
||||
```bash
|
||||
# With "follow", preview window will automatically scroll to the bottom.
|
||||
# "\033[2J" is an ANSI escape sequence for clearing the screen.
|
||||
# When fzf reads this code it clears the previous preview contents.
|
||||
fzf --preview-window follow --preview 'for i in $(seq 100000); do
|
||||
echo "$i"
|
||||
sleep 0.01
|
||||
(( i % 300 == 0 )) && printf "\033[2J"
|
||||
done'
|
||||
```
|
||||
|
||||
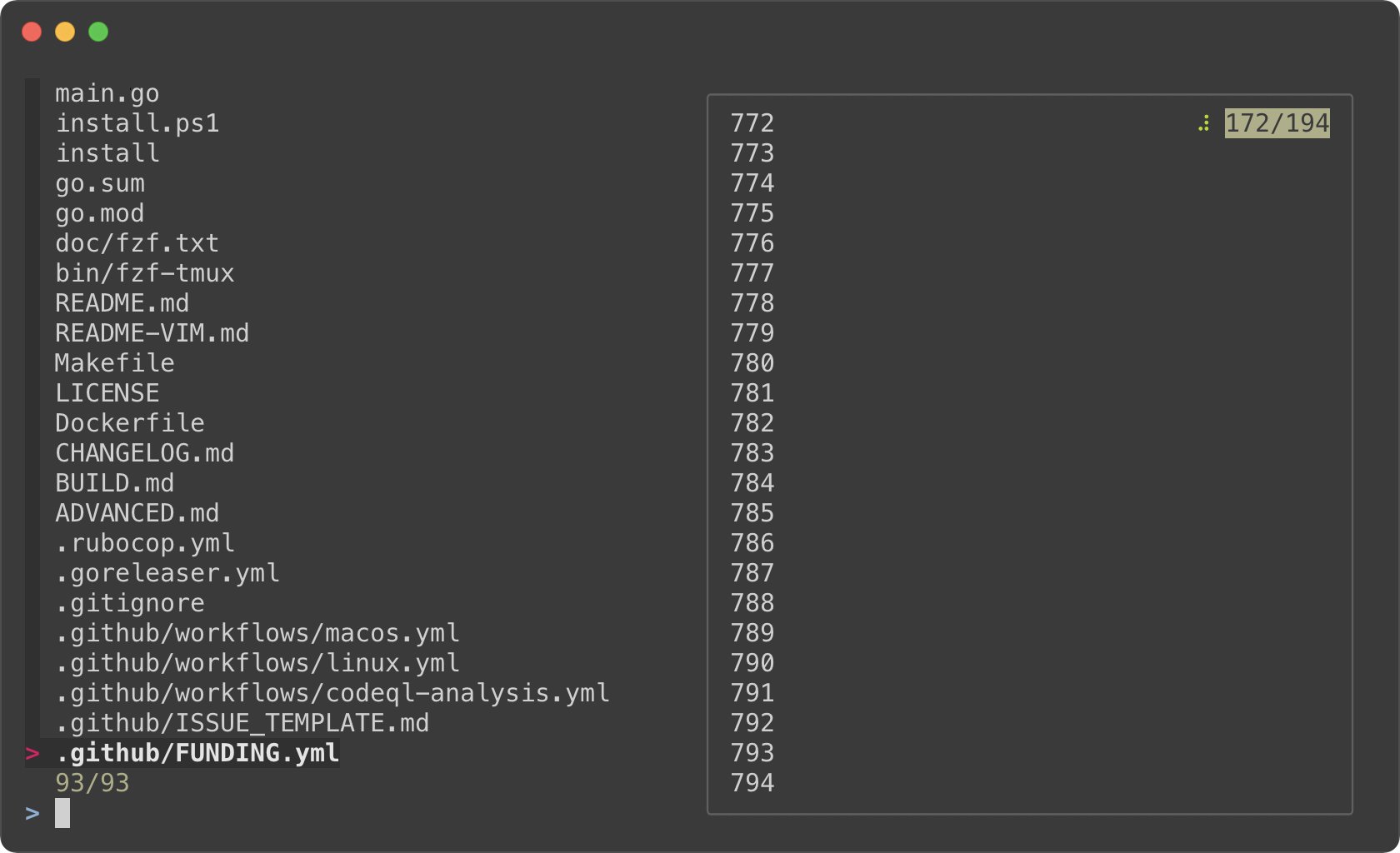
|
||||
|
||||
Admittedly, that was a silly example. Here's a practical one for browsing
|
||||
Kubernetes pods.
|
||||
|
||||
```bash
|
||||
#!/usr/bin/env bash
|
||||
|
||||
read -ra tokens < <(
|
||||
kubectl get pods --all-namespaces |
|
||||
fzf --info=inline --layout=reverse --header-lines=1 --border \
|
||||
--prompt "$(kubectl config current-context | sed 's/-context$//')> " \
|
||||
--header $'Press CTRL-O to open log in editor\n\n' \
|
||||
--bind ctrl-/:toggle-preview \
|
||||
--bind 'ctrl-o:execute:${EDITOR:-vim} <(kubectl logs --namespace {1} {2}) > /dev/tty' \
|
||||
--preview-window up,follow \
|
||||
--preview 'kubectl logs --follow --tail=100000 --namespace {1} {2}' "$@"
|
||||
)
|
||||
[ ${#tokens} -gt 1 ] &&
|
||||
kubectl exec -it --namespace "${tokens[0]}" "${tokens[1]}" -- bash
|
||||
```
|
||||
|
||||
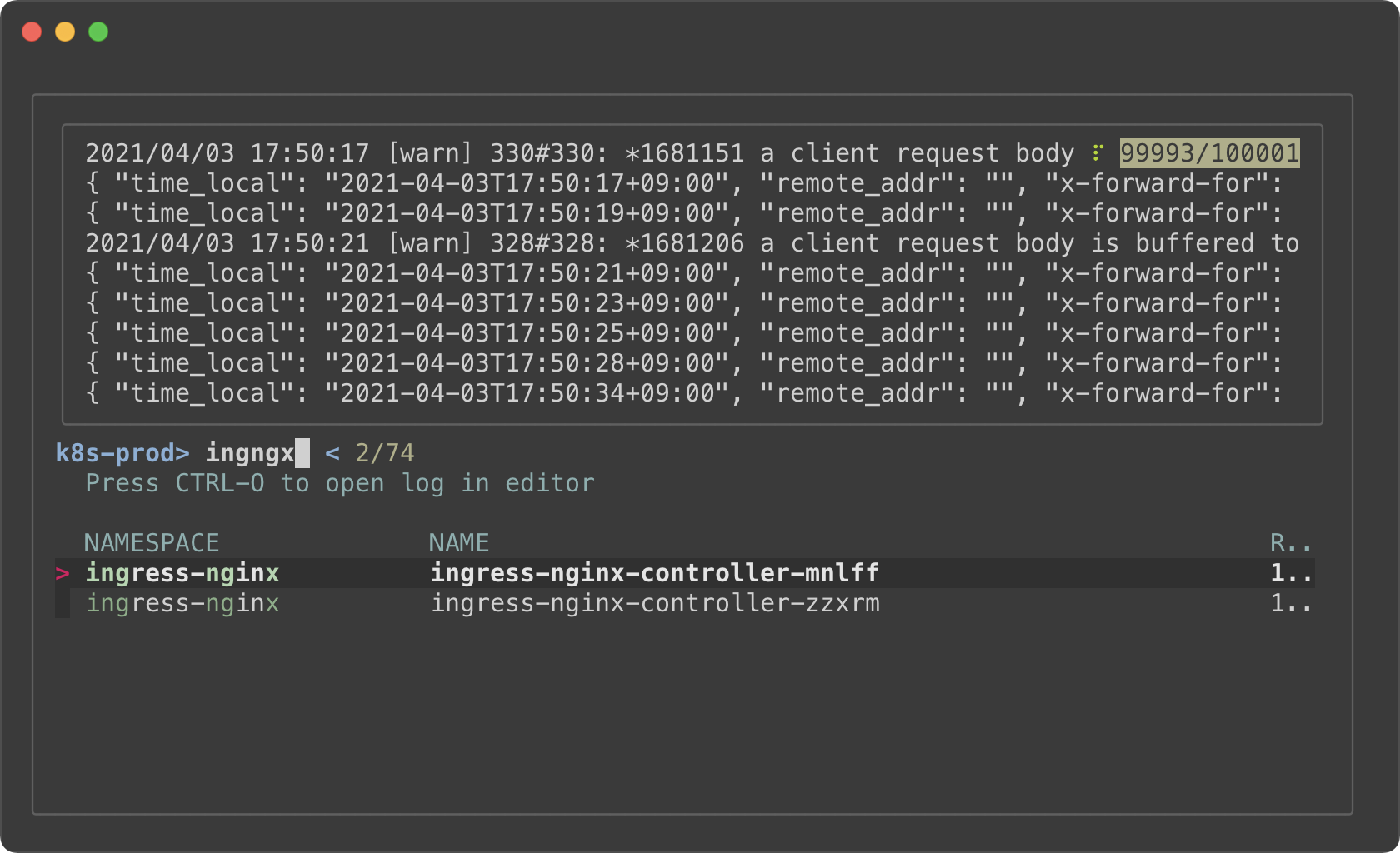
|
||||
|
||||
- The preview window will *"log tail"* the pod
|
||||
- Holding on to a large amount of log will consume a lot of memory. So we
|
||||
limited the initial log amount with `--tail=100000`.
|
||||
- With `execute` binding, you can press CTRL-O to open the log in your editor
|
||||
without leaving fzf
|
||||
- Select a pod (with an enter key) to `kubectl exec` into it
|
||||
|
||||
Key bindings for git objects
|
||||
----------------------------
|
||||
|
||||
I have [blogged](https://junegunn.kr/2016/07/fzf-git) about my fzf+git key
|
||||
bindings a few years ago. I'm going to show them here again, because they are
|
||||
seriously useful.
|
||||
|
||||
### Files listed in `git status`
|
||||
|
||||
<kbd>CTRL-G</kbd><kbd>CTRL-F</kbd>
|
||||
|
||||
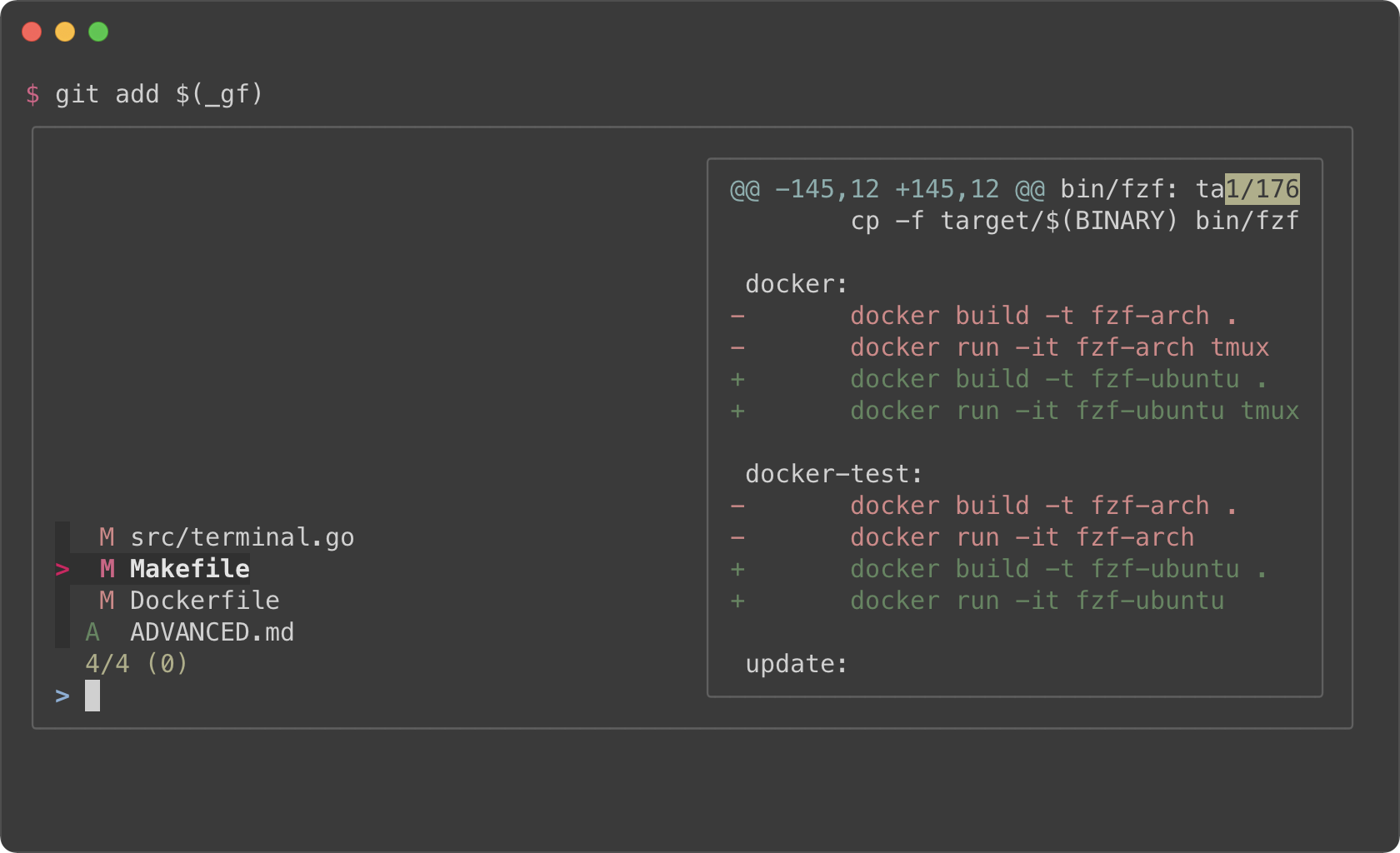
|
||||
|
||||
### Branches
|
||||
|
||||
<kbd>CTRL-G</kbd><kbd>CTRL-B</kbd>
|
||||
|
||||
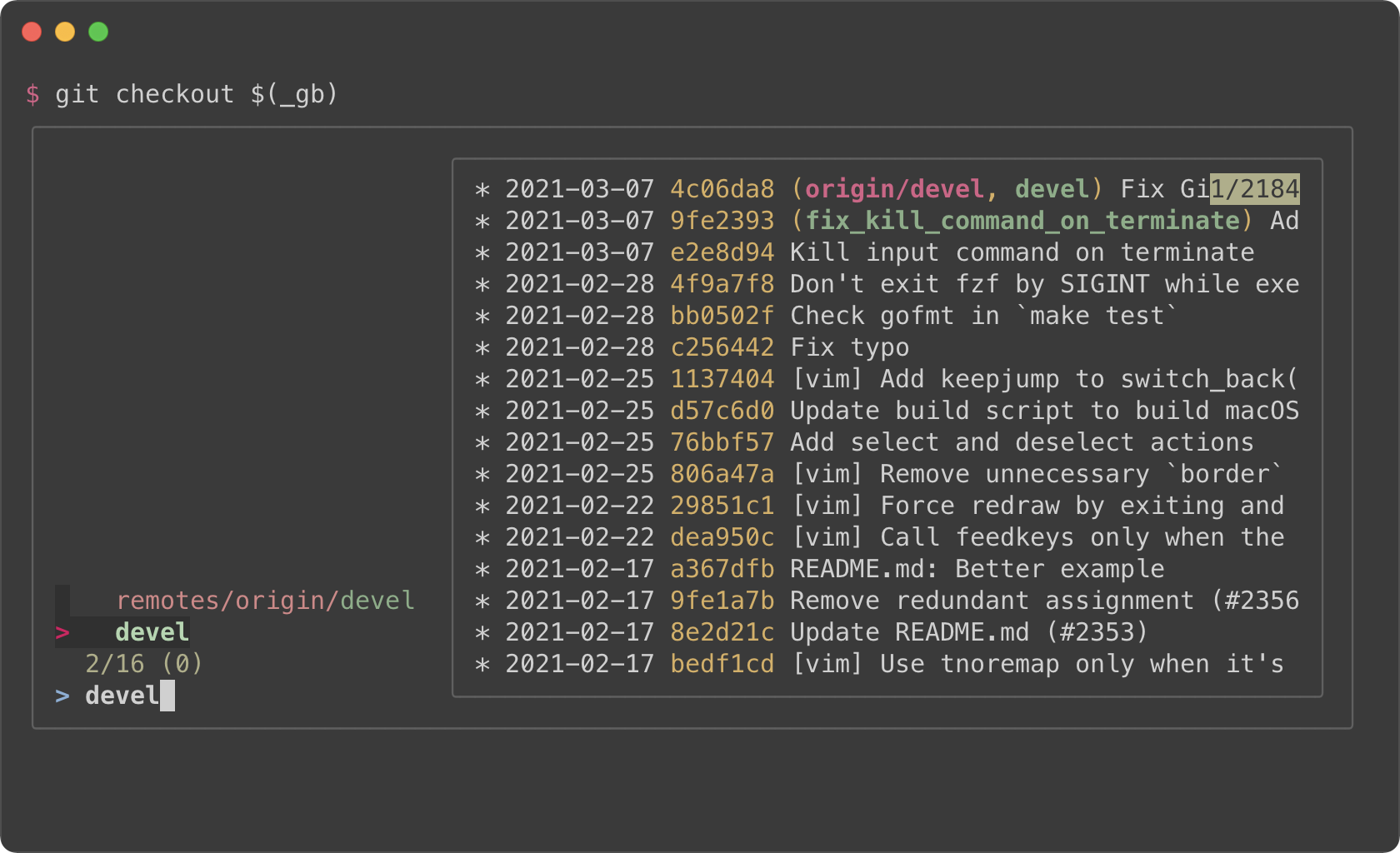
|
||||
|
||||
### Commit hashes
|
||||
|
||||
<kbd>CTRL-G</kbd><kbd>CTRL-H</kbd>
|
||||
|
||||
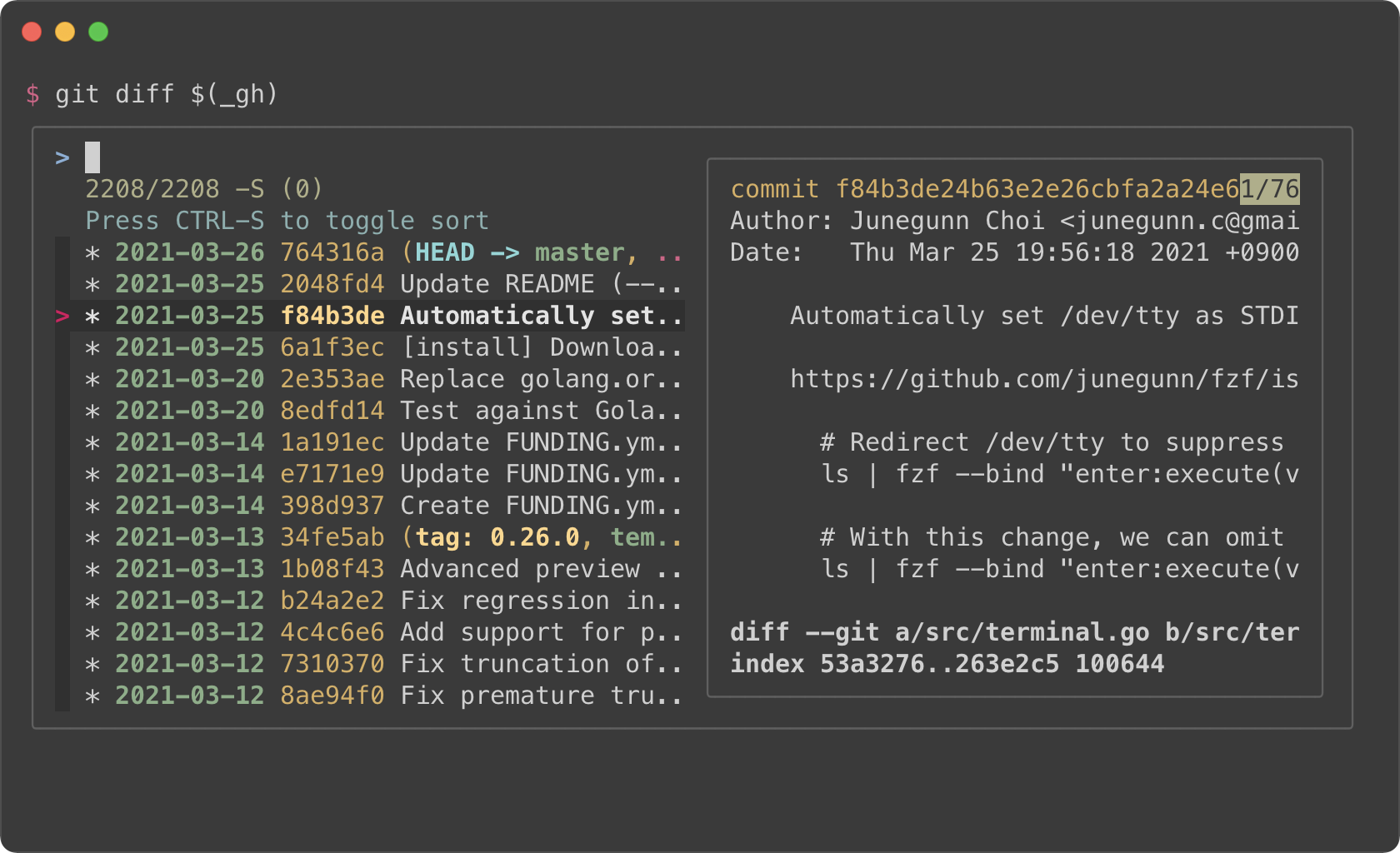
|
||||
|
||||
|
||||
The full source code can be found [here](https://gist.github.com/junegunn/8b572b8d4b5eddd8b85e5f4d40f17236).
|
||||
|
||||
Color themes
|
||||
------------
|
||||
|
||||
You can customize how fzf colors the text elements with `--color` option. Here
|
||||
are a few color themes. Note that you need a terminal emulator that can
|
||||
display 24-bit colors.
|
||||
|
||||
```sh
|
||||
# junegunn/seoul256.vim (dark)
|
||||
export FZF_DEFAULT_OPTS='--color=bg+:#3F3F3F,bg:#4B4B4B,border:#6B6B6B,spinner:#98BC99,hl:#719872,fg:#D9D9D9,header:#719872,info:#BDBB72,pointer:#E12672,marker:#E17899,fg+:#D9D9D9,preview-bg:#3F3F3F,prompt:#98BEDE,hl+:#98BC99'
|
||||
```
|
||||
|
||||
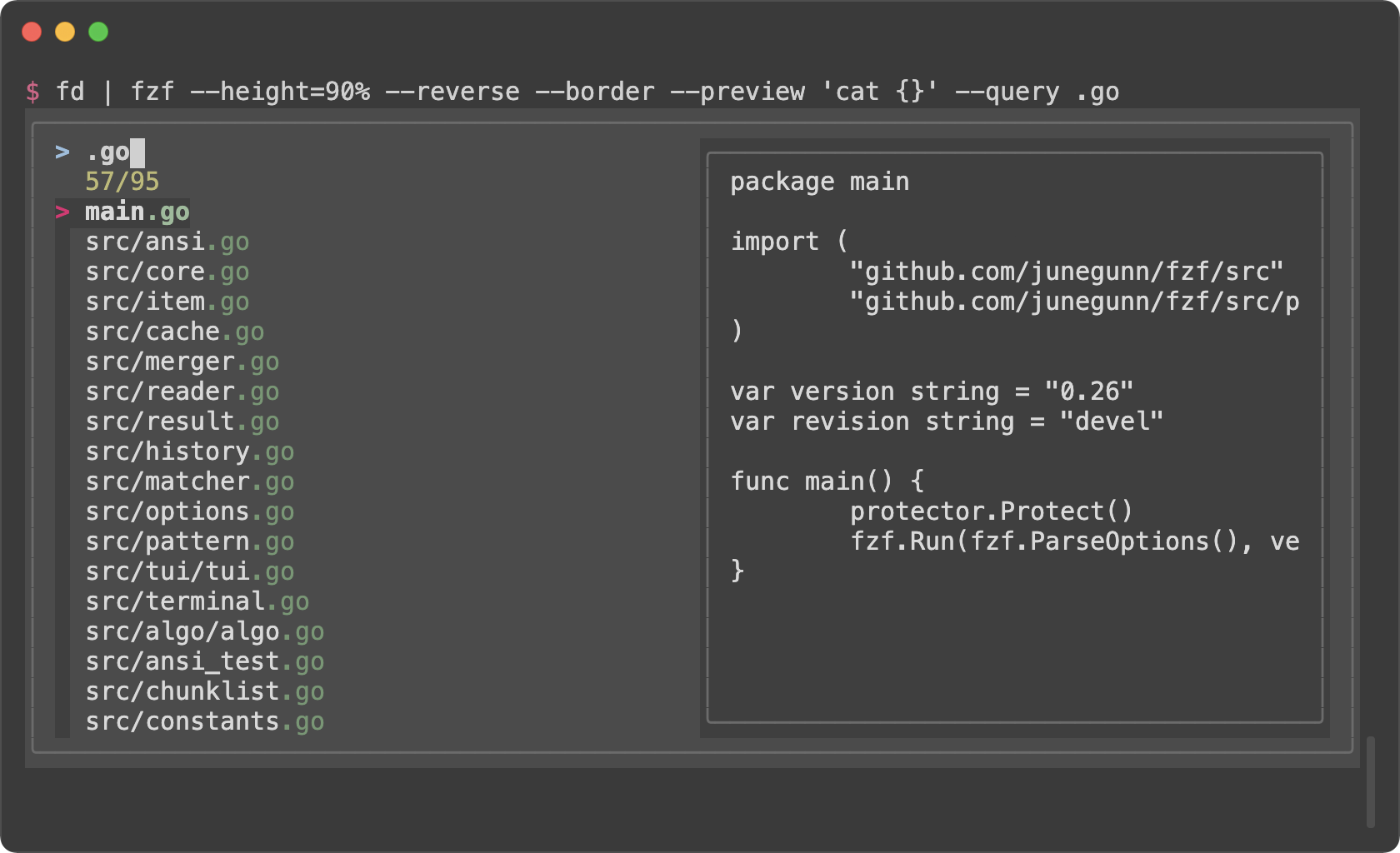
|
||||
|
||||
```sh
|
||||
# junegunn/seoul256.vim (light)
|
||||
export FZF_DEFAULT_OPTS='--color=bg+:#D9D9D9,bg:#E1E1E1,border:#C8C8C8,spinner:#719899,hl:#719872,fg:#616161,header:#719872,info:#727100,pointer:#E12672,marker:#E17899,fg+:#616161,preview-bg:#D9D9D9,prompt:#0099BD,hl+:#719899'
|
||||
```
|
||||
|
||||
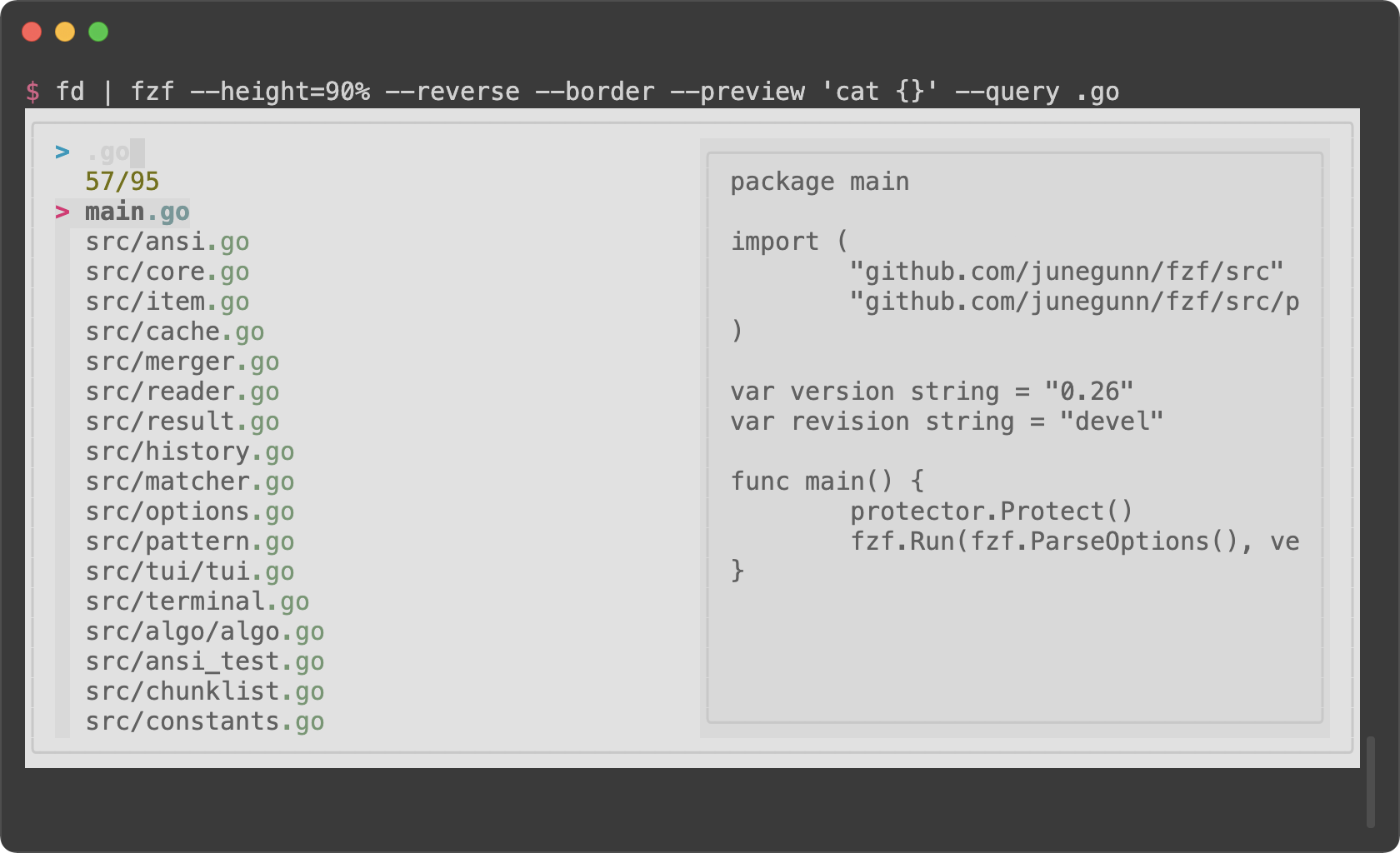
|
||||
|
||||
```sh
|
||||
# morhetz/gruvbox
|
||||
export FZF_DEFAULT_OPTS='--color=bg+:#3c3836,bg:#32302f,spinner:#fb4934,hl:#928374,fg:#ebdbb2,header:#928374,info:#8ec07c,pointer:#fb4934,marker:#fb4934,fg+:#ebdbb2,prompt:#fb4934,hl+:#fb4934'
|
||||
```
|
||||
|
||||
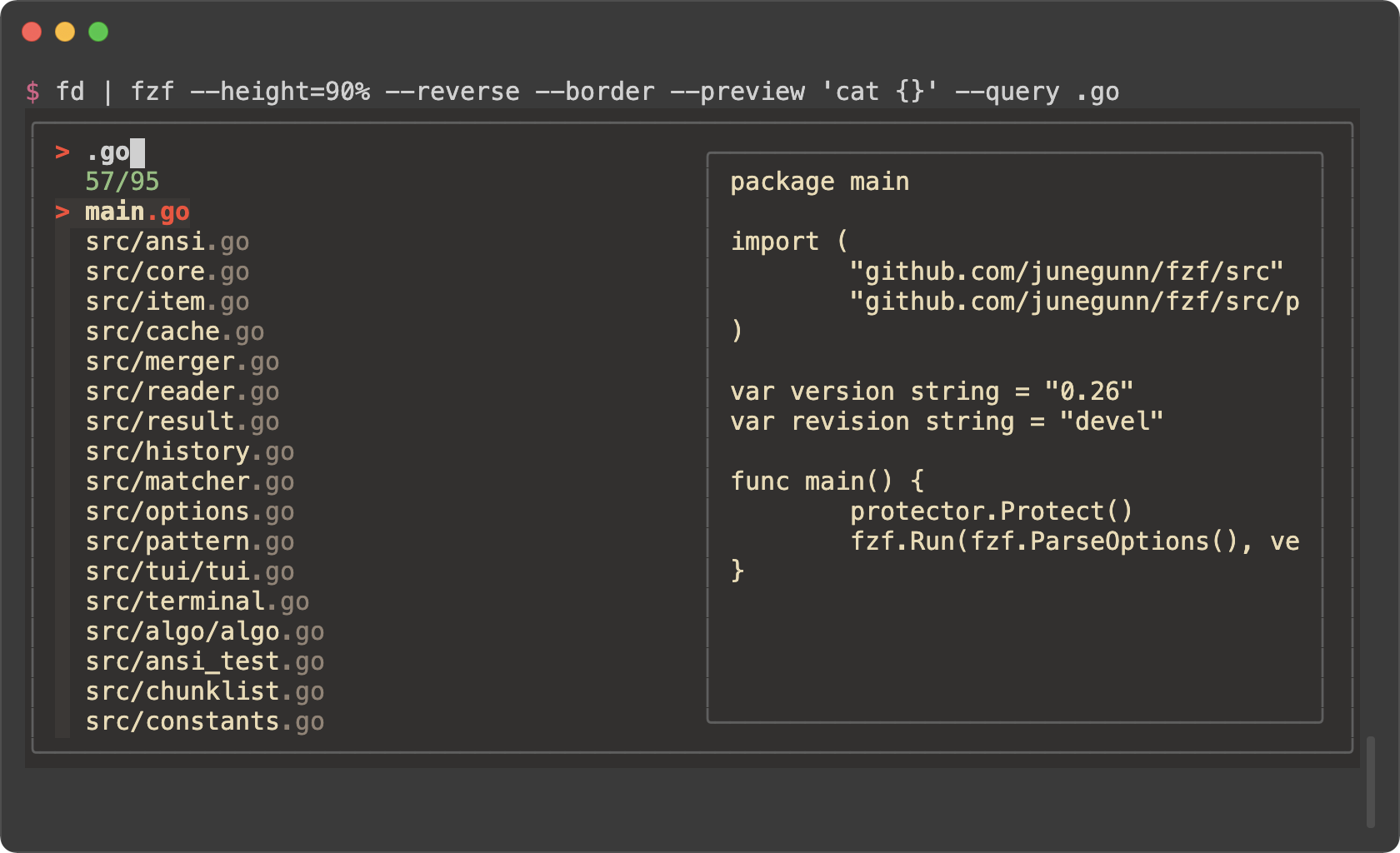
|
||||
|
||||
```sh
|
||||
# arcticicestudio/nord-vim
|
||||
export FZF_DEFAULT_OPTS='--color=bg+:#3B4252,bg:#2E3440,spinner:#81A1C1,hl:#616E88,fg:#D8DEE9,header:#616E88,info:#81A1C1,pointer:#81A1C1,marker:#81A1C1,fg+:#D8DEE9,prompt:#81A1C1,hl+:#81A1C1'
|
||||
```
|
||||
|
||||
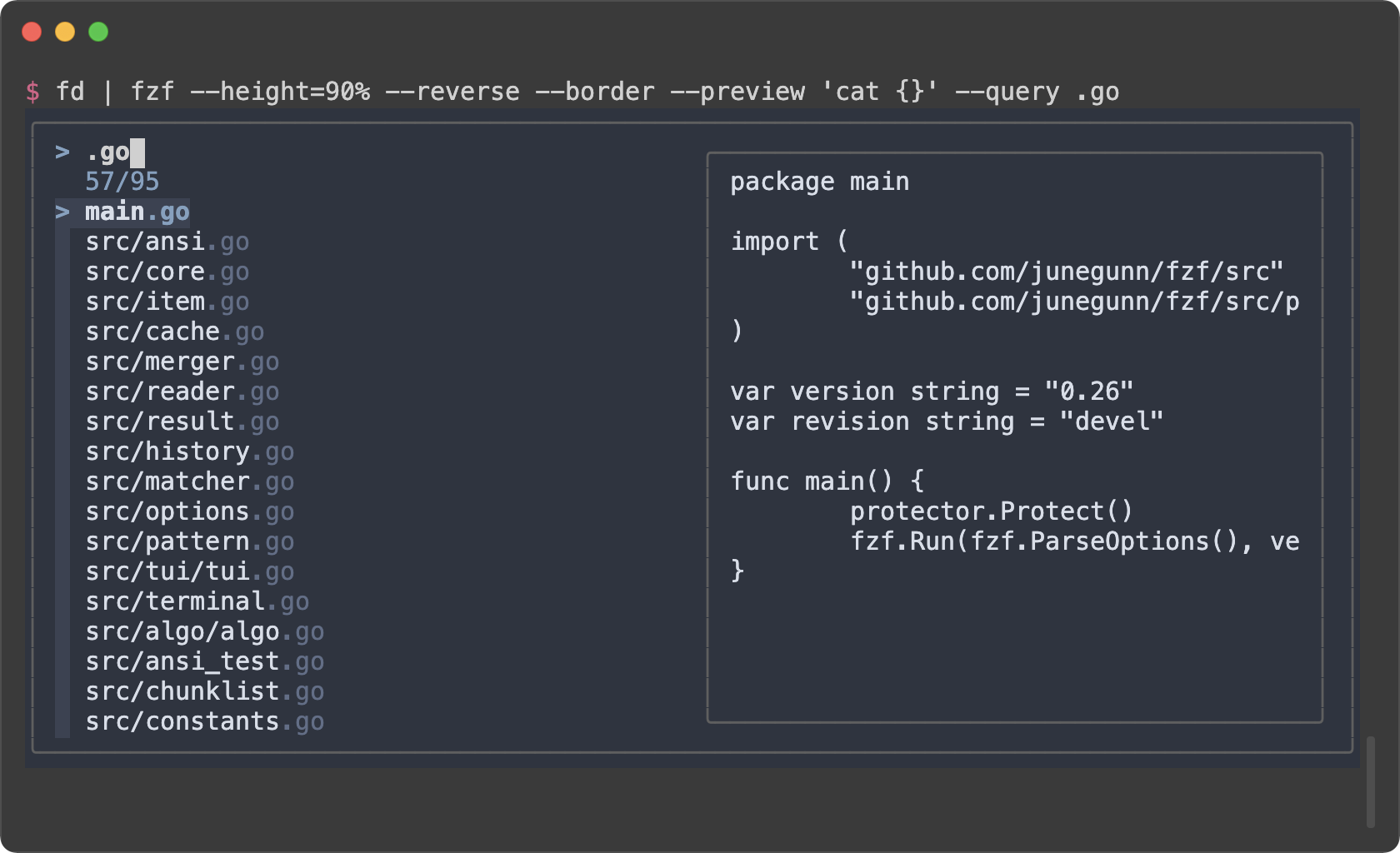
|
||||
|
||||
```sh
|
||||
# tomasr/molokai
|
||||
export FZF_DEFAULT_OPTS='--color=bg+:#293739,bg:#1B1D1E,border:#808080,spinner:#E6DB74,hl:#7E8E91,fg:#F8F8F2,header:#7E8E91,info:#A6E22E,pointer:#A6E22E,marker:#F92672,fg+:#F8F8F2,prompt:#F92672,hl+:#F92672'
|
||||
```
|
||||
|
||||
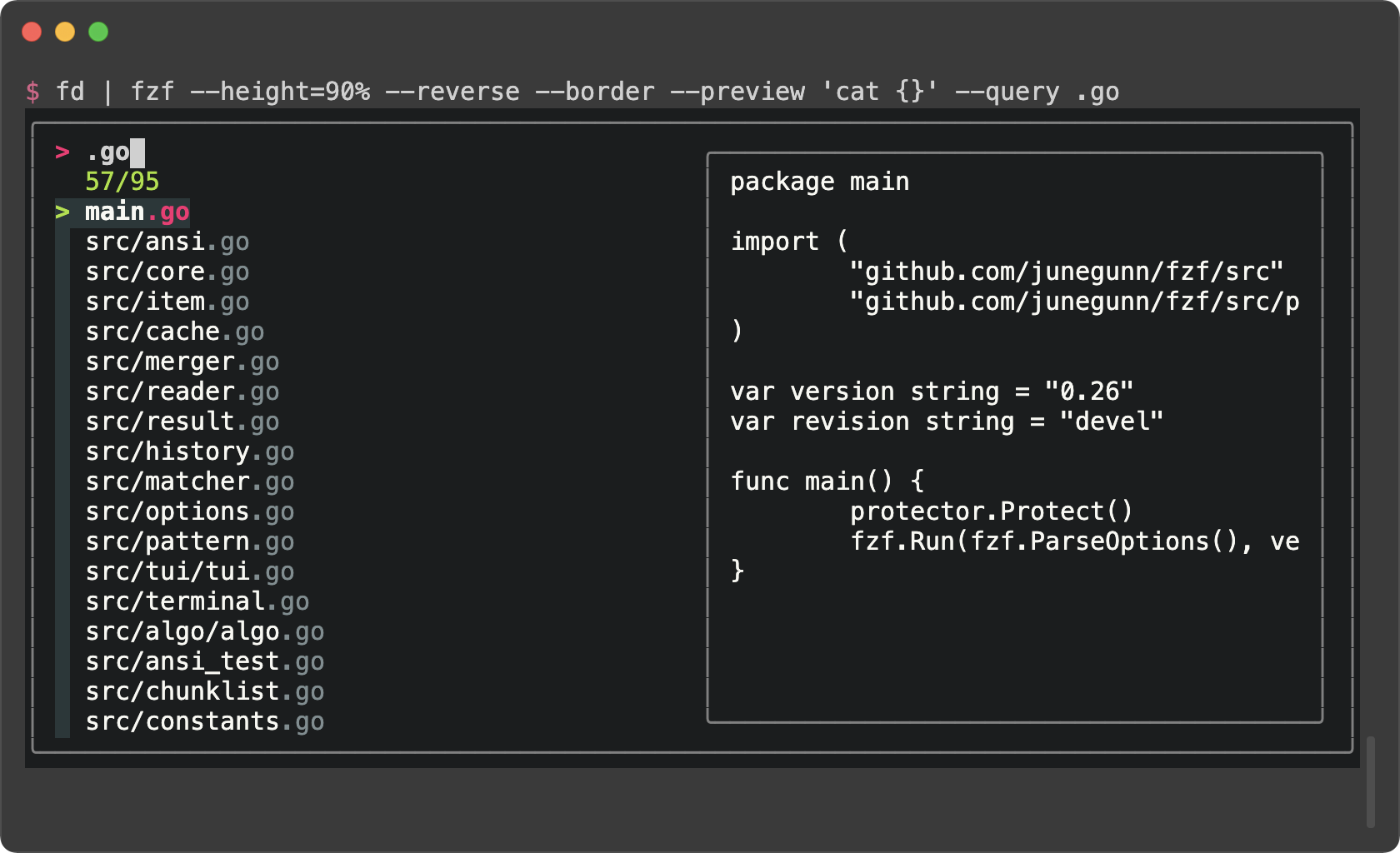
|
||||
|
||||
### Generating fzf color theme from Vim color schemes
|
||||
|
||||
The Vim plugin of fzf can generate `--color` option from the current color
|
||||
scheme according to `g:fzf_colors` variable. You can find the detailed
|
||||
explanation [here](https://github.com/junegunn/fzf/blob/master/README-VIM.md#explanation-of-gfzf_colors).
|
||||
|
||||
Here is an example. Add this to your Vim configuration file.
|
||||
|
||||
```vim
|
||||
let g:fzf_colors =
|
||||
\ { 'fg': ['fg', 'Normal'],
|
||||
\ 'bg': ['bg', 'Normal'],
|
||||
\ 'preview-bg': ['bg', 'NormalFloat'],
|
||||
\ 'hl': ['fg', 'Comment'],
|
||||
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
||||
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
||||
\ 'hl+': ['fg', 'Statement'],
|
||||
\ 'info': ['fg', 'PreProc'],
|
||||
\ 'border': ['fg', 'Ignore'],
|
||||
\ 'prompt': ['fg', 'Conditional'],
|
||||
\ 'pointer': ['fg', 'Exception'],
|
||||
\ 'marker': ['fg', 'Keyword'],
|
||||
\ 'spinner': ['fg', 'Label'],
|
||||
\ 'header': ['fg', 'Comment'] }
|
||||
```
|
||||
|
||||
Then you can see how the `--color` option is generated by printing the result
|
||||
of `fzf#wrap()`.
|
||||
|
||||
```vim
|
||||
:echo fzf#wrap()
|
||||
```
|
||||
|
||||
Use this command to append `export FZF_DEFAULT_OPTS="..."` line to the end of
|
||||
the current file.
|
||||
|
||||
```vim
|
||||
:call append('$', printf('export FZF_DEFAULT_OPTS="%s"', matchstr(fzf#wrap().options, "--color[^']*")))
|
||||
```
|
||||
@ -1,49 +0,0 @@
|
||||
Building fzf
|
||||
============
|
||||
|
||||
Build instructions
|
||||
------------------
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Go 1.13 or above
|
||||
|
||||
### Using Makefile
|
||||
|
||||
```sh
|
||||
# Build fzf binary for your platform in target
|
||||
make
|
||||
|
||||
# Build fzf binary and copy it to bin directory
|
||||
make install
|
||||
|
||||
# Build fzf binaries and archives for all platforms using goreleaser
|
||||
make build
|
||||
|
||||
# Publish GitHub release
|
||||
make release
|
||||
```
|
||||
|
||||
> :warning: Makefile uses git commands to determine the version and the
|
||||
> revision information for `fzf --version`. So if you're building fzf from an
|
||||
> environment where its git information is not available, you have to manually
|
||||
> set `$FZF_VERSION` and `$FZF_REVISION`.
|
||||
>
|
||||
> e.g. `FZF_VERSION=0.24.0 FZF_REVISION=tarball make`
|
||||
|
||||
Third-party libraries used
|
||||
--------------------------
|
||||
|
||||
- [mattn/go-runewidth](https://github.com/mattn/go-runewidth)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [mattn/go-shellwords](https://github.com/mattn/go-shellwords)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [mattn/go-isatty](https://github.com/mattn/go-isatty)
|
||||
- Licensed under [MIT](http://mattn.mit-license.org)
|
||||
- [tcell](https://github.com/gdamore/tcell)
|
||||
- Licensed under [Apache License 2.0](https://github.com/gdamore/tcell/blob/master/LICENSE)
|
||||
|
||||
License
|
||||
-------
|
||||
|
||||
[MIT](LICENSE)
|
||||
1193
.fzf/CHANGELOG.md
1193
.fzf/CHANGELOG.md
File diff suppressed because it is too large
Load Diff
@ -1,11 +0,0 @@
|
||||
FROM archlinux/base:latest
|
||||
RUN pacman -Sy && pacman --noconfirm -S awk git tmux zsh fish ruby procps go make gcc
|
||||
RUN gem install --no-document -v 5.14.2 minitest
|
||||
RUN echo '. /usr/share/bash-completion/completions/git' >> ~/.bashrc
|
||||
RUN echo '. ~/.bashrc' >> ~/.bash_profile
|
||||
|
||||
# Do not set default PS1
|
||||
RUN rm -f /etc/bash.bashrc
|
||||
COPY . /fzf
|
||||
RUN cd /fzf && make install && ./install --all
|
||||
CMD tmux new 'set -o pipefail; ruby /fzf/test/test_go.rb | tee out && touch ok' && cat out && [ -e ok ]
|
||||
21
.fzf/LICENSE
21
.fzf/LICENSE
@ -1,21 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
166
.fzf/Makefile
166
.fzf/Makefile
@ -1,166 +0,0 @@
|
||||
SHELL := bash
|
||||
GO ?= go
|
||||
GOOS ?= $(word 1, $(subst /, " ", $(word 4, $(shell go version))))
|
||||
|
||||
MAKEFILE := $(realpath $(lastword $(MAKEFILE_LIST)))
|
||||
ROOT_DIR := $(shell dirname $(MAKEFILE))
|
||||
SOURCES := $(wildcard *.go src/*.go src/*/*.go) $(MAKEFILE)
|
||||
|
||||
ifdef FZF_VERSION
|
||||
VERSION := $(FZF_VERSION)
|
||||
else
|
||||
VERSION := $(shell git describe --abbrev=0 2> /dev/null)
|
||||
endif
|
||||
ifeq ($(VERSION),)
|
||||
$(error Not on git repository; cannot determine $$FZF_VERSION)
|
||||
endif
|
||||
VERSION_TRIM := $(shell sed "s/-.*//" <<< $(VERSION))
|
||||
VERSION_REGEX := $(subst .,\.,$(VERSION_TRIM))
|
||||
|
||||
ifdef FZF_REVISION
|
||||
REVISION := $(FZF_REVISION)
|
||||
else
|
||||
REVISION := $(shell git log -n 1 --pretty=format:%h -- $(SOURCES) 2> /dev/null)
|
||||
endif
|
||||
ifeq ($(REVISION),)
|
||||
$(error Not on git repository; cannot determine $$FZF_REVISION)
|
||||
endif
|
||||
BUILD_FLAGS := -a -ldflags "-s -w -X main.version=$(VERSION) -X main.revision=$(REVISION)" -tags "$(TAGS)"
|
||||
|
||||
BINARY32 := fzf-$(GOOS)_386
|
||||
BINARY64 := fzf-$(GOOS)_amd64
|
||||
BINARYARM5 := fzf-$(GOOS)_arm5
|
||||
BINARYARM6 := fzf-$(GOOS)_arm6
|
||||
BINARYARM7 := fzf-$(GOOS)_arm7
|
||||
BINARYARM8 := fzf-$(GOOS)_arm8
|
||||
BINARYPPC64LE := fzf-$(GOOS)_ppc64le
|
||||
BINARYRISCV64 := fzf-$(GOOS)_riscv64
|
||||
|
||||
# https://en.wikipedia.org/wiki/Uname
|
||||
UNAME_M := $(shell uname -m)
|
||||
ifeq ($(UNAME_M),x86_64)
|
||||
BINARY := $(BINARY64)
|
||||
else ifeq ($(UNAME_M),amd64)
|
||||
BINARY := $(BINARY64)
|
||||
else ifeq ($(UNAME_M),i686)
|
||||
BINARY := $(BINARY32)
|
||||
else ifeq ($(UNAME_M),i386)
|
||||
BINARY := $(BINARY32)
|
||||
else ifeq ($(UNAME_M),armv5l)
|
||||
BINARY := $(BINARYARM5)
|
||||
else ifeq ($(UNAME_M),armv6l)
|
||||
BINARY := $(BINARYARM6)
|
||||
else ifeq ($(UNAME_M),armv7l)
|
||||
BINARY := $(BINARYARM7)
|
||||
else ifeq ($(UNAME_M),armv8l)
|
||||
BINARY := $(BINARYARM8)
|
||||
else ifeq ($(UNAME_M),arm64)
|
||||
BINARY := $(BINARYARM8)
|
||||
else ifeq ($(UNAME_M),aarch64)
|
||||
BINARY := $(BINARYARM8)
|
||||
else ifeq ($(UNAME_M),ppc64le)
|
||||
BINARY := $(BINARYPPC64LE)
|
||||
else ifeq ($(UNAME_M),riscv64)
|
||||
BINARY := $(BINARYRISCV64)
|
||||
else
|
||||
$(error Build on $(UNAME_M) is not supported, yet.)
|
||||
endif
|
||||
|
||||
all: target/$(BINARY)
|
||||
|
||||
test: $(SOURCES)
|
||||
[ -z "$$(gofmt -s -d src)" ] || (gofmt -s -d src; exit 1)
|
||||
SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" \
|
||||
github.com/junegunn/fzf/src \
|
||||
github.com/junegunn/fzf/src/algo \
|
||||
github.com/junegunn/fzf/src/tui \
|
||||
github.com/junegunn/fzf/src/util
|
||||
|
||||
bench:
|
||||
cd src && SHELL=/bin/sh GOOS= $(GO) test -v -tags "$(TAGS)" -run=Bench -bench=. -benchmem
|
||||
|
||||
install: bin/fzf
|
||||
|
||||
build:
|
||||
goreleaser --rm-dist --snapshot
|
||||
|
||||
release:
|
||||
ifndef GITHUB_TOKEN
|
||||
$(error GITHUB_TOKEN is not defined)
|
||||
endif
|
||||
|
||||
# Check if we are on master branch
|
||||
ifneq ($(shell git symbolic-ref --short HEAD),master)
|
||||
$(error Not on master branch)
|
||||
endif
|
||||
|
||||
# Check if version numbers are properly updated
|
||||
grep -q ^$(VERSION_REGEX)$$ CHANGELOG.md
|
||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf.1
|
||||
grep -qF '"fzf $(VERSION_TRIM)"' man/man1/fzf-tmux.1
|
||||
grep -qF $(VERSION) install
|
||||
grep -qF $(VERSION) install.ps1
|
||||
|
||||
# Make release note out of CHANGELOG.md
|
||||
mkdir -p tmp
|
||||
sed -n '/^$(VERSION_REGEX)$$/,/^[0-9]/p' CHANGELOG.md | tail -r | \
|
||||
sed '1,/^ *$$/d' | tail -r | sed 1,2d | tee tmp/release-note
|
||||
|
||||
# Push to temp branch first so that install scripts always works on master branch
|
||||
git checkout -B temp master
|
||||
git push origin temp --follow-tags --force
|
||||
|
||||
# Make a GitHub release
|
||||
goreleaser --rm-dist --release-notes tmp/release-note
|
||||
|
||||
# Push to master
|
||||
git checkout master
|
||||
git push origin master
|
||||
|
||||
# Delete temp branch
|
||||
git push origin --delete temp
|
||||
|
||||
clean:
|
||||
$(RM) -r dist target
|
||||
|
||||
target/$(BINARY32): $(SOURCES)
|
||||
GOARCH=386 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARY64): $(SOURCES)
|
||||
GOARCH=amd64 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
# https://github.com/golang/go/wiki/GoArm
|
||||
target/$(BINARYARM5): $(SOURCES)
|
||||
GOARCH=arm GOARM=5 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYARM6): $(SOURCES)
|
||||
GOARCH=arm GOARM=6 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYARM7): $(SOURCES)
|
||||
GOARCH=arm GOARM=7 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYARM8): $(SOURCES)
|
||||
GOARCH=arm64 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYPPC64LE): $(SOURCES)
|
||||
GOARCH=ppc64le $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
target/$(BINARYRISCV64): $(SOURCES)
|
||||
GOARCH=riscv64 $(GO) build $(BUILD_FLAGS) -o $@
|
||||
|
||||
bin/fzf: target/$(BINARY) | bin
|
||||
cp -f target/$(BINARY) bin/fzf
|
||||
|
||||
docker:
|
||||
docker build -t fzf-arch .
|
||||
docker run -it fzf-arch tmux
|
||||
|
||||
docker-test:
|
||||
docker build -t fzf-arch .
|
||||
docker run -it fzf-arch
|
||||
|
||||
update:
|
||||
$(GO) get -u
|
||||
$(GO) mod tidy
|
||||
|
||||
.PHONY: all build release test bench install clean docker docker-test update
|
||||
@ -1,486 +0,0 @@
|
||||
FZF Vim integration
|
||||
===================
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
Once you have fzf installed, you can enable it inside Vim simply by adding the
|
||||
directory to `&runtimepath` in your Vim configuration file. The path may
|
||||
differ depending on the package manager.
|
||||
|
||||
```vim
|
||||
" If installed using Homebrew
|
||||
set rtp+=/usr/local/opt/fzf
|
||||
|
||||
" If installed using git
|
||||
set rtp+=~/.fzf
|
||||
```
|
||||
|
||||
If you use [vim-plug](https://github.com/junegunn/vim-plug), the same can be
|
||||
written as:
|
||||
|
||||
```vim
|
||||
" If installed using Homebrew
|
||||
Plug '/usr/local/opt/fzf'
|
||||
|
||||
" If installed using git
|
||||
Plug '~/.fzf'
|
||||
```
|
||||
|
||||
But if you want the latest Vim plugin file from GitHub rather than the one
|
||||
included in the package, write:
|
||||
|
||||
```vim
|
||||
Plug 'junegunn/fzf'
|
||||
```
|
||||
|
||||
The Vim plugin will pick up fzf binary available on the system. If fzf is not
|
||||
found on `$PATH`, it will ask you if it should download the latest binary for
|
||||
you.
|
||||
|
||||
To make sure that you have the latest version of the binary, set up
|
||||
post-update hook like so:
|
||||
|
||||
```vim
|
||||
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } }
|
||||
```
|
||||
|
||||
Summary
|
||||
-------
|
||||
|
||||
The Vim plugin of fzf provides two core functions, and `:FZF` command which is
|
||||
the basic file selector command built on top of them.
|
||||
|
||||
1. **`fzf#run([spec dict])`**
|
||||
- Starts fzf inside Vim with the given spec
|
||||
- `:call fzf#run({'source': 'ls'})`
|
||||
2. **`fzf#wrap([spec dict]) -> (dict)`**
|
||||
- Takes a spec for `fzf#run` and returns an extended version of it with
|
||||
additional options for addressing global preferences (`g:fzf_xxx`)
|
||||
- `:echo fzf#wrap({'source': 'ls'})`
|
||||
- We usually *wrap* a spec with `fzf#wrap` before passing it to `fzf#run`
|
||||
- `:call fzf#run(fzf#wrap({'source': 'ls'}))`
|
||||
3. **`:FZF [fzf_options string] [path string]`**
|
||||
- Basic fuzzy file selector
|
||||
- A reference implementation for those who don't want to write VimScript
|
||||
to implement custom commands
|
||||
- If you're looking for more such commands, check out [fzf.vim](https://github.com/junegunn/fzf.vim) project.
|
||||
|
||||
The most important of all is `fzf#run`, but it would be easier to understand
|
||||
the whole if we start off with `:FZF` command.
|
||||
|
||||
`:FZF[!]`
|
||||
---------
|
||||
|
||||
```vim
|
||||
" Look for files under current directory
|
||||
:FZF
|
||||
|
||||
" Look for files under your home directory
|
||||
:FZF ~
|
||||
|
||||
" With fzf command-line options
|
||||
:FZF --reverse --info=inline /tmp
|
||||
|
||||
" Bang version starts fzf in fullscreen mode
|
||||
:FZF!
|
||||
```
|
||||
|
||||
Similarly to [ctrlp.vim](https://github.com/kien/ctrlp.vim), use enter key,
|
||||
`CTRL-T`, `CTRL-X` or `CTRL-V` to open selected files in the current window,
|
||||
in new tabs, in horizontal splits, or in vertical splits respectively.
|
||||
|
||||
Note that the environment variables `FZF_DEFAULT_COMMAND` and
|
||||
`FZF_DEFAULT_OPTS` also apply here.
|
||||
|
||||
### Configuration
|
||||
|
||||
- `g:fzf_action`
|
||||
- Customizable extra key bindings for opening selected files in different ways
|
||||
- `g:fzf_layout`
|
||||
- Determines the size and position of fzf window
|
||||
- `g:fzf_colors`
|
||||
- Customizes fzf colors to match the current color scheme
|
||||
- `g:fzf_history_dir`
|
||||
- Enables history feature
|
||||
|
||||
#### Examples
|
||||
|
||||
```vim
|
||||
" This is the default extra key bindings
|
||||
let g:fzf_action = {
|
||||
\ 'ctrl-t': 'tab split',
|
||||
\ 'ctrl-x': 'split',
|
||||
\ 'ctrl-v': 'vsplit' }
|
||||
|
||||
" An action can be a reference to a function that processes selected lines
|
||||
function! s:build_quickfix_list(lines)
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val }'))
|
||||
copen
|
||||
cc
|
||||
endfunction
|
||||
|
||||
let g:fzf_action = {
|
||||
\ 'ctrl-q': function('s:build_quickfix_list'),
|
||||
\ 'ctrl-t': 'tab split',
|
||||
\ 'ctrl-x': 'split',
|
||||
\ 'ctrl-v': 'vsplit' }
|
||||
|
||||
" Default fzf layout
|
||||
" - Popup window (center of the screen)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
|
||||
" - Popup window (center of the current window)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6, 'relative': v:true } }
|
||||
|
||||
" - Popup window (anchored to the bottom of the current window)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6, 'relative': v:true, 'yoffset': 1.0 } }
|
||||
|
||||
" - down / up / left / right
|
||||
let g:fzf_layout = { 'down': '40%' }
|
||||
|
||||
" - Window using a Vim command
|
||||
let g:fzf_layout = { 'window': 'enew' }
|
||||
let g:fzf_layout = { 'window': '-tabnew' }
|
||||
let g:fzf_layout = { 'window': '10new' }
|
||||
|
||||
" Customize fzf colors to match your color scheme
|
||||
" - fzf#wrap translates this to a set of `--color` options
|
||||
let g:fzf_colors =
|
||||
\ { 'fg': ['fg', 'Normal'],
|
||||
\ 'bg': ['bg', 'Normal'],
|
||||
\ 'hl': ['fg', 'Comment'],
|
||||
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
||||
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
||||
\ 'hl+': ['fg', 'Statement'],
|
||||
\ 'info': ['fg', 'PreProc'],
|
||||
\ 'border': ['fg', 'Ignore'],
|
||||
\ 'prompt': ['fg', 'Conditional'],
|
||||
\ 'pointer': ['fg', 'Exception'],
|
||||
\ 'marker': ['fg', 'Keyword'],
|
||||
\ 'spinner': ['fg', 'Label'],
|
||||
\ 'header': ['fg', 'Comment'] }
|
||||
|
||||
" Enable per-command history
|
||||
" - History files will be stored in the specified directory
|
||||
" - When set, CTRL-N and CTRL-P will be bound to 'next-history' and
|
||||
" 'previous-history' instead of 'down' and 'up'.
|
||||
let g:fzf_history_dir = '~/.local/share/fzf-history'
|
||||
```
|
||||
|
||||
##### Explanation of `g:fzf_colors`
|
||||
|
||||
`g:fzf_colors` is a dictionary mapping fzf elements to a color specification
|
||||
list:
|
||||
|
||||
element: [ component, group1 [, group2, ...] ]
|
||||
|
||||
- `element` is an fzf element to apply a color to:
|
||||
|
||||
| Element | Description |
|
||||
| --- | --- |
|
||||
| `fg` / `bg` / `hl` | Item (foreground / background / highlight) |
|
||||
| `fg+` / `bg+` / `hl+` | Current item (foreground / background / highlight) |
|
||||
| `preview-fg` / `preview-bg` | Preview window text and background |
|
||||
| `hl` / `hl+` | Highlighted substrings (normal / current) |
|
||||
| `gutter` | Background of the gutter on the left |
|
||||
| `pointer` | Pointer to the current line (`>`) |
|
||||
| `marker` | Multi-select marker (`>`) |
|
||||
| `border` | Border around the window (`--border` and `--preview`) |
|
||||
| `header` | Header (`--header` or `--header-lines`) |
|
||||
| `info` | Info line (match counters) |
|
||||
| `spinner` | Streaming input indicator |
|
||||
| `query` | Query string |
|
||||
| `disabled` | Query string when search is disabled |
|
||||
| `prompt` | Prompt before query (`> `) |
|
||||
| `pointer` | Pointer to the current line (`>`) |
|
||||
|
||||
- `component` specifies the component (`fg` / `bg`) from which to extract the
|
||||
color when considering each of the following highlight groups
|
||||
|
||||
- `group1 [, group2, ...]` is a list of highlight groups that are searched (in
|
||||
order) for a matching color definition
|
||||
|
||||
For example, consider the following specification:
|
||||
|
||||
```vim
|
||||
'prompt': ['fg', 'Conditional', 'Comment'],
|
||||
```
|
||||
|
||||
This means we color the **prompt**
|
||||
- using the `fg` attribute of the `Conditional` if it exists,
|
||||
- otherwise use the `fg` attribute of the `Comment` highlight group if it exists,
|
||||
- otherwise fall back to the default color settings for the **prompt**.
|
||||
|
||||
You can examine the color option generated according the setting by printing
|
||||
the result of `fzf#wrap()` function like so:
|
||||
|
||||
```vim
|
||||
:echo fzf#wrap()
|
||||
```
|
||||
|
||||
`fzf#run`
|
||||
---------
|
||||
|
||||
`fzf#run()` function is the core of Vim integration. It takes a single
|
||||
dictionary argument, *a spec*, and starts fzf process accordingly. At the very
|
||||
least, specify `sink` option to tell what it should do with the selected
|
||||
entry.
|
||||
|
||||
```vim
|
||||
call fzf#run({'sink': 'e'})
|
||||
```
|
||||
|
||||
We haven't specified the `source`, so this is equivalent to starting fzf on
|
||||
command line without standard input pipe; fzf will use find command (or
|
||||
`$FZF_DEFAULT_COMMAND` if defined) to list the files under the current
|
||||
directory. When you select one, it will open it with the sink, `:e` command.
|
||||
If you want to open it in a new tab, you can pass `:tabedit` command instead
|
||||
as the sink.
|
||||
|
||||
```vim
|
||||
call fzf#run({'sink': 'tabedit'})
|
||||
```
|
||||
|
||||
Instead of using the default find command, you can use any shell command as
|
||||
the source. The following example will list the files managed by git. It's
|
||||
equivalent to running `git ls-files | fzf` on shell.
|
||||
|
||||
```vim
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e'})
|
||||
```
|
||||
|
||||
fzf options can be specified as `options` entry in spec dictionary.
|
||||
|
||||
```vim
|
||||
call fzf#run({'sink': 'tabedit', 'options': '--multi --reverse'})
|
||||
```
|
||||
|
||||
You can also pass a layout option if you don't want fzf window to take up the
|
||||
entire screen.
|
||||
|
||||
```vim
|
||||
" up / down / left / right / window are allowed
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e', 'left': '40%'})
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e', 'window': '30vnew'})
|
||||
```
|
||||
|
||||
`source` doesn't have to be an external shell command, you can pass a Vim
|
||||
array as the source. In the next example, we pass the names of color
|
||||
schemes as the source to implement a color scheme selector.
|
||||
|
||||
```vim
|
||||
call fzf#run({'source': map(split(globpath(&rtp, 'colors/*.vim')),
|
||||
\ 'fnamemodify(v:val, ":t:r")'),
|
||||
\ 'sink': 'colo', 'left': '25%'})
|
||||
```
|
||||
|
||||
The following table summarizes the available options.
|
||||
|
||||
| Option name | Type | Description |
|
||||
| -------------------------- | ------------- | ---------------------------------------------------------------- |
|
||||
| `source` | string | External command to generate input to fzf (e.g. `find .`) |
|
||||
| `source` | list | Vim list as input to fzf |
|
||||
| `sink` | string | Vim command to handle the selected item (e.g. `e`, `tabe`) |
|
||||
| `sink` | funcref | Reference to function to process each selected item |
|
||||
| `sinklist` (or `sink*`) | funcref | Similar to `sink`, but takes the list of output lines at once |
|
||||
| `options` | string/list | Options to fzf |
|
||||
| `dir` | string | Working directory |
|
||||
| `up`/`down`/`left`/`right` | number/string | (Layout) Window position and size (e.g. `20`, `50%`) |
|
||||
| `tmux` | string | (Layout) fzf-tmux options (e.g. `-p90%,60%`) |
|
||||
| `window` (Vim 8 / Neovim) | string | (Layout) Command to open fzf window (e.g. `vertical aboveleft 30new`) |
|
||||
| `window` (Vim 8 / Neovim) | dict | (Layout) Popup window settings (e.g. `{'width': 0.9, 'height': 0.6}`) |
|
||||
|
||||
`options` entry can be either a string or a list. For simple cases, string
|
||||
should suffice, but prefer to use list type to avoid escaping issues.
|
||||
|
||||
```vim
|
||||
call fzf#run({'options': '--reverse --prompt "C:\\Program Files\\"'})
|
||||
call fzf#run({'options': ['--reverse', '--prompt', 'C:\Program Files\']})
|
||||
```
|
||||
|
||||
When `window` entry is a dictionary, fzf will start in a popup window. The
|
||||
following options are allowed:
|
||||
|
||||
- Required:
|
||||
- `width` [float range [0 ~ 1]] or [integer range [8 ~ ]]
|
||||
- `height` [float range [0 ~ 1]] or [integer range [4 ~ ]]
|
||||
- Optional:
|
||||
- `yoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `xoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `relative` [boolean default v:false]
|
||||
- `border` [string default `rounded`]: Border style
|
||||
- `rounded` / `sharp` / `horizontal` / `vertical` / `top` / `bottom` / `left` / `right` / `no[ne]`
|
||||
|
||||
`fzf#wrap`
|
||||
----------
|
||||
|
||||
We have seen that several aspects of `:FZF` command can be configured with
|
||||
a set of global option variables; different ways to open files
|
||||
(`g:fzf_action`), window position and size (`g:fzf_layout`), color palette
|
||||
(`g:fzf_colors`), etc.
|
||||
|
||||
So how can we make our custom `fzf#run` calls also respect those variables?
|
||||
Simply by *"wrapping"* the spec dictionary with `fzf#wrap` before passing it
|
||||
to `fzf#run`.
|
||||
|
||||
- **`fzf#wrap([name string], [spec dict], [fullscreen bool]) -> (dict)`**
|
||||
- All arguments are optional. Usually we only need to pass a spec dictionary.
|
||||
- `name` is for managing history files. It is ignored if
|
||||
`g:fzf_history_dir` is not defined.
|
||||
- `fullscreen` can be either `0` or `1` (default: 0).
|
||||
|
||||
`fzf#wrap` takes a spec and returns an extended version of it (also
|
||||
a dictionary) with additional options for addressing global preferences. You
|
||||
can examine the return value of it like so:
|
||||
|
||||
```vim
|
||||
echo fzf#wrap({'source': 'ls'})
|
||||
```
|
||||
|
||||
After we *"wrap"* our spec, we pass it to `fzf#run`.
|
||||
|
||||
```vim
|
||||
call fzf#run(fzf#wrap({'source': 'ls'}))
|
||||
```
|
||||
|
||||
Now it supports `CTRL-T`, `CTRL-V`, and `CTRL-X` key bindings (configurable
|
||||
via `g:fzf_action`) and it opens fzf window according to `g:fzf_layout`
|
||||
setting.
|
||||
|
||||
To make it easier to use, let's define `LS` command.
|
||||
|
||||
```vim
|
||||
command! LS call fzf#run(fzf#wrap({'source': 'ls'}))
|
||||
```
|
||||
|
||||
Type `:LS` and see how it works.
|
||||
|
||||
We would like to make `:LS!` (bang version) open fzf in fullscreen, just like
|
||||
`:FZF!`. Add `-bang` to command definition, and use `<bang>` value to set
|
||||
the last `fullscreen` argument of `fzf#wrap` (see `:help <bang>`).
|
||||
|
||||
```vim
|
||||
" On :LS!, <bang> evaluates to '!', and '!0' becomes 1
|
||||
command! -bang LS call fzf#run(fzf#wrap({'source': 'ls'}, <bang>0))
|
||||
```
|
||||
|
||||
Our `:LS` command will be much more useful if we can pass a directory argument
|
||||
to it, so that something like `:LS /tmp` is possible.
|
||||
|
||||
```vim
|
||||
command! -bang -complete=dir -nargs=? LS
|
||||
\ call fzf#run(fzf#wrap({'source': 'ls', 'dir': <q-args>}, <bang>0))
|
||||
```
|
||||
|
||||
Lastly, if you have enabled `g:fzf_history_dir`, you might want to assign
|
||||
a unique name to our command and pass it as the first argument to `fzf#wrap`.
|
||||
|
||||
```vim
|
||||
" The query history for this command will be stored as 'ls' inside g:fzf_history_dir.
|
||||
" The name is ignored if g:fzf_history_dir is not defined.
|
||||
command! -bang -complete=dir -nargs=? LS
|
||||
\ call fzf#run(fzf#wrap('ls', {'source': 'ls', 'dir': <q-args>}, <bang>0))
|
||||
```
|
||||
|
||||
### Global options supported by `fzf#wrap`
|
||||
|
||||
- `g:fzf_layout`
|
||||
- `g:fzf_action`
|
||||
- **Works only when no custom `sink` (or `sinklist`) is provided**
|
||||
- Having custom sink usually means that each entry is not an ordinary
|
||||
file path (e.g. name of color scheme), so we can't blindly apply the
|
||||
same strategy (i.e. `tabedit some-color-scheme` doesn't make sense)
|
||||
- `g:fzf_colors`
|
||||
- `g:fzf_history_dir`
|
||||
|
||||
Tips
|
||||
----
|
||||
|
||||
### fzf inside terminal buffer
|
||||
|
||||
On the latest versions of Vim and Neovim, fzf will start in a terminal buffer.
|
||||
If you find the default ANSI colors to be different, consider configuring the
|
||||
colors using `g:terminal_ansi_colors` in regular Vim or `g:terminal_color_x`
|
||||
in Neovim.
|
||||
|
||||
```vim
|
||||
" Terminal colors for seoul256 color scheme
|
||||
if has('nvim')
|
||||
let g:terminal_color_0 = '#4e4e4e'
|
||||
let g:terminal_color_1 = '#d68787'
|
||||
let g:terminal_color_2 = '#5f865f'
|
||||
let g:terminal_color_3 = '#d8af5f'
|
||||
let g:terminal_color_4 = '#85add4'
|
||||
let g:terminal_color_5 = '#d7afaf'
|
||||
let g:terminal_color_6 = '#87afaf'
|
||||
let g:terminal_color_7 = '#d0d0d0'
|
||||
let g:terminal_color_8 = '#626262'
|
||||
let g:terminal_color_9 = '#d75f87'
|
||||
let g:terminal_color_10 = '#87af87'
|
||||
let g:terminal_color_11 = '#ffd787'
|
||||
let g:terminal_color_12 = '#add4fb'
|
||||
let g:terminal_color_13 = '#ffafaf'
|
||||
let g:terminal_color_14 = '#87d7d7'
|
||||
let g:terminal_color_15 = '#e4e4e4'
|
||||
else
|
||||
let g:terminal_ansi_colors = [
|
||||
\ '#4e4e4e', '#d68787', '#5f865f', '#d8af5f',
|
||||
\ '#85add4', '#d7afaf', '#87afaf', '#d0d0d0',
|
||||
\ '#626262', '#d75f87', '#87af87', '#ffd787',
|
||||
\ '#add4fb', '#ffafaf', '#87d7d7', '#e4e4e4'
|
||||
\ ]
|
||||
endif
|
||||
```
|
||||
|
||||
### Starting fzf in a popup window
|
||||
|
||||
```vim
|
||||
" Required:
|
||||
" - width [float range [0 ~ 1]] or [integer range [8 ~ ]]
|
||||
" - height [float range [0 ~ 1]] or [integer range [4 ~ ]]
|
||||
"
|
||||
" Optional:
|
||||
" - xoffset [float default 0.5 range [0 ~ 1]]
|
||||
" - yoffset [float default 0.5 range [0 ~ 1]]
|
||||
" - relative [boolean default v:false]
|
||||
" - border [string default 'rounded']: Border style
|
||||
" - 'rounded' / 'sharp' / 'horizontal' / 'vertical' / 'top' / 'bottom' / 'left' / 'right'
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
```
|
||||
|
||||
Alternatively, you can make fzf open in a tmux popup window (requires tmux 3.2
|
||||
or above) by putting fzf-tmux options in `tmux` key.
|
||||
|
||||
```vim
|
||||
" See `man fzf-tmux` for available options
|
||||
if exists('$TMUX')
|
||||
let g:fzf_layout = { 'tmux': '-p90%,60%' }
|
||||
else
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
endif
|
||||
```
|
||||
|
||||
### Hide statusline
|
||||
|
||||
When fzf starts in a terminal buffer, the file type of the buffer is set to
|
||||
`fzf`. So you can set up `FileType fzf` autocmd to customize the settings of
|
||||
the window.
|
||||
|
||||
For example, if you open fzf on the bottom on the screen (e.g. `{'down':
|
||||
'40%'}`), you might want to temporarily disable the statusline for a cleaner
|
||||
look.
|
||||
|
||||
```vim
|
||||
let g:fzf_layout = { 'down': '30%' }
|
||||
autocmd! FileType fzf
|
||||
autocmd FileType fzf set laststatus=0 noshowmode noruler
|
||||
\| autocmd BufLeave <buffer> set laststatus=2 showmode ruler
|
||||
```
|
||||
|
||||
[License](LICENSE)
|
||||
------------------
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
712
.fzf/README.md
712
.fzf/README.md
@ -1,712 +0,0 @@
|
||||
<img src="https://raw.githubusercontent.com/junegunn/i/master/fzf.png" height="170" alt="fzf - a command-line fuzzy finder"> [](https://github.com/junegunn/fzf/actions)
|
||||
===
|
||||
|
||||
fzf is a general-purpose command-line fuzzy finder.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/junegunn/i/master/fzf-preview.png" width=640>
|
||||
|
||||
It's an interactive Unix filter for command-line that can be used with any
|
||||
list; files, command history, processes, hostnames, bookmarks, git commits,
|
||||
etc.
|
||||
|
||||
Pros
|
||||
----
|
||||
|
||||
- Portable, no dependencies
|
||||
- Blazingly fast
|
||||
- The most comprehensive feature set
|
||||
- Flexible layout
|
||||
- Batteries included
|
||||
- Vim/Neovim plugin, key bindings, and fuzzy auto-completion
|
||||
|
||||
Table of Contents
|
||||
-----------------
|
||||
|
||||
<!-- vim-markdown-toc GFM -->
|
||||
|
||||
* [Installation](#installation)
|
||||
* [Using Homebrew](#using-homebrew)
|
||||
* [Using git](#using-git)
|
||||
* [Using Linux package managers](#using-linux-package-managers)
|
||||
* [Windows](#windows)
|
||||
* [As Vim plugin](#as-vim-plugin)
|
||||
* [Upgrading fzf](#upgrading-fzf)
|
||||
* [Building fzf](#building-fzf)
|
||||
* [Usage](#usage)
|
||||
* [Using the finder](#using-the-finder)
|
||||
* [Layout](#layout)
|
||||
* [Search syntax](#search-syntax)
|
||||
* [Environment variables](#environment-variables)
|
||||
* [Options](#options)
|
||||
* [Demo](#demo)
|
||||
* [Examples](#examples)
|
||||
* [`fzf-tmux` script](#fzf-tmux-script)
|
||||
* [Key bindings for command-line](#key-bindings-for-command-line)
|
||||
* [Fuzzy completion for bash and zsh](#fuzzy-completion-for-bash-and-zsh)
|
||||
* [Files and directories](#files-and-directories)
|
||||
* [Process IDs](#process-ids)
|
||||
* [Host names](#host-names)
|
||||
* [Environment variables / Aliases](#environment-variables--aliases)
|
||||
* [Settings](#settings)
|
||||
* [Supported commands](#supported-commands)
|
||||
* [Custom fuzzy completion](#custom-fuzzy-completion)
|
||||
* [Vim plugin](#vim-plugin)
|
||||
* [Advanced topics](#advanced-topics)
|
||||
* [Performance](#performance)
|
||||
* [Executing external programs](#executing-external-programs)
|
||||
* [Reloading the candidate list](#reloading-the-candidate-list)
|
||||
* [1. Update the list of processes by pressing CTRL-R](#1-update-the-list-of-processes-by-pressing-ctrl-r)
|
||||
* [2. Switch between sources by pressing CTRL-D or CTRL-F](#2-switch-between-sources-by-pressing-ctrl-d-or-ctrl-f)
|
||||
* [3. Interactive ripgrep integration](#3-interactive-ripgrep-integration)
|
||||
* [Preview window](#preview-window)
|
||||
* [Tips](#tips)
|
||||
* [Respecting `.gitignore`](#respecting-gitignore)
|
||||
* [Fish shell](#fish-shell)
|
||||
* [Related projects](#related-projects)
|
||||
* [License](#license)
|
||||
|
||||
<!-- vim-markdown-toc -->
|
||||
|
||||
Installation
|
||||
------------
|
||||
|
||||
fzf project consists of the following components:
|
||||
|
||||
- `fzf` executable
|
||||
- `fzf-tmux` script for launching fzf in a tmux pane
|
||||
- Shell extensions
|
||||
- Key bindings (`CTRL-T`, `CTRL-R`, and `ALT-C`) (bash, zsh, fish)
|
||||
- Fuzzy auto-completion (bash, zsh)
|
||||
- Vim/Neovim plugin
|
||||
|
||||
You can [download fzf executable][bin] alone if you don't need the extra
|
||||
stuff.
|
||||
|
||||
[bin]: https://github.com/junegunn/fzf/releases
|
||||
|
||||
### Using Homebrew
|
||||
|
||||
You can use [Homebrew](http://brew.sh/) (on macOS or Linux)
|
||||
to install fzf.
|
||||
|
||||
```sh
|
||||
brew install fzf
|
||||
|
||||
# To install useful key bindings and fuzzy completion:
|
||||
$(brew --prefix)/opt/fzf/install
|
||||
```
|
||||
|
||||
fzf is also available [via MacPorts][portfile]: `sudo port install fzf`
|
||||
|
||||
[portfile]: https://github.com/macports/macports-ports/blob/master/sysutils/fzf/Portfile
|
||||
|
||||
### Using git
|
||||
|
||||
Alternatively, you can "git clone" this repository to any directory and run
|
||||
[install](https://github.com/junegunn/fzf/blob/master/install) script.
|
||||
|
||||
```sh
|
||||
git clone --depth 1 https://github.com/junegunn/fzf.git ~/.fzf
|
||||
~/.fzf/install
|
||||
```
|
||||
|
||||
### Using Linux package managers
|
||||
|
||||
| Package Manager | Linux Distribution | Command |
|
||||
| --- | --- | --- |
|
||||
| APK | Alpine Linux | `sudo apk add fzf` |
|
||||
| APT | Debian 9+/Ubuntu 19.10+ | `sudo apt-get install fzf` |
|
||||
| Conda | | `conda install -c conda-forge fzf` |
|
||||
| DNF | Fedora | `sudo dnf install fzf` |
|
||||
| Nix | NixOS, etc. | `nix-env -iA nixpkgs.fzf` |
|
||||
| Pacman | Arch Linux | `sudo pacman -S fzf` |
|
||||
| pkg | FreeBSD | `pkg install fzf` |
|
||||
| pkgin | NetBSD | `pkgin install fzf` |
|
||||
| pkg_add | OpenBSD | `pkg_add fzf` |
|
||||
| XBPS | Void Linux | `sudo xbps-install -S fzf` |
|
||||
| Zypper | openSUSE | `sudo zypper install fzf` |
|
||||
|
||||
> :warning: **Key bindings (CTRL-T / CTRL-R / ALT-C) and fuzzy auto-completion
|
||||
> may not be enabled by default.**
|
||||
>
|
||||
> Refer to the package documentation for more information. (e.g. `apt-cache show fzf`)
|
||||
|
||||
[](https://repology.org/project/fzf/versions)
|
||||
|
||||
### Windows
|
||||
|
||||
Pre-built binaries for Windows can be downloaded [here][bin]. fzf is also
|
||||
available via [Chocolatey][choco] and [Scoop][scoop]:
|
||||
|
||||
| Package manager | Command |
|
||||
| --- | --- |
|
||||
| Chocolatey | `choco install fzf` |
|
||||
| Scoop | `scoop install fzf` |
|
||||
|
||||
[choco]: https://chocolatey.org/packages/fzf
|
||||
[scoop]: https://github.com/ScoopInstaller/Main/blob/master/bucket/fzf.json
|
||||
|
||||
Known issues and limitations on Windows can be found on [the wiki
|
||||
page][windows-wiki].
|
||||
|
||||
[windows-wiki]: https://github.com/junegunn/fzf/wiki/Windows
|
||||
|
||||
### As Vim plugin
|
||||
|
||||
If you use
|
||||
[vim-plug](https://github.com/junegunn/vim-plug), add this line to your Vim
|
||||
configuration file:
|
||||
|
||||
```vim
|
||||
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } }
|
||||
```
|
||||
|
||||
`fzf#install()` makes sure that you have the latest binary, but it's optional,
|
||||
so you can omit it if you use a plugin manager that doesn't support hooks.
|
||||
|
||||
For more installation options, see [README-VIM.md](README-VIM.md).
|
||||
|
||||
Upgrading fzf
|
||||
-------------
|
||||
|
||||
fzf is being actively developed, and you might want to upgrade it once in a
|
||||
while. Please follow the instruction below depending on the installation
|
||||
method used.
|
||||
|
||||
- git: `cd ~/.fzf && git pull && ./install`
|
||||
- brew: `brew update; brew upgrade fzf`
|
||||
- macports: `sudo port upgrade fzf`
|
||||
- chocolatey: `choco upgrade fzf`
|
||||
- vim-plug: `:PlugUpdate fzf`
|
||||
|
||||
Building fzf
|
||||
------------
|
||||
|
||||
See [BUILD.md](BUILD.md).
|
||||
|
||||
Usage
|
||||
-----
|
||||
|
||||
fzf will launch interactive finder, read the list from STDIN, and write the
|
||||
selected item to STDOUT.
|
||||
|
||||
```sh
|
||||
find * -type f | fzf > selected
|
||||
```
|
||||
|
||||
Without STDIN pipe, fzf will use find command to fetch the list of
|
||||
files excluding hidden ones. (You can override the default command with
|
||||
`FZF_DEFAULT_COMMAND`)
|
||||
|
||||
```sh
|
||||
vim $(fzf)
|
||||
```
|
||||
|
||||
#### Using the finder
|
||||
|
||||
- `CTRL-K` / `CTRL-J` (or `CTRL-P` / `CTRL-N`) to move cursor up and down
|
||||
- `Enter` key to select the item, `CTRL-C` / `CTRL-G` / `ESC` to exit
|
||||
- On multi-select mode (`-m`), `TAB` and `Shift-TAB` to mark multiple items
|
||||
- Emacs style key bindings
|
||||
- Mouse: scroll, click, double-click; shift-click and shift-scroll on
|
||||
multi-select mode
|
||||
|
||||
#### Layout
|
||||
|
||||
fzf by default starts in fullscreen mode, but you can make it start below the
|
||||
cursor with `--height` option.
|
||||
|
||||
```sh
|
||||
vim $(fzf --height 40%)
|
||||
```
|
||||
|
||||
Also, check out `--reverse` and `--layout` options if you prefer
|
||||
"top-down" layout instead of the default "bottom-up" layout.
|
||||
|
||||
```sh
|
||||
vim $(fzf --height 40% --reverse)
|
||||
```
|
||||
|
||||
You can add these options to `$FZF_DEFAULT_OPTS` so that they're applied by
|
||||
default. For example,
|
||||
|
||||
```sh
|
||||
export FZF_DEFAULT_OPTS='--height 40% --layout=reverse --border'
|
||||
```
|
||||
|
||||
#### Search syntax
|
||||
|
||||
Unless otherwise specified, fzf starts in "extended-search mode" where you can
|
||||
type in multiple search terms delimited by spaces. e.g. `^music .mp3$ sbtrkt
|
||||
!fire`
|
||||
|
||||
| Token | Match type | Description |
|
||||
| --------- | -------------------------- | ------------------------------------ |
|
||||
| `sbtrkt` | fuzzy-match | Items that match `sbtrkt` |
|
||||
| `'wild` | exact-match (quoted) | Items that include `wild` |
|
||||
| `^music` | prefix-exact-match | Items that start with `music` |
|
||||
| `.mp3$` | suffix-exact-match | Items that end with `.mp3` |
|
||||
| `!fire` | inverse-exact-match | Items that do not include `fire` |
|
||||
| `!^music` | inverse-prefix-exact-match | Items that do not start with `music` |
|
||||
| `!.mp3$` | inverse-suffix-exact-match | Items that do not end with `.mp3` |
|
||||
|
||||
If you don't prefer fuzzy matching and do not wish to "quote" every word,
|
||||
start fzf with `-e` or `--exact` option. Note that when `--exact` is set,
|
||||
`'`-prefix "unquotes" the term.
|
||||
|
||||
A single bar character term acts as an OR operator. For example, the following
|
||||
query matches entries that start with `core` and end with either `go`, `rb`,
|
||||
or `py`.
|
||||
|
||||
```
|
||||
^core go$ | rb$ | py$
|
||||
```
|
||||
|
||||
#### Environment variables
|
||||
|
||||
- `FZF_DEFAULT_COMMAND`
|
||||
- Default command to use when input is tty
|
||||
- e.g. `export FZF_DEFAULT_COMMAND='fd --type f'`
|
||||
- > :warning: This variable is not used by shell extensions due to the
|
||||
> slight difference in requirements.
|
||||
>
|
||||
> (e.g. `CTRL-T` runs `$FZF_CTRL_T_COMMAND` instead, `vim **<tab>` runs
|
||||
> `_fzf_compgen_path()`, and `cd **<tab>` runs `_fzf_compgen_dir()`)
|
||||
>
|
||||
> The available options are described later in this document.
|
||||
- `FZF_DEFAULT_OPTS`
|
||||
- Default options
|
||||
- e.g. `export FZF_DEFAULT_OPTS="--layout=reverse --inline-info"`
|
||||
|
||||
#### Options
|
||||
|
||||
See the man page (`man fzf`) for the full list of options.
|
||||
|
||||
#### Demo
|
||||
If you learn by watching videos, check out this screencast by [@samoshkin](https://github.com/samoshkin) to explore `fzf` features.
|
||||
|
||||
<a title="fzf - command-line fuzzy finder" href="https://www.youtube.com/watch?v=qgG5Jhi_Els">
|
||||
<img src="https://i.imgur.com/vtG8olE.png" width="640">
|
||||
</a>
|
||||
|
||||
Examples
|
||||
--------
|
||||
|
||||
* [Wiki page of examples](https://github.com/junegunn/fzf/wiki/examples)
|
||||
* *Disclaimer: The examples on this page are maintained by the community
|
||||
and are not thoroughly tested*
|
||||
* [Advanced fzf examples](https://github.com/junegunn/fzf/blob/master/ADVANCED.md)
|
||||
|
||||
`fzf-tmux` script
|
||||
-----------------
|
||||
|
||||
[fzf-tmux](bin/fzf-tmux) is a bash script that opens fzf in a tmux pane.
|
||||
|
||||
```sh
|
||||
# usage: fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
|
||||
# See available options
|
||||
fzf-tmux --help
|
||||
|
||||
# select git branches in horizontal split below (15 lines)
|
||||
git branch | fzf-tmux -d 15
|
||||
|
||||
# select multiple words in vertical split on the left (20% of screen width)
|
||||
cat /usr/share/dict/words | fzf-tmux -l 20% --multi --reverse
|
||||
```
|
||||
|
||||
It will still work even when you're not on tmux, silently ignoring `-[pudlr]`
|
||||
options, so you can invariably use `fzf-tmux` in your scripts.
|
||||
|
||||
Alternatively, you can use `--height HEIGHT[%]` option not to start fzf in
|
||||
fullscreen mode.
|
||||
|
||||
```sh
|
||||
fzf --height 40%
|
||||
```
|
||||
|
||||
Key bindings for command-line
|
||||
-----------------------------
|
||||
|
||||
The install script will setup the following key bindings for bash, zsh, and
|
||||
fish.
|
||||
|
||||
- `CTRL-T` - Paste the selected files and directories onto the command-line
|
||||
- Set `FZF_CTRL_T_COMMAND` to override the default command
|
||||
- Set `FZF_CTRL_T_OPTS` to pass additional options
|
||||
- `CTRL-R` - Paste the selected command from history onto the command-line
|
||||
- If you want to see the commands in chronological order, press `CTRL-R`
|
||||
again which toggles sorting by relevance
|
||||
- Set `FZF_CTRL_R_OPTS` to pass additional options
|
||||
- `ALT-C` - cd into the selected directory
|
||||
- Set `FZF_ALT_C_COMMAND` to override the default command
|
||||
- Set `FZF_ALT_C_OPTS` to pass additional options
|
||||
|
||||
If you're on a tmux session, you can start fzf in a tmux split-pane or in
|
||||
a tmux popup window by setting `FZF_TMUX_OPTS` (e.g. `-d 40%`).
|
||||
See `fzf-tmux --help` for available options.
|
||||
|
||||
More tips can be found on [the wiki page](https://github.com/junegunn/fzf/wiki/Configuring-shell-key-bindings).
|
||||
|
||||
Fuzzy completion for bash and zsh
|
||||
---------------------------------
|
||||
|
||||
#### Files and directories
|
||||
|
||||
Fuzzy completion for files and directories can be triggered if the word before
|
||||
the cursor ends with the trigger sequence, which is by default `**`.
|
||||
|
||||
- `COMMAND [DIRECTORY/][FUZZY_PATTERN]**<TAB>`
|
||||
|
||||
```sh
|
||||
# Files under the current directory
|
||||
# - You can select multiple items with TAB key
|
||||
vim **<TAB>
|
||||
|
||||
# Files under parent directory
|
||||
vim ../**<TAB>
|
||||
|
||||
# Files under parent directory that match `fzf`
|
||||
vim ../fzf**<TAB>
|
||||
|
||||
# Files under your home directory
|
||||
vim ~/**<TAB>
|
||||
|
||||
|
||||
# Directories under current directory (single-selection)
|
||||
cd **<TAB>
|
||||
|
||||
# Directories under ~/github that match `fzf`
|
||||
cd ~/github/fzf**<TAB>
|
||||
```
|
||||
|
||||
#### Process IDs
|
||||
|
||||
Fuzzy completion for PIDs is provided for kill command. In this case,
|
||||
there is no trigger sequence; just press the tab key after the kill command.
|
||||
|
||||
```sh
|
||||
# Can select multiple processes with <TAB> or <Shift-TAB> keys
|
||||
kill -9 <TAB>
|
||||
```
|
||||
|
||||
#### Host names
|
||||
|
||||
For ssh and telnet commands, fuzzy completion for hostnames is provided. The
|
||||
names are extracted from /etc/hosts and ~/.ssh/config.
|
||||
|
||||
```sh
|
||||
ssh **<TAB>
|
||||
telnet **<TAB>
|
||||
```
|
||||
|
||||
#### Environment variables / Aliases
|
||||
|
||||
```sh
|
||||
unset **<TAB>
|
||||
export **<TAB>
|
||||
unalias **<TAB>
|
||||
```
|
||||
|
||||
#### Settings
|
||||
|
||||
```sh
|
||||
# Use ~~ as the trigger sequence instead of the default **
|
||||
export FZF_COMPLETION_TRIGGER='~~'
|
||||
|
||||
# Options to fzf command
|
||||
export FZF_COMPLETION_OPTS='--border --info=inline'
|
||||
|
||||
# Use fd (https://github.com/sharkdp/fd) instead of the default find
|
||||
# command for listing path candidates.
|
||||
# - The first argument to the function ($1) is the base path to start traversal
|
||||
# - See the source code (completion.{bash,zsh}) for the details.
|
||||
_fzf_compgen_path() {
|
||||
fd --hidden --follow --exclude ".git" . "$1"
|
||||
}
|
||||
|
||||
# Use fd to generate the list for directory completion
|
||||
_fzf_compgen_dir() {
|
||||
fd --type d --hidden --follow --exclude ".git" . "$1"
|
||||
}
|
||||
|
||||
# (EXPERIMENTAL) Advanced customization of fzf options via _fzf_comprun function
|
||||
# - The first argument to the function is the name of the command.
|
||||
# - You should make sure to pass the rest of the arguments to fzf.
|
||||
_fzf_comprun() {
|
||||
local command=$1
|
||||
shift
|
||||
|
||||
case "$command" in
|
||||
cd) fzf "$@" --preview 'tree -C {} | head -200' ;;
|
||||
export|unset) fzf "$@" --preview "eval 'echo \$'{}" ;;
|
||||
ssh) fzf "$@" --preview 'dig {}' ;;
|
||||
*) fzf "$@" ;;
|
||||
esac
|
||||
}
|
||||
```
|
||||
|
||||
#### Supported commands
|
||||
|
||||
On bash, fuzzy completion is enabled only for a predefined set of commands
|
||||
(`complete | grep _fzf` to see the list). But you can enable it for other
|
||||
commands as well by using `_fzf_setup_completion` helper function.
|
||||
|
||||
```sh
|
||||
# usage: _fzf_setup_completion path|dir|var|alias|host COMMANDS...
|
||||
_fzf_setup_completion path ag git kubectl
|
||||
_fzf_setup_completion dir tree
|
||||
```
|
||||
|
||||
#### Custom fuzzy completion
|
||||
|
||||
_**(Custom completion API is experimental and subject to change)**_
|
||||
|
||||
For a command named _"COMMAND"_, define `_fzf_complete_COMMAND` function using
|
||||
`_fzf_complete` helper.
|
||||
|
||||
```sh
|
||||
# Custom fuzzy completion for "doge" command
|
||||
# e.g. doge **<TAB>
|
||||
_fzf_complete_doge() {
|
||||
_fzf_complete --multi --reverse --prompt="doge> " -- "$@" < <(
|
||||
echo very
|
||||
echo wow
|
||||
echo such
|
||||
echo doge
|
||||
)
|
||||
}
|
||||
```
|
||||
|
||||
- The arguments before `--` are the options to fzf.
|
||||
- After `--`, simply pass the original completion arguments unchanged (`"$@"`).
|
||||
- Then, write a set of commands that generates the completion candidates and
|
||||
feed its output to the function using process substitution (`< <(...)`).
|
||||
|
||||
zsh will automatically pick up the function using the naming convention but in
|
||||
bash you have to manually associate the function with the command using the
|
||||
`complete` command.
|
||||
|
||||
```sh
|
||||
[ -n "$BASH" ] && complete -F _fzf_complete_doge -o default -o bashdefault doge
|
||||
```
|
||||
|
||||
If you need to post-process the output from fzf, define
|
||||
`_fzf_complete_COMMAND_post` as follows.
|
||||
|
||||
```sh
|
||||
_fzf_complete_foo() {
|
||||
_fzf_complete --multi --reverse --header-lines=3 -- "$@" < <(
|
||||
ls -al
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_foo_post() {
|
||||
awk '{print $NF}'
|
||||
}
|
||||
|
||||
[ -n "$BASH" ] && complete -F _fzf_complete_foo -o default -o bashdefault foo
|
||||
```
|
||||
|
||||
Vim plugin
|
||||
----------
|
||||
|
||||
See [README-VIM.md](README-VIM.md).
|
||||
|
||||
Advanced topics
|
||||
---------------
|
||||
|
||||
### Performance
|
||||
|
||||
fzf is fast and is [getting even faster][perf]. Performance should not be
|
||||
a problem in most use cases. However, you might want to be aware of the
|
||||
options that affect performance.
|
||||
|
||||
- `--ansi` tells fzf to extract and parse ANSI color codes in the input, and it
|
||||
makes the initial scanning slower. So it's not recommended that you add it
|
||||
to your `$FZF_DEFAULT_OPTS`.
|
||||
- `--nth` makes fzf slower because it has to tokenize each line.
|
||||
- `--with-nth` makes fzf slower as fzf has to tokenize and reassemble each
|
||||
line.
|
||||
- If you absolutely need better performance, you can consider using
|
||||
`--algo=v1` (the default being `v2`) to make fzf use a faster greedy
|
||||
algorithm. However, this algorithm is not guaranteed to find the optimal
|
||||
ordering of the matches and is not recommended.
|
||||
|
||||
[perf]: https://junegunn.kr/images/fzf-0.17.0.png
|
||||
|
||||
### Executing external programs
|
||||
|
||||
You can set up key bindings for starting external processes without leaving
|
||||
fzf (`execute`, `execute-silent`).
|
||||
|
||||
```bash
|
||||
# Press F1 to open the file with less without leaving fzf
|
||||
# Press CTRL-Y to copy the line to clipboard and aborts fzf (requires pbcopy)
|
||||
fzf --bind 'f1:execute(less -f {}),ctrl-y:execute-silent(echo {} | pbcopy)+abort'
|
||||
```
|
||||
|
||||
See *KEY BINDINGS* section of the man page for details.
|
||||
|
||||
### Reloading the candidate list
|
||||
|
||||
By binding `reload` action to a key or an event, you can make fzf dynamically
|
||||
reload the candidate list. See https://github.com/junegunn/fzf/issues/1750 for
|
||||
more details.
|
||||
|
||||
#### 1. Update the list of processes by pressing CTRL-R
|
||||
|
||||
```sh
|
||||
FZF_DEFAULT_COMMAND='ps -ef' \
|
||||
fzf --bind 'ctrl-r:reload($FZF_DEFAULT_COMMAND)' \
|
||||
--header 'Press CTRL-R to reload' --header-lines=1 \
|
||||
--height=50% --layout=reverse
|
||||
```
|
||||
|
||||
#### 2. Switch between sources by pressing CTRL-D or CTRL-F
|
||||
|
||||
```sh
|
||||
FZF_DEFAULT_COMMAND='find . -type f' \
|
||||
fzf --bind 'ctrl-d:reload(find . -type d),ctrl-f:reload($FZF_DEFAULT_COMMAND)' \
|
||||
--height=50% --layout=reverse
|
||||
```
|
||||
|
||||
#### 3. Interactive ripgrep integration
|
||||
|
||||
The following example uses fzf as the selector interface for ripgrep. We bound
|
||||
`reload` action to `change` event, so every time you type on fzf, the ripgrep
|
||||
process will restart with the updated query string denoted by the placeholder
|
||||
expression `{q}`. Also, note that we used `--disabled` option so that fzf
|
||||
doesn't perform any secondary filtering.
|
||||
|
||||
```sh
|
||||
INITIAL_QUERY=""
|
||||
RG_PREFIX="rg --column --line-number --no-heading --color=always --smart-case "
|
||||
FZF_DEFAULT_COMMAND="$RG_PREFIX '$INITIAL_QUERY'" \
|
||||
fzf --bind "change:reload:$RG_PREFIX {q} || true" \
|
||||
--ansi --disabled --query "$INITIAL_QUERY" \
|
||||
--height=50% --layout=reverse
|
||||
```
|
||||
|
||||
If ripgrep doesn't find any matches, it will exit with a non-zero exit status,
|
||||
and fzf will warn you about it. To suppress the warning message, we added
|
||||
`|| true` to the command, so that it always exits with 0.
|
||||
|
||||
### Preview window
|
||||
|
||||
When the `--preview` option is set, fzf automatically starts an external process
|
||||
with the current line as the argument and shows the result in the split window.
|
||||
Your `$SHELL` is used to execute the command with `$SHELL -c COMMAND`.
|
||||
The window can be scrolled using the mouse or custom key bindings.
|
||||
|
||||
```bash
|
||||
# {} is replaced with the single-quoted string of the focused line
|
||||
fzf --preview 'cat {}'
|
||||
```
|
||||
|
||||
Preview window supports ANSI colors, so you can use any program that
|
||||
syntax-highlights the content of a file, such as
|
||||
[Bat](https://github.com/sharkdp/bat) or
|
||||
[Highlight](http://www.andre-simon.de/doku/highlight/en/highlight.php):
|
||||
|
||||
```bash
|
||||
fzf --preview 'bat --style=numbers --color=always --line-range :500 {}'
|
||||
```
|
||||
|
||||
You can customize the size, position, and border of the preview window using
|
||||
`--preview-window` option, and the foreground and background color of it with
|
||||
`--color` option. For example,
|
||||
|
||||
```bash
|
||||
fzf --height 40% --layout reverse --info inline --border \
|
||||
--preview 'file {}' --preview-window up,1,border-horizontal \
|
||||
--color 'fg:#bbccdd,fg+:#ddeeff,bg:#334455,preview-bg:#223344,border:#778899'
|
||||
```
|
||||
|
||||
See the man page (`man fzf`) for the full list of options.
|
||||
|
||||
For more advanced examples, see [Key bindings for git with fzf][fzf-git]
|
||||
([code](https://gist.github.com/junegunn/8b572b8d4b5eddd8b85e5f4d40f17236)).
|
||||
|
||||
[fzf-git]: https://junegunn.kr/2016/07/fzf-git/
|
||||
|
||||
----
|
||||
|
||||
Since fzf is a general-purpose text filter rather than a file finder, **it is
|
||||
not a good idea to add `--preview` option to your `$FZF_DEFAULT_OPTS`**.
|
||||
|
||||
```sh
|
||||
# *********************
|
||||
# ** DO NOT DO THIS! **
|
||||
# *********************
|
||||
export FZF_DEFAULT_OPTS='--preview "bat --style=numbers --color=always --line-range :500 {}"'
|
||||
|
||||
# bat doesn't work with any input other than the list of files
|
||||
ps -ef | fzf
|
||||
seq 100 | fzf
|
||||
history | fzf
|
||||
```
|
||||
|
||||
Tips
|
||||
----
|
||||
|
||||
#### Respecting `.gitignore`
|
||||
|
||||
You can use [fd](https://github.com/sharkdp/fd),
|
||||
[ripgrep](https://github.com/BurntSushi/ripgrep), or [the silver
|
||||
searcher](https://github.com/ggreer/the_silver_searcher) instead of the
|
||||
default find command to traverse the file system while respecting
|
||||
`.gitignore`.
|
||||
|
||||
```sh
|
||||
# Feed the output of fd into fzf
|
||||
fd --type f | fzf
|
||||
|
||||
# Setting fd as the default source for fzf
|
||||
export FZF_DEFAULT_COMMAND='fd --type f'
|
||||
|
||||
# Now fzf (w/o pipe) will use fd instead of find
|
||||
fzf
|
||||
|
||||
# To apply the command to CTRL-T as well
|
||||
export FZF_CTRL_T_COMMAND="$FZF_DEFAULT_COMMAND"
|
||||
```
|
||||
|
||||
If you want the command to follow symbolic links and don't want it to exclude
|
||||
hidden files, use the following command:
|
||||
|
||||
```sh
|
||||
export FZF_DEFAULT_COMMAND='fd --type f --hidden --follow --exclude .git'
|
||||
```
|
||||
|
||||
#### Fish shell
|
||||
|
||||
`CTRL-T` key binding of fish, unlike those of bash and zsh, will use the last
|
||||
token on the command-line as the root directory for the recursive search. For
|
||||
instance, hitting `CTRL-T` at the end of the following command-line
|
||||
|
||||
```sh
|
||||
ls /var/
|
||||
```
|
||||
|
||||
will list all files and directories under `/var/`.
|
||||
|
||||
When using a custom `FZF_CTRL_T_COMMAND`, use the unexpanded `$dir` variable to
|
||||
make use of this feature. `$dir` defaults to `.` when the last token is not a
|
||||
valid directory. Example:
|
||||
|
||||
```sh
|
||||
set -g FZF_CTRL_T_COMMAND "command find -L \$dir -type f 2> /dev/null | sed '1d; s#^\./##'"
|
||||
```
|
||||
|
||||
Related projects
|
||||
----------------
|
||||
|
||||
https://github.com/junegunn/fzf/wiki/Related-projects
|
||||
|
||||
[License](LICENSE)
|
||||
------------------
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
@ -1,233 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
# fzf-tmux: starts fzf in a tmux pane
|
||||
# usage: fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
|
||||
fail() {
|
||||
>&2 echo "$1"
|
||||
exit 2
|
||||
}
|
||||
|
||||
fzf="$(command -v fzf 2> /dev/null)" || fzf="$(dirname "$0")/fzf"
|
||||
[[ -x "$fzf" ]] || fail 'fzf executable not found'
|
||||
|
||||
tmux_args=()
|
||||
args=()
|
||||
opt=""
|
||||
skip=""
|
||||
swap=""
|
||||
close=""
|
||||
term=""
|
||||
[[ -n "$LINES" ]] && lines=$LINES || lines=$(tput lines) || lines=$(tmux display-message -p "#{pane_height}")
|
||||
[[ -n "$COLUMNS" ]] && columns=$COLUMNS || columns=$(tput cols) || columns=$(tmux display-message -p "#{pane_width}")
|
||||
|
||||
help() {
|
||||
>&2 echo 'usage: fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
|
||||
LAYOUT OPTIONS:
|
||||
(default layout: -d 50%)
|
||||
|
||||
Popup window (requires tmux 3.2 or above):
|
||||
-p [WIDTH[%][,HEIGHT[%]]] (default: 50%)
|
||||
-w WIDTH[%]
|
||||
-h HEIGHT[%]
|
||||
-x COL
|
||||
-y ROW
|
||||
|
||||
Split pane:
|
||||
-u [HEIGHT[%]] Split above (up)
|
||||
-d [HEIGHT[%]] Split below (down)
|
||||
-l [WIDTH[%]] Split left
|
||||
-r [WIDTH[%]] Split right
|
||||
'
|
||||
exit
|
||||
}
|
||||
|
||||
while [[ $# -gt 0 ]]; do
|
||||
arg="$1"
|
||||
shift
|
||||
[[ -z "$skip" ]] && case "$arg" in
|
||||
-)
|
||||
term=1
|
||||
;;
|
||||
--help)
|
||||
help
|
||||
;;
|
||||
--version)
|
||||
echo "fzf-tmux (with fzf $("$fzf" --version))"
|
||||
exit
|
||||
;;
|
||||
-p*|-w*|-h*|-x*|-y*|-d*|-u*|-r*|-l*)
|
||||
if [[ "$arg" =~ ^-[pwhxy] ]]; then
|
||||
[[ "$opt" =~ "-K -E" ]] || opt="-K -E"
|
||||
elif [[ "$arg" =~ ^.[lr] ]]; then
|
||||
opt="-h"
|
||||
if [[ "$arg" =~ ^.l ]]; then
|
||||
opt="$opt -d"
|
||||
swap="; swap-pane -D ; select-pane -L"
|
||||
close="; tmux swap-pane -D"
|
||||
fi
|
||||
else
|
||||
opt=""
|
||||
if [[ "$arg" =~ ^.u ]]; then
|
||||
opt="$opt -d"
|
||||
swap="; swap-pane -D ; select-pane -U"
|
||||
close="; tmux swap-pane -D"
|
||||
fi
|
||||
fi
|
||||
if [[ ${#arg} -gt 2 ]]; then
|
||||
size="${arg:2}"
|
||||
else
|
||||
if [[ "$1" =~ ^[0-9%,]+$ ]] || [[ "$1" =~ ^[A-Z]$ ]]; then
|
||||
size="$1"
|
||||
shift
|
||||
else
|
||||
continue
|
||||
fi
|
||||
fi
|
||||
|
||||
if [[ "$arg" =~ ^-p ]]; then
|
||||
if [[ -n "$size" ]]; then
|
||||
w=${size%%,*}
|
||||
h=${size##*,}
|
||||
opt="$opt -w$w -h$h"
|
||||
fi
|
||||
elif [[ "$arg" =~ ^-[whxy] ]]; then
|
||||
opt="$opt ${arg:0:2}$size"
|
||||
elif [[ "$size" =~ %$ ]]; then
|
||||
size=${size:0:((${#size}-1))}
|
||||
if [[ -n "$swap" ]]; then
|
||||
opt="$opt -p $(( 100 - size ))"
|
||||
else
|
||||
opt="$opt -p $size"
|
||||
fi
|
||||
else
|
||||
if [[ -n "$swap" ]]; then
|
||||
if [[ "$arg" =~ ^.l ]]; then
|
||||
max=$columns
|
||||
else
|
||||
max=$lines
|
||||
fi
|
||||
size=$(( max - size ))
|
||||
[[ $size -lt 0 ]] && size=0
|
||||
opt="$opt -l $size"
|
||||
else
|
||||
opt="$opt -l $size"
|
||||
fi
|
||||
fi
|
||||
;;
|
||||
--)
|
||||
# "--" can be used to separate fzf-tmux options from fzf options to
|
||||
# avoid conflicts
|
||||
skip=1
|
||||
tmux_args=("${args[@]}")
|
||||
args=()
|
||||
continue
|
||||
;;
|
||||
*)
|
||||
args+=("$arg")
|
||||
;;
|
||||
esac
|
||||
[[ -n "$skip" ]] && args+=("$arg")
|
||||
done
|
||||
|
||||
if [[ -z "$TMUX" ]]; then
|
||||
"$fzf" "${args[@]}"
|
||||
exit $?
|
||||
fi
|
||||
|
||||
# --height option is not allowed. CTRL-Z is also disabled.
|
||||
args=("${args[@]}" "--no-height" "--bind=ctrl-z:ignore")
|
||||
|
||||
# Handle zoomed tmux pane without popup options by moving it to a temp window
|
||||
if [[ ! "$opt" =~ "-K -E" ]] && tmux list-panes -F '#F' | grep -q Z; then
|
||||
zoomed_without_popup=1
|
||||
original_window=$(tmux display-message -p "#{window_id}")
|
||||
tmp_window=$(tmux new-window -d -P -F "#{window_id}" "bash -c 'while :; do for c in \\| / - '\\;' do sleep 0.2; printf \"\\r\$c fzf-tmux is running\\r\"; done; done'")
|
||||
tmux swap-pane -t $tmp_window \; select-window -t $tmp_window
|
||||
fi
|
||||
|
||||
set -e
|
||||
|
||||
# Clean up named pipes on exit
|
||||
id=$RANDOM
|
||||
argsf="${TMPDIR:-/tmp}/fzf-args-$id"
|
||||
fifo1="${TMPDIR:-/tmp}/fzf-fifo1-$id"
|
||||
fifo2="${TMPDIR:-/tmp}/fzf-fifo2-$id"
|
||||
fifo3="${TMPDIR:-/tmp}/fzf-fifo3-$id"
|
||||
tmux_win_opts=( $(tmux show-window-options remain-on-exit \; show-window-options synchronize-panes | sed '/ off/d; s/^/set-window-option /; s/$/ \\;/') )
|
||||
cleanup() {
|
||||
\rm -f $argsf $fifo1 $fifo2 $fifo3
|
||||
|
||||
# Restore tmux window options
|
||||
if [[ "${#tmux_win_opts[@]}" -gt 0 ]]; then
|
||||
eval "tmux ${tmux_win_opts[*]}"
|
||||
fi
|
||||
|
||||
# Remove temp window if we were zoomed without popup options
|
||||
if [[ -n "$zoomed_without_popup" ]]; then
|
||||
tmux display-message -p "#{window_id}" > /dev/null
|
||||
tmux swap-pane -t $original_window \; \
|
||||
select-window -t $original_window \; \
|
||||
kill-window -t $tmp_window \; \
|
||||
resize-pane -Z
|
||||
fi
|
||||
|
||||
if [[ $# -gt 0 ]]; then
|
||||
trap - EXIT
|
||||
exit 130
|
||||
fi
|
||||
}
|
||||
trap 'cleanup 1' SIGUSR1
|
||||
trap 'cleanup' EXIT
|
||||
|
||||
envs="export TERM=$TERM "
|
||||
[[ "$opt" =~ "-K -E" ]] && FZF_DEFAULT_OPTS="--margin 0,1 $FZF_DEFAULT_OPTS"
|
||||
[[ -n "$FZF_DEFAULT_OPTS" ]] && envs="$envs FZF_DEFAULT_OPTS=$(printf %q "$FZF_DEFAULT_OPTS")"
|
||||
[[ -n "$FZF_DEFAULT_COMMAND" ]] && envs="$envs FZF_DEFAULT_COMMAND=$(printf %q "$FZF_DEFAULT_COMMAND")"
|
||||
echo "$envs;" > "$argsf"
|
||||
|
||||
# Build arguments to fzf
|
||||
opts=$(printf "%q " "${args[@]}")
|
||||
|
||||
pppid=$$
|
||||
echo -n "trap 'kill -SIGUSR1 -$pppid' EXIT SIGINT SIGTERM;" >> $argsf
|
||||
close="; trap - EXIT SIGINT SIGTERM $close"
|
||||
|
||||
export TMUX=$(cut -d , -f 1,2 <<< "$TMUX")
|
||||
mkfifo -m o+w $fifo2
|
||||
if [[ "$opt" =~ "-K -E" ]]; then
|
||||
cat $fifo2 &
|
||||
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||
cat <<< "\"$fzf\" $opts > $fifo2; out=\$? $close; exit \$out" >> $argsf
|
||||
else
|
||||
mkfifo $fifo1
|
||||
cat <<< "\"$fzf\" $opts < $fifo1 > $fifo2; out=\$? $close; exit \$out" >> $argsf
|
||||
cat <&0 > $fifo1 &
|
||||
fi
|
||||
|
||||
# tmux dropped the support for `-K`, `-R` to popup command
|
||||
# TODO: We can remove this once tmux 3.2 is released
|
||||
if [[ ! "$(tmux popup --help 2>&1)" =~ '-R shell-command' ]]; then
|
||||
opt="${opt/-K/}"
|
||||
else
|
||||
opt="${opt} -R"
|
||||
fi
|
||||
|
||||
tmux popup -d "$PWD" "${tmux_args[@]}" $opt "bash $argsf" > /dev/null 2>&1
|
||||
exit $?
|
||||
fi
|
||||
|
||||
mkfifo -m o+w $fifo3
|
||||
if [[ -n "$term" ]] || [[ -t 0 ]]; then
|
||||
cat <<< "\"$fzf\" $opts > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
||||
else
|
||||
mkfifo $fifo1
|
||||
cat <<< "\"$fzf\" $opts < $fifo1 > $fifo2; echo \$? > $fifo3 $close" >> $argsf
|
||||
cat <&0 > $fifo1 &
|
||||
fi
|
||||
tmux set-window-option synchronize-panes off \;\
|
||||
set-window-option remain-on-exit off \;\
|
||||
split-window -c "$PWD" $opt "${tmux_args[@]}" "bash -c 'exec -a fzf bash $argsf'" $swap \
|
||||
> /dev/null 2>&1 || { "$fzf" "${args[@]}"; exit $?; }
|
||||
cat $fifo2
|
||||
exit "$(cat $fifo3)"
|
||||
512
.fzf/doc/fzf.txt
512
.fzf/doc/fzf.txt
@ -1,512 +0,0 @@
|
||||
fzf.txt fzf Last change: May 19 2021
|
||||
FZF - TABLE OF CONTENTS *fzf* *fzf-toc*
|
||||
==============================================================================
|
||||
|
||||
FZF Vim integration |fzf-vim-integration|
|
||||
Installation |fzf-installation|
|
||||
Summary |fzf-summary|
|
||||
:FZF[!] |:FZF|
|
||||
Configuration |fzf-configuration|
|
||||
Examples |fzf-examples|
|
||||
Explanation of g:fzf_colors |fzf-explanation-of-gfzfcolors|
|
||||
fzf#run |fzf#run|
|
||||
fzf#wrap |fzf#wrap|
|
||||
Global options supported by fzf#wrap |fzf-global-options-supported-by-fzf#wrap|
|
||||
Tips |fzf-tips|
|
||||
fzf inside terminal buffer |fzf-inside-terminal-buffer|
|
||||
Starting fzf in a popup window |fzf-starting-fzf-in-a-popup-window|
|
||||
Hide statusline |fzf-hide-statusline|
|
||||
License |fzf-license|
|
||||
|
||||
FZF VIM INTEGRATION *fzf-vim-integration*
|
||||
==============================================================================
|
||||
|
||||
|
||||
INSTALLATION *fzf-installation*
|
||||
==============================================================================
|
||||
|
||||
Once you have fzf installed, you can enable it inside Vim simply by adding the
|
||||
directory to 'runtimepath' in your Vim configuration file. The path may differ
|
||||
depending on the package manager.
|
||||
>
|
||||
" If installed using Homebrew
|
||||
set rtp+=/usr/local/opt/fzf
|
||||
|
||||
" If installed using git
|
||||
set rtp+=~/.fzf
|
||||
<
|
||||
If you use {vim-plug}{1}, the same can be written as:
|
||||
>
|
||||
" If installed using Homebrew
|
||||
Plug '/usr/local/opt/fzf'
|
||||
|
||||
" If installed using git
|
||||
Plug '~/.fzf'
|
||||
<
|
||||
But if you want the latest Vim plugin file from GitHub rather than the one
|
||||
included in the package, write:
|
||||
>
|
||||
Plug 'junegunn/fzf'
|
||||
<
|
||||
The Vim plugin will pick up fzf binary available on the system. If fzf is not
|
||||
found on `$PATH`, it will ask you if it should download the latest binary for
|
||||
you.
|
||||
|
||||
To make sure that you have the latest version of the binary, set up
|
||||
post-update hook like so:
|
||||
|
||||
*fzf#install*
|
||||
>
|
||||
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } }
|
||||
<
|
||||
{1} https://github.com/junegunn/vim-plug
|
||||
|
||||
|
||||
SUMMARY *fzf-summary*
|
||||
==============================================================================
|
||||
|
||||
The Vim plugin of fzf provides two core functions, and `:FZF` command which is
|
||||
the basic file selector command built on top of them.
|
||||
|
||||
1. `fzf#run([spec dict])`
|
||||
- Starts fzf inside Vim with the given spec
|
||||
- `:call fzf#run({'source': 'ls'})`
|
||||
2. `fzf#wrap([spec dict]) -> (dict)`
|
||||
- Takes a spec for `fzf#run` and returns an extended version of it with
|
||||
additional options for addressing global preferences (`g:fzf_xxx`)
|
||||
- `:echo fzf#wrap({'source': 'ls'})`
|
||||
- We usually wrap a spec with `fzf#wrap` before passing it to `fzf#run`
|
||||
- `:call fzf#run(fzf#wrap({'source': 'ls'}))`
|
||||
3. `:FZF [fzf_options string] [path string]`
|
||||
- Basic fuzzy file selector
|
||||
- A reference implementation for those who don't want to write VimScript to
|
||||
implement custom commands
|
||||
- If you're looking for more such commands, check out {fzf.vim}{2} project.
|
||||
|
||||
The most important of all is `fzf#run`, but it would be easier to understand
|
||||
the whole if we start off with `:FZF` command.
|
||||
|
||||
{2} https://github.com/junegunn/fzf.vim
|
||||
|
||||
|
||||
:FZF[!]
|
||||
==============================================================================
|
||||
|
||||
*:FZF*
|
||||
>
|
||||
" Look for files under current directory
|
||||
:FZF
|
||||
|
||||
" Look for files under your home directory
|
||||
:FZF ~
|
||||
|
||||
" With fzf command-line options
|
||||
:FZF --reverse --info=inline /tmp
|
||||
|
||||
" Bang version starts fzf in fullscreen mode
|
||||
:FZF!
|
||||
<
|
||||
Similarly to {ctrlp.vim}{3}, use enter key, CTRL-T, CTRL-X or CTRL-V to open
|
||||
selected files in the current window, in new tabs, in horizontal splits, or in
|
||||
vertical splits respectively.
|
||||
|
||||
Note that the environment variables `FZF_DEFAULT_COMMAND` and
|
||||
`FZF_DEFAULT_OPTS` also apply here.
|
||||
|
||||
{3} https://github.com/kien/ctrlp.vim
|
||||
|
||||
|
||||
< Configuration >_____________________________________________________________~
|
||||
*fzf-configuration*
|
||||
|
||||
*g:fzf_action* *g:fzf_layout* *g:fzf_colors* *g:fzf_history_dir*
|
||||
|
||||
- `g:fzf_action`
|
||||
- Customizable extra key bindings for opening selected files in different
|
||||
ways
|
||||
- `g:fzf_layout`
|
||||
- Determines the size and position of fzf window
|
||||
- `g:fzf_colors`
|
||||
- Customizes fzf colors to match the current color scheme
|
||||
- `g:fzf_history_dir`
|
||||
- Enables history feature
|
||||
|
||||
|
||||
Examples~
|
||||
*fzf-examples*
|
||||
>
|
||||
" This is the default extra key bindings
|
||||
let g:fzf_action = {
|
||||
\ 'ctrl-t': 'tab split',
|
||||
\ 'ctrl-x': 'split',
|
||||
\ 'ctrl-v': 'vsplit' }
|
||||
|
||||
" An action can be a reference to a function that processes selected lines
|
||||
function! s:build_quickfix_list(lines)
|
||||
call setqflist(map(copy(a:lines), '{ "filename": v:val }'))
|
||||
copen
|
||||
cc
|
||||
endfunction
|
||||
|
||||
let g:fzf_action = {
|
||||
\ 'ctrl-q': function('s:build_quickfix_list'),
|
||||
\ 'ctrl-t': 'tab split',
|
||||
\ 'ctrl-x': 'split',
|
||||
\ 'ctrl-v': 'vsplit' }
|
||||
|
||||
" Default fzf layout
|
||||
" - Popup window (center of the screen)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
|
||||
" - Popup window (center of the current window)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6, 'relative': v:true } }
|
||||
|
||||
" - Popup window (anchored to the bottom of the current window)
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6, 'relative': v:true, 'yoffset': 1.0 } }
|
||||
|
||||
" - down / up / left / right
|
||||
let g:fzf_layout = { 'down': '40%' }
|
||||
|
||||
" - Window using a Vim command
|
||||
let g:fzf_layout = { 'window': 'enew' }
|
||||
let g:fzf_layout = { 'window': '-tabnew' }
|
||||
let g:fzf_layout = { 'window': '10new' }
|
||||
|
||||
" Customize fzf colors to match your color scheme
|
||||
" - fzf#wrap translates this to a set of `--color` options
|
||||
let g:fzf_colors =
|
||||
\ { 'fg': ['fg', 'Normal'],
|
||||
\ 'bg': ['bg', 'Normal'],
|
||||
\ 'hl': ['fg', 'Comment'],
|
||||
\ 'fg+': ['fg', 'CursorLine', 'CursorColumn', 'Normal'],
|
||||
\ 'bg+': ['bg', 'CursorLine', 'CursorColumn'],
|
||||
\ 'hl+': ['fg', 'Statement'],
|
||||
\ 'info': ['fg', 'PreProc'],
|
||||
\ 'border': ['fg', 'Ignore'],
|
||||
\ 'prompt': ['fg', 'Conditional'],
|
||||
\ 'pointer': ['fg', 'Exception'],
|
||||
\ 'marker': ['fg', 'Keyword'],
|
||||
\ 'spinner': ['fg', 'Label'],
|
||||
\ 'header': ['fg', 'Comment'] }
|
||||
|
||||
" Enable per-command history
|
||||
" - History files will be stored in the specified directory
|
||||
" - When set, CTRL-N and CTRL-P will be bound to 'next-history' and
|
||||
" 'previous-history' instead of 'down' and 'up'.
|
||||
let g:fzf_history_dir = '~/.local/share/fzf-history'
|
||||
<
|
||||
|
||||
Explanation of g:fzf_colors~
|
||||
*fzf-explanation-of-gfzfcolors*
|
||||
|
||||
`g:fzf_colors` is a dictionary mapping fzf elements to a color specification
|
||||
list:
|
||||
>
|
||||
element: [ component, group1 [, group2, ...] ]
|
||||
<
|
||||
- `element` is an fzf element to apply a color to:
|
||||
|
||||
----------------------------+------------------------------------------------------
|
||||
Element | Description ~
|
||||
----------------------------+------------------------------------------------------
|
||||
`fg` / `bg` / `hl` | Item (foreground / background / highlight)
|
||||
`fg+` / `bg+` / `hl+` | Current item (foreground / background / highlight)
|
||||
`preview-fg` / `preview-bg` | Preview window text and background
|
||||
`hl` / `hl+` | Highlighted substrings (normal / current)
|
||||
`gutter` | Background of the gutter on the left
|
||||
`pointer` | Pointer to the current line ( `>` )
|
||||
`marker` | Multi-select marker ( `>` )
|
||||
`border` | Border around the window ( `--border` and `--preview` )
|
||||
`header` | Header ( `--header` or `--header-lines` )
|
||||
`info` | Info line (match counters)
|
||||
`spinner` | Streaming input indicator
|
||||
`query` | Query string
|
||||
`disabled` | Query string when search is disabled
|
||||
`prompt` | Prompt before query ( `> ` )
|
||||
`pointer` | Pointer to the current line ( `>` )
|
||||
----------------------------+------------------------------------------------------
|
||||
- `component` specifies the component (`fg` / `bg`) from which to extract the
|
||||
color when considering each of the following highlight groups
|
||||
- `group1 [, group2, ...]` is a list of highlight groups that are searched (in
|
||||
order) for a matching color definition
|
||||
|
||||
For example, consider the following specification:
|
||||
>
|
||||
'prompt': ['fg', 'Conditional', 'Comment'],
|
||||
<
|
||||
This means we color the prompt - using the `fg` attribute of the `Conditional`
|
||||
if it exists, - otherwise use the `fg` attribute of the `Comment` highlight
|
||||
group if it exists, - otherwise fall back to the default color settings for
|
||||
the prompt.
|
||||
|
||||
You can examine the color option generated according the setting by printing
|
||||
the result of `fzf#wrap()` function like so:
|
||||
>
|
||||
:echo fzf#wrap()
|
||||
<
|
||||
|
||||
FZF#RUN
|
||||
==============================================================================
|
||||
|
||||
*fzf#run*
|
||||
|
||||
`fzf#run()` function is the core of Vim integration. It takes a single
|
||||
dictionary argument, a spec, and starts fzf process accordingly. At the very
|
||||
least, specify `sink` option to tell what it should do with the selected
|
||||
entry.
|
||||
>
|
||||
call fzf#run({'sink': 'e'})
|
||||
<
|
||||
We haven't specified the `source`, so this is equivalent to starting fzf on
|
||||
command line without standard input pipe; fzf will use find command (or
|
||||
`$FZF_DEFAULT_COMMAND` if defined) to list the files under the current
|
||||
directory. When you select one, it will open it with the sink, `:e` command.
|
||||
If you want to open it in a new tab, you can pass `:tabedit` command instead
|
||||
as the sink.
|
||||
>
|
||||
call fzf#run({'sink': 'tabedit'})
|
||||
<
|
||||
Instead of using the default find command, you can use any shell command as
|
||||
the source. The following example will list the files managed by git. It's
|
||||
equivalent to running `git ls-files | fzf` on shell.
|
||||
>
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e'})
|
||||
<
|
||||
fzf options can be specified as `options` entry in spec dictionary.
|
||||
>
|
||||
call fzf#run({'sink': 'tabedit', 'options': '--multi --reverse'})
|
||||
<
|
||||
You can also pass a layout option if you don't want fzf window to take up the
|
||||
entire screen.
|
||||
>
|
||||
" up / down / left / right / window are allowed
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e', 'left': '40%'})
|
||||
call fzf#run({'source': 'git ls-files', 'sink': 'e', 'window': '30vnew'})
|
||||
<
|
||||
`source` doesn't have to be an external shell command, you can pass a Vim
|
||||
array as the source. In the next example, we pass the names of color schemes
|
||||
as the source to implement a color scheme selector.
|
||||
>
|
||||
call fzf#run({'source': map(split(globpath(&rtp, 'colors/*.vim')),
|
||||
\ 'fnamemodify(v:val, ":t:r")'),
|
||||
\ 'sink': 'colo', 'left': '25%'})
|
||||
<
|
||||
The following table summarizes the available options.
|
||||
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
Option name | Type | Description ~
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
`source` | string | External command to generate input to fzf (e.g. `find .` )
|
||||
`source` | list | Vim list as input to fzf
|
||||
`sink` | string | Vim command to handle the selected item (e.g. `e` , `tabe` )
|
||||
`sink` | funcref | Reference to function to process each selected item
|
||||
`sinklist` (or `sink*` ) | funcref | Similar to `sink` , but takes the list of output lines at once
|
||||
`options` | string/list | Options to fzf
|
||||
`dir` | string | Working directory
|
||||
`up` / `down` / `left` / `right` | number/string | (Layout) Window position and size (e.g. `20` , `50%` )
|
||||
`tmux` | string | (Layout) fzf-tmux options (e.g. `-p90%,60%` )
|
||||
`window` (Vim 8 / Neovim) | string | (Layout) Command to open fzf window (e.g. `vertical aboveleft 30new` )
|
||||
`window` (Vim 8 / Neovim) | dict | (Layout) Popup window settings (e.g. `{'width': 0.9, 'height': 0.6}` )
|
||||
---------------------------+---------------+----------------------------------------------------------------------
|
||||
|
||||
`options` entry can be either a string or a list. For simple cases, string
|
||||
should suffice, but prefer to use list type to avoid escaping issues.
|
||||
>
|
||||
call fzf#run({'options': '--reverse --prompt "C:\\Program Files\\"'})
|
||||
call fzf#run({'options': ['--reverse', '--prompt', 'C:\Program Files\']})
|
||||
<
|
||||
When `window` entry is a dictionary, fzf will start in a popup window. The
|
||||
following options are allowed:
|
||||
|
||||
- Required:
|
||||
- `width` [float range [0 ~ 1]] or [integer range [8 ~ ]]
|
||||
- `height` [float range [0 ~ 1]] or [integer range [4 ~ ]]
|
||||
- Optional:
|
||||
- `yoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `xoffset` [float default 0.5 range [0 ~ 1]]
|
||||
- `relative` [boolean default v:false]
|
||||
- `border` [string default `rounded`]: Border style
|
||||
- `rounded` / `sharp` / `horizontal` / `vertical` / `top` / `bottom` / `left` / `right` / `no[ne]`
|
||||
|
||||
|
||||
FZF#WRAP
|
||||
==============================================================================
|
||||
|
||||
*fzf#wrap*
|
||||
|
||||
We have seen that several aspects of `:FZF` command can be configured with a
|
||||
set of global option variables; different ways to open files (`g:fzf_action`),
|
||||
window position and size (`g:fzf_layout`), color palette (`g:fzf_colors`),
|
||||
etc.
|
||||
|
||||
So how can we make our custom `fzf#run` calls also respect those variables?
|
||||
Simply by "wrapping" the spec dictionary with `fzf#wrap` before passing it to
|
||||
`fzf#run`.
|
||||
|
||||
- `fzf#wrap([name string], [spec dict], [fullscreen bool]) -> (dict)`
|
||||
- All arguments are optional. Usually we only need to pass a spec
|
||||
dictionary.
|
||||
- `name` is for managing history files. It is ignored if `g:fzf_history_dir`
|
||||
is not defined.
|
||||
- `fullscreen` can be either `0` or `1` (default: 0).
|
||||
|
||||
`fzf#wrap` takes a spec and returns an extended version of it (also a
|
||||
dictionary) with additional options for addressing global preferences. You can
|
||||
examine the return value of it like so:
|
||||
>
|
||||
echo fzf#wrap({'source': 'ls'})
|
||||
<
|
||||
After we "wrap" our spec, we pass it to `fzf#run`.
|
||||
>
|
||||
call fzf#run(fzf#wrap({'source': 'ls'}))
|
||||
<
|
||||
Now it supports CTRL-T, CTRL-V, and CTRL-X key bindings (configurable via
|
||||
`g:fzf_action`) and it opens fzf window according to `g:fzf_layout` setting.
|
||||
|
||||
To make it easier to use, let's define `LS` command.
|
||||
>
|
||||
command! LS call fzf#run(fzf#wrap({'source': 'ls'}))
|
||||
<
|
||||
Type `:LS` and see how it works.
|
||||
|
||||
We would like to make `:LS!` (bang version) open fzf in fullscreen, just like
|
||||
`:FZF!`. Add `-bang` to command definition, and use <bang> value to set the
|
||||
last `fullscreen` argument of `fzf#wrap` (see :help <bang>).
|
||||
>
|
||||
" On :LS!, <bang> evaluates to '!', and '!0' becomes 1
|
||||
command! -bang LS call fzf#run(fzf#wrap({'source': 'ls'}, <bang>0))
|
||||
<
|
||||
Our `:LS` command will be much more useful if we can pass a directory argument
|
||||
to it, so that something like `:LS /tmp` is possible.
|
||||
>
|
||||
command! -bang -complete=dir -nargs=? LS
|
||||
\ call fzf#run(fzf#wrap({'source': 'ls', 'dir': <q-args>}, <bang>0))
|
||||
<
|
||||
Lastly, if you have enabled `g:fzf_history_dir`, you might want to assign a
|
||||
unique name to our command and pass it as the first argument to `fzf#wrap`.
|
||||
>
|
||||
" The query history for this command will be stored as 'ls' inside g:fzf_history_dir.
|
||||
" The name is ignored if g:fzf_history_dir is not defined.
|
||||
command! -bang -complete=dir -nargs=? LS
|
||||
\ call fzf#run(fzf#wrap('ls', {'source': 'ls', 'dir': <q-args>}, <bang>0))
|
||||
<
|
||||
|
||||
< Global options supported by fzf#wrap >______________________________________~
|
||||
*fzf-global-options-supported-by-fzf#wrap*
|
||||
|
||||
- `g:fzf_layout`
|
||||
- `g:fzf_action`
|
||||
- Works only when no custom `sink` (or `sink*`) is provided
|
||||
- Having custom sink usually means that each entry is not an ordinary
|
||||
file path (e.g. name of color scheme), so we can't blindly apply the
|
||||
same strategy (i.e. `tabedit some-color-scheme` doesn't make sense)
|
||||
- `g:fzf_colors`
|
||||
- `g:fzf_history_dir`
|
||||
|
||||
|
||||
TIPS *fzf-tips*
|
||||
==============================================================================
|
||||
|
||||
|
||||
< fzf inside terminal buffer >________________________________________________~
|
||||
*fzf-inside-terminal-buffer*
|
||||
|
||||
The latest versions of Vim and Neovim include builtin terminal emulator
|
||||
(`:terminal`) and fzf will start in a terminal buffer in the following cases:
|
||||
|
||||
- On Neovim
|
||||
- On GVim
|
||||
- On Terminal Vim with a non-default layout
|
||||
- `call fzf#run({'left': '30%'})` or `let g:fzf_layout = {'left': '30%'}`
|
||||
|
||||
On the latest versions of Vim and Neovim, fzf will start in a terminal buffer.
|
||||
If you find the default ANSI colors to be different, consider configuring the
|
||||
colors using `g:terminal_ansi_colors` in regular Vim or `g:terminal_color_x`
|
||||
in Neovim.
|
||||
|
||||
*g:terminal_color_15* *g:terminal_color_14* *g:terminal_color_13*
|
||||
*g:terminal_color_12* *g:terminal_color_11* *g:terminal_color_10* *g:terminal_color_9*
|
||||
*g:terminal_color_8* *g:terminal_color_7* *g:terminal_color_6* *g:terminal_color_5*
|
||||
*g:terminal_color_4* *g:terminal_color_3* *g:terminal_color_2* *g:terminal_color_1*
|
||||
*g:terminal_color_0*
|
||||
>
|
||||
" Terminal colors for seoul256 color scheme
|
||||
if has('nvim')
|
||||
let g:terminal_color_0 = '#4e4e4e'
|
||||
let g:terminal_color_1 = '#d68787'
|
||||
let g:terminal_color_2 = '#5f865f'
|
||||
let g:terminal_color_3 = '#d8af5f'
|
||||
let g:terminal_color_4 = '#85add4'
|
||||
let g:terminal_color_5 = '#d7afaf'
|
||||
let g:terminal_color_6 = '#87afaf'
|
||||
let g:terminal_color_7 = '#d0d0d0'
|
||||
let g:terminal_color_8 = '#626262'
|
||||
let g:terminal_color_9 = '#d75f87'
|
||||
let g:terminal_color_10 = '#87af87'
|
||||
let g:terminal_color_11 = '#ffd787'
|
||||
let g:terminal_color_12 = '#add4fb'
|
||||
let g:terminal_color_13 = '#ffafaf'
|
||||
let g:terminal_color_14 = '#87d7d7'
|
||||
let g:terminal_color_15 = '#e4e4e4'
|
||||
else
|
||||
let g:terminal_ansi_colors = [
|
||||
\ '#4e4e4e', '#d68787', '#5f865f', '#d8af5f',
|
||||
\ '#85add4', '#d7afaf', '#87afaf', '#d0d0d0',
|
||||
\ '#626262', '#d75f87', '#87af87', '#ffd787',
|
||||
\ '#add4fb', '#ffafaf', '#87d7d7', '#e4e4e4'
|
||||
\ ]
|
||||
endif
|
||||
<
|
||||
|
||||
< Starting fzf in a popup window >____________________________________________~
|
||||
*fzf-starting-fzf-in-a-popup-window*
|
||||
>
|
||||
" Required:
|
||||
" - width [float range [0 ~ 1]] or [integer range [8 ~ ]]
|
||||
" - height [float range [0 ~ 1]] or [integer range [4 ~ ]]
|
||||
"
|
||||
" Optional:
|
||||
" - xoffset [float default 0.5 range [0 ~ 1]]
|
||||
" - yoffset [float default 0.5 range [0 ~ 1]]
|
||||
" - relative [boolean default v:false]
|
||||
" - border [string default 'rounded']: Border style
|
||||
" - 'rounded' / 'sharp' / 'horizontal' / 'vertical' / 'top' / 'bottom' / 'left' / 'right'
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
<
|
||||
Alternatively, you can make fzf open in a tmux popup window (requires tmux 3.2
|
||||
or above) by putting fzf-tmux options in `tmux` key.
|
||||
>
|
||||
" See `man fzf-tmux` for available options
|
||||
if exists('$TMUX')
|
||||
let g:fzf_layout = { 'tmux': '-p90%,60%' }
|
||||
else
|
||||
let g:fzf_layout = { 'window': { 'width': 0.9, 'height': 0.6 } }
|
||||
endif
|
||||
<
|
||||
|
||||
< Hide statusline >___________________________________________________________~
|
||||
*fzf-hide-statusline*
|
||||
|
||||
When fzf starts in a terminal buffer, the file type of the buffer is set to
|
||||
`fzf`. So you can set up `FileType fzf` autocmd to customize the settings of
|
||||
the window.
|
||||
|
||||
For example, if you open fzf on the bottom on the screen (e.g. `{'down':
|
||||
'40%'}`), you might want to temporarily disable the statusline for a cleaner
|
||||
look.
|
||||
>
|
||||
let g:fzf_layout = { 'down': '30%' }
|
||||
autocmd! FileType fzf
|
||||
autocmd FileType fzf set laststatus=0 noshowmode noruler
|
||||
\| autocmd BufLeave <buffer> set laststatus=2 showmode ruler
|
||||
<
|
||||
|
||||
LICENSE *fzf-license*
|
||||
==============================================================================
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
==============================================================================
|
||||
vim:tw=78:sw=2:ts=2:ft=help:norl:nowrap:
|
||||
17
.fzf/go.mod
17
.fzf/go.mod
@ -1,17 +0,0 @@
|
||||
module github.com/junegunn/fzf
|
||||
|
||||
require (
|
||||
github.com/gdamore/tcell v1.4.0
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0 // indirect
|
||||
github.com/mattn/go-isatty v0.0.14
|
||||
github.com/mattn/go-runewidth v0.0.13
|
||||
github.com/mattn/go-shellwords v1.0.12
|
||||
github.com/rivo/uniseg v0.2.0
|
||||
github.com/saracen/walker v0.1.2
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c // indirect
|
||||
golang.org/x/sys v0.0.0-20210630005230-0f9fa26af87c
|
||||
golang.org/x/term v0.0.0-20210317153231-de623e64d2a6
|
||||
golang.org/x/text v0.3.6 // indirect
|
||||
)
|
||||
|
||||
go 1.13
|
||||
31
.fzf/go.sum
31
.fzf/go.sum
@ -1,31 +0,0 @@
|
||||
github.com/gdamore/encoding v1.0.0 h1:+7OoQ1Bc6eTm5niUzBa0Ctsh6JbMW6Ra+YNuAtDBdko=
|
||||
github.com/gdamore/encoding v1.0.0/go.mod h1:alR0ol34c49FCSBLjhosxzcPHQbf2trDkoo5dl+VrEg=
|
||||
github.com/gdamore/tcell v1.4.0 h1:vUnHwJRvcPQa3tzi+0QI4U9JINXYJlOz9yiaiPQ2wMU=
|
||||
github.com/gdamore/tcell v1.4.0/go.mod h1:vxEiSDZdW3L+Uhjii9c3375IlDmR05bzxY404ZVSMo0=
|
||||
github.com/lucasb-eyer/go-colorful v1.0.3/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0 h1:1nnpGOrhyZZuNyfu1QjKiUICQ74+3FNCN69Aj6K7nkY=
|
||||
github.com/lucasb-eyer/go-colorful v1.2.0/go.mod h1:R4dSotOR9KMtayYi1e77YzuveK+i7ruzyGqttikkLy0=
|
||||
github.com/mattn/go-isatty v0.0.14 h1:yVuAays6BHfxijgZPzw+3Zlu5yQgKGP2/hcQbHb7S9Y=
|
||||
github.com/mattn/go-isatty v0.0.14/go.mod h1:7GGIvUiUoEMVVmxf/4nioHXj79iQHKdU27kJ6hsGG94=
|
||||
github.com/mattn/go-runewidth v0.0.7/go.mod h1:H031xJmbD/WCDINGzjvQ9THkh0rPKHF+m2gUSrubnMI=
|
||||
github.com/mattn/go-runewidth v0.0.13 h1:lTGmDsbAYt5DmK6OnoV7EuIF1wEIFAcxld6ypU4OSgU=
|
||||
github.com/mattn/go-runewidth v0.0.13/go.mod h1:Jdepj2loyihRzMpdS35Xk/zdY8IAYHsh153qUoGf23w=
|
||||
github.com/mattn/go-shellwords v1.0.12 h1:M2zGm7EW6UQJvDeQxo4T51eKPurbeFbe8WtebGE2xrk=
|
||||
github.com/mattn/go-shellwords v1.0.12/go.mod h1:EZzvwXDESEeg03EKmM+RmDnNOPKG4lLtQsUlTZDWQ8Y=
|
||||
github.com/rivo/uniseg v0.2.0 h1:S1pD9weZBuJdFmowNwbpi7BJ8TNftyUImj/0WQi72jY=
|
||||
github.com/rivo/uniseg v0.2.0/go.mod h1:J6wj4VEh+S6ZtnVlnTBMWIodfgj8LQOQFoIToxlJtxc=
|
||||
github.com/saracen/walker v0.1.2 h1:/o1TxP82n8thLvmL4GpJXduYaRmJ7qXp8u9dSlV0zmo=
|
||||
github.com/saracen/walker v0.1.2/go.mod h1:0oKYMsKVhSJ+ful4p/XbjvXbMgLEkLITZaxozsl4CGE=
|
||||
golang.org/x/sync v0.0.0-20200317015054-43a5402ce75a/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c h1:5KslGYwFpkhGh+Q16bwMP3cOontH8FOep7tGV86Y7SQ=
|
||||
golang.org/x/sync v0.0.0-20210220032951-036812b2e83c/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||
golang.org/x/sys v0.0.0-20190626150813-e07cf5db2756/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||
golang.org/x/sys v0.0.0-20210630005230-0f9fa26af87c h1:F1jZWGFhYfh0Ci55sIpILtKKK8p3i2/krTr0H1rg74I=
|
||||
golang.org/x/sys v0.0.0-20210630005230-0f9fa26af87c/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||
golang.org/x/term v0.0.0-20210317153231-de623e64d2a6 h1:EC6+IGYTjPpRfv9a2b/6Puw0W+hLtAhkV1tPsXhutqs=
|
||||
golang.org/x/term v0.0.0-20210317153231-de623e64d2a6/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||
golang.org/x/text v0.3.6 h1:aRYxNxv6iGQlyVaZmk6ZgYEDa+Jg18DxebPSrd6bg1M=
|
||||
golang.org/x/text v0.3.6/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||
382
.fzf/install
382
.fzf/install
@ -1,382 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
set -u
|
||||
|
||||
version=0.28.0
|
||||
auto_completion=
|
||||
key_bindings=
|
||||
update_config=2
|
||||
shells="bash zsh fish"
|
||||
prefix='~/.fzf'
|
||||
prefix_expand=~/.fzf
|
||||
fish_dir=${XDG_CONFIG_HOME:-$HOME/.config}/fish
|
||||
|
||||
help() {
|
||||
cat << EOF
|
||||
usage: $0 [OPTIONS]
|
||||
|
||||
--help Show this message
|
||||
--bin Download fzf binary only; Do not generate ~/.fzf.{bash,zsh}
|
||||
--all Download fzf binary and update configuration files
|
||||
to enable key bindings and fuzzy completion
|
||||
--xdg Generate files under \$XDG_CONFIG_HOME/fzf
|
||||
--[no-]key-bindings Enable/disable key bindings (CTRL-T, CTRL-R, ALT-C)
|
||||
--[no-]completion Enable/disable fuzzy completion (bash & zsh)
|
||||
--[no-]update-rc Whether or not to update shell configuration files
|
||||
|
||||
--no-bash Do not set up bash configuration
|
||||
--no-zsh Do not set up zsh configuration
|
||||
--no-fish Do not set up fish configuration
|
||||
EOF
|
||||
}
|
||||
|
||||
for opt in "$@"; do
|
||||
case $opt in
|
||||
--help)
|
||||
help
|
||||
exit 0
|
||||
;;
|
||||
--all)
|
||||
auto_completion=1
|
||||
key_bindings=1
|
||||
update_config=1
|
||||
;;
|
||||
--xdg)
|
||||
prefix='"${XDG_CONFIG_HOME:-$HOME/.config}"/fzf/fzf'
|
||||
prefix_expand=${XDG_CONFIG_HOME:-$HOME/.config}/fzf/fzf
|
||||
mkdir -p "${XDG_CONFIG_HOME:-$HOME/.config}/fzf"
|
||||
;;
|
||||
--key-bindings) key_bindings=1 ;;
|
||||
--no-key-bindings) key_bindings=0 ;;
|
||||
--completion) auto_completion=1 ;;
|
||||
--no-completion) auto_completion=0 ;;
|
||||
--update-rc) update_config=1 ;;
|
||||
--no-update-rc) update_config=0 ;;
|
||||
--bin) ;;
|
||||
--no-bash) shells=${shells/bash/} ;;
|
||||
--no-zsh) shells=${shells/zsh/} ;;
|
||||
--no-fish) shells=${shells/fish/} ;;
|
||||
*)
|
||||
echo "unknown option: $opt"
|
||||
help
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
cd "$(dirname "${BASH_SOURCE[0]}")"
|
||||
fzf_base=$(pwd)
|
||||
fzf_base_esc=$(printf %q "$fzf_base")
|
||||
|
||||
ask() {
|
||||
while true; do
|
||||
read -p "$1 ([y]/n) " -r
|
||||
REPLY=${REPLY:-"y"}
|
||||
if [[ $REPLY =~ ^[Yy]$ ]]; then
|
||||
return 1
|
||||
elif [[ $REPLY =~ ^[Nn]$ ]]; then
|
||||
return 0
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
check_binary() {
|
||||
echo -n " - Checking fzf executable ... "
|
||||
local output
|
||||
output=$("$fzf_base"/bin/fzf --version 2>&1)
|
||||
if [ $? -ne 0 ]; then
|
||||
echo "Error: $output"
|
||||
binary_error="Invalid binary"
|
||||
else
|
||||
output=${output/ */}
|
||||
if [ "$version" != "$output" ]; then
|
||||
echo "$output != $version"
|
||||
binary_error="Invalid version"
|
||||
else
|
||||
echo "$output"
|
||||
binary_error=""
|
||||
return 0
|
||||
fi
|
||||
fi
|
||||
rm -f "$fzf_base"/bin/fzf
|
||||
return 1
|
||||
}
|
||||
|
||||
link_fzf_in_path() {
|
||||
if which_fzf="$(command -v fzf)"; then
|
||||
echo " - Found in \$PATH"
|
||||
echo " - Creating symlink: bin/fzf -> $which_fzf"
|
||||
(cd "$fzf_base"/bin && rm -f fzf && ln -sf "$which_fzf" fzf)
|
||||
check_binary && return
|
||||
fi
|
||||
return 1
|
||||
}
|
||||
|
||||
try_curl() {
|
||||
command -v curl > /dev/null &&
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
curl -fL $1 | tar -xzf -
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
curl -fLo "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
}
|
||||
|
||||
try_wget() {
|
||||
command -v wget > /dev/null &&
|
||||
if [[ $1 =~ tar.gz$ ]]; then
|
||||
wget -O - $1 | tar -xzf -
|
||||
else
|
||||
local temp=${TMPDIR:-/tmp}/fzf.zip
|
||||
wget -O "$temp" $1 && unzip -o "$temp" && rm -f "$temp"
|
||||
fi
|
||||
}
|
||||
|
||||
download() {
|
||||
echo "Downloading bin/fzf ..."
|
||||
if [ -x "$fzf_base"/bin/fzf ]; then
|
||||
echo " - Already exists"
|
||||
check_binary && return
|
||||
fi
|
||||
link_fzf_in_path && return
|
||||
mkdir -p "$fzf_base"/bin && cd "$fzf_base"/bin
|
||||
if [ $? -ne 0 ]; then
|
||||
binary_error="Failed to create bin directory"
|
||||
return
|
||||
fi
|
||||
|
||||
local url
|
||||
url=https://github.com/junegunn/fzf/releases/download/$version/${1}
|
||||
set -o pipefail
|
||||
if ! (try_curl $url || try_wget $url); then
|
||||
set +o pipefail
|
||||
binary_error="Failed to download with curl and wget"
|
||||
return
|
||||
fi
|
||||
set +o pipefail
|
||||
|
||||
if [ ! -f fzf ]; then
|
||||
binary_error="Failed to download ${1}"
|
||||
return
|
||||
fi
|
||||
|
||||
chmod +x fzf && check_binary
|
||||
}
|
||||
|
||||
# Try to download binary executable
|
||||
archi=$(uname -sm)
|
||||
binary_available=1
|
||||
binary_error=""
|
||||
case "$archi" in
|
||||
Darwin\ arm64) download fzf-$version-darwin_arm64.zip ;;
|
||||
Darwin\ x86_64) download fzf-$version-darwin_amd64.zip ;;
|
||||
Linux\ armv5*) download fzf-$version-linux_armv5.tar.gz ;;
|
||||
Linux\ armv6*) download fzf-$version-linux_armv6.tar.gz ;;
|
||||
Linux\ armv7*) download fzf-$version-linux_armv7.tar.gz ;;
|
||||
Linux\ armv8*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ aarch64*) download fzf-$version-linux_arm64.tar.gz ;;
|
||||
Linux\ *64) download fzf-$version-linux_amd64.tar.gz ;;
|
||||
FreeBSD\ *64) download fzf-$version-freebsd_amd64.tar.gz ;;
|
||||
OpenBSD\ *64) download fzf-$version-openbsd_amd64.tar.gz ;;
|
||||
CYGWIN*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
MINGW*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
MSYS*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
Windows*\ *64) download fzf-$version-windows_amd64.zip ;;
|
||||
*) binary_available=0 binary_error=1 ;;
|
||||
esac
|
||||
|
||||
cd "$fzf_base"
|
||||
if [ -n "$binary_error" ]; then
|
||||
if [ $binary_available -eq 0 ]; then
|
||||
echo "No prebuilt binary for $archi ..."
|
||||
else
|
||||
echo " - $binary_error !!!"
|
||||
fi
|
||||
if command -v go > /dev/null; then
|
||||
echo -n "Building binary (go get -u github.com/junegunn/fzf) ... "
|
||||
if [ -z "${GOPATH-}" ]; then
|
||||
export GOPATH="${TMPDIR:-/tmp}/fzf-gopath"
|
||||
mkdir -p "$GOPATH"
|
||||
fi
|
||||
if go get -ldflags "-s -w -X main.version=$version -X main.revision=go-get" github.com/junegunn/fzf; then
|
||||
echo "OK"
|
||||
cp "$GOPATH/bin/fzf" "$fzf_base/bin/"
|
||||
else
|
||||
echo "Failed to build binary. Installation failed."
|
||||
exit 1
|
||||
fi
|
||||
else
|
||||
echo "go executable not found. Installation failed."
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
[[ "$*" =~ "--bin" ]] && exit 0
|
||||
|
||||
for s in $shells; do
|
||||
if ! command -v "$s" > /dev/null; then
|
||||
shells=${shells/$s/}
|
||||
fi
|
||||
done
|
||||
|
||||
if [[ ${#shells} -lt 3 ]]; then
|
||||
echo "No shell configuration to be updated."
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Auto-completion
|
||||
if [ -z "$auto_completion" ]; then
|
||||
ask "Do you want to enable fuzzy auto-completion?"
|
||||
auto_completion=$?
|
||||
fi
|
||||
|
||||
# Key-bindings
|
||||
if [ -z "$key_bindings" ]; then
|
||||
ask "Do you want to enable key bindings?"
|
||||
key_bindings=$?
|
||||
fi
|
||||
|
||||
echo
|
||||
for shell in $shells; do
|
||||
[[ "$shell" = fish ]] && continue
|
||||
src=${prefix_expand}.${shell}
|
||||
echo -n "Generate $src ... "
|
||||
|
||||
fzf_completion="[[ \$- == *i* ]] && source \"$fzf_base/shell/completion.${shell}\" 2> /dev/null"
|
||||
if [ $auto_completion -eq 0 ]; then
|
||||
fzf_completion="# $fzf_completion"
|
||||
fi
|
||||
|
||||
fzf_key_bindings="source \"$fzf_base/shell/key-bindings.${shell}\""
|
||||
if [ $key_bindings -eq 0 ]; then
|
||||
fzf_key_bindings="# $fzf_key_bindings"
|
||||
fi
|
||||
|
||||
cat > "$src" << EOF
|
||||
# Setup fzf
|
||||
# ---------
|
||||
if [[ ! "\$PATH" == *$fzf_base_esc/bin* ]]; then
|
||||
export PATH="\${PATH:+\${PATH}:}$fzf_base/bin"
|
||||
fi
|
||||
|
||||
# Auto-completion
|
||||
# ---------------
|
||||
$fzf_completion
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
$fzf_key_bindings
|
||||
EOF
|
||||
echo "OK"
|
||||
done
|
||||
|
||||
# fish
|
||||
if [[ "$shells" =~ fish ]]; then
|
||||
echo -n "Update fish_user_paths ... "
|
||||
fish << EOF
|
||||
echo \$fish_user_paths | \grep "$fzf_base"/bin > /dev/null
|
||||
or set --universal fish_user_paths \$fish_user_paths "$fzf_base"/bin
|
||||
EOF
|
||||
[ $? -eq 0 ] && echo "OK" || echo "Failed"
|
||||
|
||||
mkdir -p "${fish_dir}/functions"
|
||||
if [ -e "${fish_dir}/functions/fzf.fish" ]; then
|
||||
echo -n "Remove unnecessary ${fish_dir}/functions/fzf.fish ... "
|
||||
rm -f "${fish_dir}/functions/fzf.fish" && echo "OK" || echo "Failed"
|
||||
fi
|
||||
|
||||
fish_binding="${fish_dir}/functions/fzf_key_bindings.fish"
|
||||
if [ $key_bindings -ne 0 ]; then
|
||||
echo -n "Symlink $fish_binding ... "
|
||||
ln -sf "$fzf_base/shell/key-bindings.fish" \
|
||||
"$fish_binding" && echo "OK" || echo "Failed"
|
||||
else
|
||||
echo -n "Removing $fish_binding ... "
|
||||
rm -f "$fish_binding"
|
||||
echo "OK"
|
||||
fi
|
||||
fi
|
||||
|
||||
append_line() {
|
||||
set -e
|
||||
|
||||
local update line file pat lno
|
||||
update="$1"
|
||||
line="$2"
|
||||
file="$3"
|
||||
pat="${4:-}"
|
||||
lno=""
|
||||
|
||||
echo "Update $file:"
|
||||
echo " - $line"
|
||||
if [ -f "$file" ]; then
|
||||
if [ $# -lt 4 ]; then
|
||||
lno=$(\grep -nF "$line" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
else
|
||||
lno=$(\grep -nF "$pat" "$file" | sed 's/:.*//' | tr '\n' ' ')
|
||||
fi
|
||||
fi
|
||||
if [ -n "$lno" ]; then
|
||||
echo " - Already exists: line #$lno"
|
||||
else
|
||||
if [ $update -eq 1 ]; then
|
||||
[ -f "$file" ] && echo >> "$file"
|
||||
echo "$line" >> "$file"
|
||||
echo " + Added"
|
||||
else
|
||||
echo " ~ Skipped"
|
||||
fi
|
||||
fi
|
||||
echo
|
||||
set +e
|
||||
}
|
||||
|
||||
create_file() {
|
||||
local file="$1"
|
||||
shift
|
||||
echo "Create $file:"
|
||||
for line in "$@"; do
|
||||
echo " $line"
|
||||
echo "$line" >> "$file"
|
||||
done
|
||||
echo
|
||||
}
|
||||
|
||||
if [ $update_config -eq 2 ]; then
|
||||
echo
|
||||
ask "Do you want to update your shell configuration files?"
|
||||
update_config=$?
|
||||
fi
|
||||
echo
|
||||
for shell in $shells; do
|
||||
[[ "$shell" = fish ]] && continue
|
||||
[ $shell = zsh ] && dest=${ZDOTDIR:-~}/.zshrc || dest=~/.bashrc
|
||||
append_line $update_config "[ -f ${prefix}.${shell} ] && source ${prefix}.${shell}" "$dest" "${prefix}.${shell}"
|
||||
done
|
||||
|
||||
if [ $key_bindings -eq 1 ] && [[ "$shells" =~ fish ]]; then
|
||||
bind_file="${fish_dir}/functions/fish_user_key_bindings.fish"
|
||||
if [ ! -e "$bind_file" ]; then
|
||||
create_file "$bind_file" \
|
||||
'function fish_user_key_bindings' \
|
||||
' fzf_key_bindings' \
|
||||
'end'
|
||||
else
|
||||
append_line $update_config "fzf_key_bindings" "$bind_file"
|
||||
fi
|
||||
fi
|
||||
|
||||
if [ $update_config -eq 1 ]; then
|
||||
echo 'Finished. Restart your shell or reload config file.'
|
||||
if [[ "$shells" =~ bash ]]; then
|
||||
echo -n ' source ~/.bashrc # bash'
|
||||
[[ "$archi" =~ Darwin ]] && echo -n ' (.bashrc should be loaded from .bash_profile)'
|
||||
echo
|
||||
fi
|
||||
[[ "$shells" =~ zsh ]] && echo " source ${ZDOTDIR:-~}/.zshrc # zsh"
|
||||
[[ "$shells" =~ fish ]] && [ $key_bindings -eq 1 ] && echo ' fzf_key_bindings # fish'
|
||||
echo
|
||||
echo 'Use uninstall script to remove fzf.'
|
||||
echo
|
||||
fi
|
||||
echo 'For more information, see: https://github.com/junegunn/fzf'
|
||||
@ -1,65 +0,0 @@
|
||||
$version="0.28.0"
|
||||
|
||||
$fzf_base=Split-Path -Parent $MyInvocation.MyCommand.Definition
|
||||
|
||||
function check_binary () {
|
||||
Write-Host " - Checking fzf executable ... " -NoNewline
|
||||
$output=cmd /c $fzf_base\bin\fzf.exe --version 2>&1
|
||||
if (-not $?) {
|
||||
Write-Host "Error: $output"
|
||||
$binary_error="Invalid binary"
|
||||
} else {
|
||||
$output=(-Split $output)[0]
|
||||
if ($version -ne $output) {
|
||||
Write-Host "$output != $version"
|
||||
$binary_error="Invalid version"
|
||||
} else {
|
||||
Write-Host "$output"
|
||||
$binary_error=""
|
||||
return 1
|
||||
}
|
||||
}
|
||||
Remove-Item "$fzf_base\bin\fzf.exe"
|
||||
return 0
|
||||
}
|
||||
|
||||
function download {
|
||||
param($file)
|
||||
Write-Host "Downloading bin/fzf ..."
|
||||
if (Test-Path "$fzf_base\bin\fzf.exe") {
|
||||
Write-Host " - Already exists"
|
||||
if (check_binary) {
|
||||
return
|
||||
}
|
||||
}
|
||||
if (-not (Test-Path "$fzf_base\bin")) {
|
||||
md "$fzf_base\bin"
|
||||
}
|
||||
if (-not $?) {
|
||||
$binary_error="Failed to create bin directory"
|
||||
return
|
||||
}
|
||||
cd "$fzf_base\bin"
|
||||
$url="https://github.com/junegunn/fzf/releases/download/$version/$file"
|
||||
$temp=$env:TMP + "\fzf.zip"
|
||||
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
|
||||
if ($PSVersionTable.PSVersion.Major -ge 3) {
|
||||
Invoke-WebRequest -Uri $url -OutFile $temp
|
||||
} else {
|
||||
(New-Object Net.WebClient).DownloadFile($url, $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath("$temp"))
|
||||
}
|
||||
if ($?) {
|
||||
(Microsoft.PowerShell.Archive\Expand-Archive -Path $temp -DestinationPath .); (Remove-Item $temp)
|
||||
} else {
|
||||
$binary_error="Failed to download with powershell"
|
||||
}
|
||||
if (-not (Test-Path fzf.exe)) {
|
||||
$binary_error="Failed to download $file"
|
||||
return
|
||||
}
|
||||
echo y | icacls $fzf_base\bin\fzf.exe /grant Administrator:F ; check_binary >$null
|
||||
}
|
||||
|
||||
download "fzf-$version-windows_amd64.zip"
|
||||
|
||||
Write-Host 'For more information, see: https://github.com/junegunn/fzf'
|
||||
14
.fzf/main.go
14
.fzf/main.go
@ -1,14 +0,0 @@
|
||||
package main
|
||||
|
||||
import (
|
||||
fzf "github.com/junegunn/fzf/src"
|
||||
"github.com/junegunn/fzf/src/protector"
|
||||
)
|
||||
|
||||
var version string = "0.28"
|
||||
var revision string = "devel"
|
||||
|
||||
func main() {
|
||||
protector.Protect()
|
||||
fzf.Run(fzf.ParseOptions(), version, revision)
|
||||
}
|
||||
@ -1,68 +0,0 @@
|
||||
.ig
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
..
|
||||
.TH fzf-tmux 1 "Nov 2021" "fzf 0.28.0" "fzf-tmux - open fzf in tmux split pane"
|
||||
|
||||
.SH NAME
|
||||
fzf-tmux - open fzf in tmux split pane
|
||||
|
||||
.SH SYNOPSIS
|
||||
.B fzf-tmux [LAYOUT OPTIONS] [--] [FZF OPTIONS]
|
||||
|
||||
.SH DESCRIPTION
|
||||
fzf-tmux is a wrapper script for fzf that opens fzf in a tmux split pane or in
|
||||
a tmux popup window. It is designed to work just like fzf except that it does
|
||||
not take up the whole screen. You can safely use fzf-tmux instead of fzf in
|
||||
your scripts as the extra options will be silently ignored if you're not on
|
||||
tmux.
|
||||
|
||||
.SH LAYOUT OPTIONS
|
||||
|
||||
(default layout: \fB-d 50%\fR)
|
||||
|
||||
.SS Popup window
|
||||
(requires tmux 3.2 or above)
|
||||
.TP
|
||||
.B "-p [WIDTH[%][,HEIGHT[%]]]"
|
||||
.TP
|
||||
.B "-w WIDTH[%]"
|
||||
.TP
|
||||
.B "-h WIDTH[%]"
|
||||
.TP
|
||||
.B "-x COL"
|
||||
.TP
|
||||
.B "-y ROW"
|
||||
|
||||
.SS Split pane
|
||||
.TP
|
||||
.B "-u [height[%]]"
|
||||
Split above (up)
|
||||
.TP
|
||||
.B "-d [height[%]]"
|
||||
Split below (down)
|
||||
.TP
|
||||
.B "-l [width[%]]"
|
||||
Split left
|
||||
.TP
|
||||
.B "-r [width[%]]"
|
||||
Split right
|
||||
1001
.fzf/man/man1/fzf.1
1001
.fzf/man/man1/fzf.1
File diff suppressed because it is too large
Load Diff
1048
.fzf/plugin/fzf.vim
1048
.fzf/plugin/fzf.vim
File diff suppressed because it is too large
Load Diff
@ -1,381 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.bash
|
||||
#
|
||||
# - $FZF_TMUX (default: 0)
|
||||
# - $FZF_TMUX_OPTS (default: empty)
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
|
||||
if [[ $- =~ i ]]; then
|
||||
|
||||
# To use custom commands instead of find, override _fzf_compgen_{path,dir}
|
||||
if ! declare -f _fzf_compgen_path > /dev/null; then
|
||||
_fzf_compgen_path() {
|
||||
echo "$1"
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
if ! declare -f _fzf_compgen_dir > /dev/null; then
|
||||
_fzf_compgen_dir() {
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
###########################################################
|
||||
|
||||
# To redraw line after fzf closes (printf '\e[5n')
|
||||
bind '"\e[0n": redraw-current-line' 2> /dev/null
|
||||
|
||||
__fzf_comprun() {
|
||||
if [[ "$(type -t _fzf_comprun 2>&1)" = function ]]; then
|
||||
_fzf_comprun "$@"
|
||||
elif [[ -n "$TMUX_PANE" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "$FZF_TMUX_OPTS" ]]; }; then
|
||||
shift
|
||||
fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- "$@"
|
||||
else
|
||||
shift
|
||||
fzf "$@"
|
||||
fi
|
||||
}
|
||||
|
||||
__fzf_orig_completion() {
|
||||
local l comp f cmd
|
||||
while read -r l; do
|
||||
if [[ "$l" =~ ^(.*\ -F)\ *([^ ]*).*\ ([^ ]*)$ ]]; then
|
||||
comp="${BASH_REMATCH[1]}"
|
||||
f="${BASH_REMATCH[2]}"
|
||||
cmd="${BASH_REMATCH[3]}"
|
||||
[[ "$f" = _fzf_* ]] && continue
|
||||
printf -v "_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}" "%s" "${comp} %s ${cmd} #${f}"
|
||||
if [[ "$l" = *" -o nospace "* ]] && [[ ! "$__fzf_nospace_commands" = *" $cmd "* ]]; then
|
||||
__fzf_nospace_commands="$__fzf_nospace_commands $cmd "
|
||||
fi
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
_fzf_opts_completion() {
|
||||
local cur prev opts
|
||||
COMPREPLY=()
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
prev="${COMP_WORDS[COMP_CWORD-1]}"
|
||||
opts="
|
||||
-x --extended
|
||||
-e --exact
|
||||
--algo
|
||||
-i +i
|
||||
-n --nth
|
||||
--with-nth
|
||||
-d --delimiter
|
||||
+s --no-sort
|
||||
--tac
|
||||
--tiebreak
|
||||
-m --multi
|
||||
--no-mouse
|
||||
--bind
|
||||
--cycle
|
||||
--no-hscroll
|
||||
--jump-labels
|
||||
--height
|
||||
--literal
|
||||
--reverse
|
||||
--margin
|
||||
--inline-info
|
||||
--prompt
|
||||
--pointer
|
||||
--marker
|
||||
--header
|
||||
--header-lines
|
||||
--ansi
|
||||
--tabstop
|
||||
--color
|
||||
--no-bold
|
||||
--history
|
||||
--history-size
|
||||
--preview
|
||||
--preview-window
|
||||
-q --query
|
||||
-1 --select-1
|
||||
-0 --exit-0
|
||||
-f --filter
|
||||
--print-query
|
||||
--expect
|
||||
--sync"
|
||||
|
||||
case "${prev}" in
|
||||
--tiebreak)
|
||||
COMPREPLY=( $(compgen -W "length begin end index" -- "$cur") )
|
||||
return 0
|
||||
;;
|
||||
--color)
|
||||
COMPREPLY=( $(compgen -W "dark light 16 bw" -- "$cur") )
|
||||
return 0
|
||||
;;
|
||||
--history)
|
||||
COMPREPLY=()
|
||||
return 0
|
||||
;;
|
||||
esac
|
||||
|
||||
if [[ "$cur" =~ ^-|\+ ]]; then
|
||||
COMPREPLY=( $(compgen -W "${opts}" -- "$cur") )
|
||||
return 0
|
||||
fi
|
||||
|
||||
return 0
|
||||
}
|
||||
|
||||
_fzf_handle_dynamic_completion() {
|
||||
local cmd orig_var orig ret orig_cmd orig_complete
|
||||
cmd="$1"
|
||||
shift
|
||||
orig_cmd="$1"
|
||||
orig_var="_fzf_orig_completion_$cmd"
|
||||
orig="${!orig_var##*#}"
|
||||
if [[ -n "$orig" ]] && type "$orig" > /dev/null 2>&1; then
|
||||
$orig "$@"
|
||||
elif [[ -n "$_fzf_completion_loader" ]]; then
|
||||
orig_complete=$(complete -p "$orig_cmd" 2> /dev/null)
|
||||
_completion_loader "$@"
|
||||
ret=$?
|
||||
# _completion_loader may not have updated completion for the command
|
||||
if [[ "$(complete -p "$orig_cmd" 2> /dev/null)" != "$orig_complete" ]]; then
|
||||
__fzf_orig_completion < <(complete -p "$orig_cmd" 2> /dev/null)
|
||||
if [[ "$__fzf_nospace_commands" = *" $orig_cmd "* ]]; then
|
||||
eval "${orig_complete/ -F / -o nospace -F }"
|
||||
else
|
||||
eval "$orig_complete"
|
||||
fi
|
||||
fi
|
||||
return $ret
|
||||
fi
|
||||
}
|
||||
|
||||
__fzf_generic_path_completion() {
|
||||
local cur base dir leftover matches trigger cmd
|
||||
cmd="${COMP_WORDS[0]//[^A-Za-z0-9_=]/_}"
|
||||
COMPREPLY=()
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ "$cur" == *"$trigger" ]]; then
|
||||
base=${cur:0:${#cur}-${#trigger}}
|
||||
eval "base=$base"
|
||||
|
||||
[[ $base = *"/"* ]] && dir="$base"
|
||||
while true; do
|
||||
if [[ -z "$dir" ]] || [[ -d "$dir" ]]; then
|
||||
leftover=${base/#"$dir"}
|
||||
leftover=${leftover/#\/}
|
||||
[[ -z "$dir" ]] && dir='.'
|
||||
[[ "$dir" != "/" ]] && dir="${dir/%\//}"
|
||||
matches=$(eval "$1 $(printf %q "$dir")" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $2" __fzf_comprun "$4" -q "$leftover" | while read -r item; do
|
||||
printf "%q$3 " "$item"
|
||||
done)
|
||||
matches=${matches% }
|
||||
[[ -z "$3" ]] && [[ "$__fzf_nospace_commands" = *" ${COMP_WORDS[0]} "* ]] && matches="$matches "
|
||||
if [[ -n "$matches" ]]; then
|
||||
COMPREPLY=( "$matches" )
|
||||
else
|
||||
COMPREPLY=( "$cur" )
|
||||
fi
|
||||
printf '\e[5n'
|
||||
return 0
|
||||
fi
|
||||
dir=$(dirname "$dir")
|
||||
[[ "$dir" =~ /$ ]] || dir="$dir"/
|
||||
done
|
||||
else
|
||||
shift
|
||||
shift
|
||||
shift
|
||||
_fzf_handle_dynamic_completion "$cmd" "$@"
|
||||
fi
|
||||
}
|
||||
|
||||
_fzf_complete() {
|
||||
# Split arguments around --
|
||||
local args rest str_arg i sep
|
||||
args=("$@")
|
||||
sep=
|
||||
for i in "${!args[@]}"; do
|
||||
if [[ "${args[$i]}" = -- ]]; then
|
||||
sep=$i
|
||||
break
|
||||
fi
|
||||
done
|
||||
if [[ -n "$sep" ]]; then
|
||||
str_arg=
|
||||
rest=("${args[@]:$((sep + 1)):${#args[@]}}")
|
||||
args=("${args[@]:0:$sep}")
|
||||
else
|
||||
str_arg=$1
|
||||
args=()
|
||||
shift
|
||||
rest=("$@")
|
||||
fi
|
||||
|
||||
local cur selected trigger cmd post
|
||||
post="$(caller 0 | awk '{print $2}')_post"
|
||||
type -t "$post" > /dev/null 2>&1 || post=cat
|
||||
|
||||
cmd="${COMP_WORDS[0]//[^A-Za-z0-9_=]/_}"
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ "$cur" == *"$trigger" ]]; then
|
||||
cur=${cur:0:${#cur}-${#trigger}}
|
||||
|
||||
selected=$(FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $str_arg" __fzf_comprun "${rest[0]}" "${args[@]}" -q "$cur" | $post | tr '\n' ' ')
|
||||
selected=${selected% } # Strip trailing space not to repeat "-o nospace"
|
||||
if [[ -n "$selected" ]]; then
|
||||
COMPREPLY=("$selected")
|
||||
else
|
||||
COMPREPLY=("$cur")
|
||||
fi
|
||||
printf '\e[5n'
|
||||
return 0
|
||||
else
|
||||
_fzf_handle_dynamic_completion "$cmd" "${rest[@]}"
|
||||
fi
|
||||
}
|
||||
|
||||
_fzf_path_completion() {
|
||||
__fzf_generic_path_completion _fzf_compgen_path "-m" "" "$@"
|
||||
}
|
||||
|
||||
# Deprecated. No file only completion.
|
||||
_fzf_file_completion() {
|
||||
_fzf_path_completion "$@"
|
||||
}
|
||||
|
||||
_fzf_dir_completion() {
|
||||
__fzf_generic_path_completion _fzf_compgen_dir "" "/" "$@"
|
||||
}
|
||||
|
||||
_fzf_complete_kill() {
|
||||
local trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
local cur="${COMP_WORDS[COMP_CWORD]}"
|
||||
if [[ -z "$cur" ]]; then
|
||||
COMP_WORDS[$COMP_CWORD]=$trigger
|
||||
elif [[ "$cur" != *"$trigger" ]]; then
|
||||
return 1
|
||||
fi
|
||||
|
||||
_fzf_proc_completion "$@"
|
||||
}
|
||||
|
||||
_fzf_proc_completion() {
|
||||
_fzf_complete -m --preview 'echo {}' --preview-window down:3:wrap --min-height 15 -- "$@" < <(
|
||||
command ps -ef | sed 1d
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_proc_completion_post() {
|
||||
awk '{print $2}'
|
||||
}
|
||||
|
||||
_fzf_host_completion() {
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?]') \
|
||||
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts | tr ',' '\n' | tr -d '[' | awk '{ print $1 " " $1 }') \
|
||||
<(command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0') |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_var_completion() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
declare -xp | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_alias_completion() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
alias | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
# fzf options
|
||||
complete -o default -F _fzf_opts_completion fzf
|
||||
|
||||
d_cmds="${FZF_COMPLETION_DIR_COMMANDS:-cd pushd rmdir}"
|
||||
a_cmds="
|
||||
awk cat diff diff3
|
||||
emacs emacsclient ex file ftp g++ gcc gvim head hg java
|
||||
javac ld less more mvim nvim patch perl python ruby
|
||||
sed sftp sort source tail tee uniq vi view vim wc xdg-open
|
||||
basename bunzip2 bzip2 chmod chown curl cp dirname du
|
||||
find git grep gunzip gzip hg jar
|
||||
ln ls mv open rm rsync scp
|
||||
svn tar unzip zip"
|
||||
|
||||
# Preserve existing completion
|
||||
__fzf_orig_completion < <(complete -p $d_cmds $a_cmds 2> /dev/null)
|
||||
|
||||
if type _completion_loader > /dev/null 2>&1; then
|
||||
_fzf_completion_loader=1
|
||||
fi
|
||||
|
||||
__fzf_defc() {
|
||||
local cmd func opts orig_var orig def
|
||||
cmd="$1"
|
||||
func="$2"
|
||||
opts="$3"
|
||||
orig_var="_fzf_orig_completion_${cmd//[^A-Za-z0-9_]/_}"
|
||||
orig="${!orig_var}"
|
||||
if [[ -n "$orig" ]]; then
|
||||
printf -v def "$orig" "$func"
|
||||
eval "$def"
|
||||
else
|
||||
complete -F "$func" $opts "$cmd"
|
||||
fi
|
||||
}
|
||||
|
||||
# Anything
|
||||
for cmd in $a_cmds; do
|
||||
__fzf_defc "$cmd" _fzf_path_completion "-o default -o bashdefault"
|
||||
done
|
||||
|
||||
# Directory
|
||||
for cmd in $d_cmds; do
|
||||
__fzf_defc "$cmd" _fzf_dir_completion "-o nospace -o dirnames"
|
||||
done
|
||||
|
||||
# Kill completion (supports empty completion trigger)
|
||||
complete -F _fzf_complete_kill -o default -o bashdefault kill
|
||||
|
||||
unset cmd d_cmds a_cmds
|
||||
|
||||
_fzf_setup_completion() {
|
||||
local kind fn cmd
|
||||
kind=$1
|
||||
fn=_fzf_${1}_completion
|
||||
if [[ $# -lt 2 ]] || ! type -t "$fn" > /dev/null; then
|
||||
echo "usage: ${FUNCNAME[0]} path|dir|var|alias|host|proc COMMANDS..."
|
||||
return 1
|
||||
fi
|
||||
shift
|
||||
__fzf_orig_completion < <(complete -p "$@" 2> /dev/null)
|
||||
for cmd in "$@"; do
|
||||
case "$kind" in
|
||||
dir) __fzf_defc "$cmd" "$fn" "-o nospace -o dirnames" ;;
|
||||
var) __fzf_defc "$cmd" "$fn" "-o default -o nospace -v" ;;
|
||||
alias) __fzf_defc "$cmd" "$fn" "-a" ;;
|
||||
*) __fzf_defc "$cmd" "$fn" "-o default -o bashdefault" ;;
|
||||
esac
|
||||
done
|
||||
}
|
||||
|
||||
# Environment variables / Aliases / Hosts
|
||||
_fzf_setup_completion 'var' export unset
|
||||
_fzf_setup_completion 'alias' unalias
|
||||
_fzf_setup_completion 'host' ssh telnet
|
||||
|
||||
fi
|
||||
@ -1,329 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ completion.zsh
|
||||
#
|
||||
# - $FZF_TMUX (default: 0)
|
||||
# - $FZF_TMUX_OPTS (default: '-d 40%')
|
||||
# - $FZF_COMPLETION_TRIGGER (default: '**')
|
||||
# - $FZF_COMPLETION_OPTS (default: empty)
|
||||
|
||||
# Both branches of the following `if` do the same thing -- define
|
||||
# __fzf_completion_options such that `eval $__fzf_completion_options` sets
|
||||
# all options to the same values they currently have. We'll do just that at
|
||||
# the bottom of the file after changing options to what we prefer.
|
||||
#
|
||||
# IMPORTANT: Until we get to the `emulate` line, all words that *can* be quoted
|
||||
# *must* be quoted in order to prevent alias expansion. In addition, code must
|
||||
# be written in a way works with any set of zsh options. This is very tricky, so
|
||||
# careful when you change it.
|
||||
#
|
||||
# Start by loading the builtin zsh/parameter module. It provides `options`
|
||||
# associative array that stores current shell options.
|
||||
if 'zmodload' 'zsh/parameter' 2>'/dev/null' && (( ${+options} )); then
|
||||
# This is the fast branch and it gets taken on virtually all Zsh installations.
|
||||
#
|
||||
# ${(kv)options[@]} expands to array of keys (option names) and values ("on"
|
||||
# or "off"). The subsequent expansion# with (j: :) flag joins all elements
|
||||
# together separated by spaces. __fzf_completion_options ends up with a value
|
||||
# like this: "options=(shwordsplit off aliases on ...)".
|
||||
__fzf_completion_options="options=(${(j: :)${(kv)options[@]}})"
|
||||
else
|
||||
# This branch is much slower because it forks to get the names of all
|
||||
# zsh options. It's possible to eliminate this fork but it's not worth the
|
||||
# trouble because this branch gets taken only on very ancient or broken
|
||||
# zsh installations.
|
||||
() {
|
||||
# That `()` above defines an anonymous function. This is essentially a scope
|
||||
# for local parameters. We use it to avoid polluting global scope.
|
||||
'local' '__fzf_opt'
|
||||
__fzf_completion_options="setopt"
|
||||
# `set -o` prints one line for every zsh option. Each line contains option
|
||||
# name, some spaces, and then either "on" or "off". We just want option names.
|
||||
# Expansion with (@f) flag splits a string into lines. The outer expansion
|
||||
# removes spaces and everything that follow them on every line. __fzf_opt
|
||||
# ends up iterating over option names: shwordsplit, aliases, etc.
|
||||
for __fzf_opt in "${(@)${(@f)$(set -o)}%% *}"; do
|
||||
if [[ -o "$__fzf_opt" ]]; then
|
||||
# Option $__fzf_opt is currently on, so remember to set it back on.
|
||||
__fzf_completion_options+=" -o $__fzf_opt"
|
||||
else
|
||||
# Option $__fzf_opt is currently off, so remember to set it back off.
|
||||
__fzf_completion_options+=" +o $__fzf_opt"
|
||||
fi
|
||||
done
|
||||
# The value of __fzf_completion_options here looks like this:
|
||||
# "setopt +o shwordsplit -o aliases ..."
|
||||
}
|
||||
fi
|
||||
|
||||
# Enable the default zsh options (those marked with <Z> in `man zshoptions`)
|
||||
# but without `aliases`. Aliases in functions are expanded when functions are
|
||||
# defined, so if we disable aliases here, we'll be sure to have no pesky
|
||||
# aliases in any of our functions. This way we won't need prefix every
|
||||
# command with `command` or to quote every word to defend against global
|
||||
# aliases. Note that `aliases` is not the only option that's important to
|
||||
# control. There are several others that could wreck havoc if they are set
|
||||
# to values we don't expect. With the following `emulate` command we
|
||||
# sidestep this issue entirely.
|
||||
'emulate' 'zsh' '-o' 'no_aliases'
|
||||
|
||||
# This brace is the start of try-always block. The `always` part is like
|
||||
# `finally` in lesser languages. We use it to *always* restore user options.
|
||||
{
|
||||
|
||||
# Bail out if not interactive shell.
|
||||
[[ -o interactive ]] || return 0
|
||||
|
||||
# To use custom commands instead of find, override _fzf_compgen_{path,dir}
|
||||
if ! declare -f _fzf_compgen_path > /dev/null; then
|
||||
_fzf_compgen_path() {
|
||||
echo "$1"
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o \( -type d -o -type f -o -type l \) \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
if ! declare -f _fzf_compgen_dir > /dev/null; then
|
||||
_fzf_compgen_dir() {
|
||||
command find -L "$1" \
|
||||
-name .git -prune -o -name .hg -prune -o -name .svn -prune -o -type d \
|
||||
-a -not -path "$1" -print 2> /dev/null | sed 's@^\./@@'
|
||||
}
|
||||
fi
|
||||
|
||||
###########################################################
|
||||
|
||||
__fzf_comprun() {
|
||||
if [[ "$(type _fzf_comprun 2>&1)" =~ function ]]; then
|
||||
_fzf_comprun "$@"
|
||||
elif [ -n "$TMUX_PANE" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "$FZF_TMUX_OPTS" ]; }; then
|
||||
shift
|
||||
if [ -n "$FZF_TMUX_OPTS" ]; then
|
||||
fzf-tmux ${(Q)${(Z+n+)FZF_TMUX_OPTS}} -- "$@"
|
||||
else
|
||||
fzf-tmux -d ${FZF_TMUX_HEIGHT:-40%} -- "$@"
|
||||
fi
|
||||
else
|
||||
shift
|
||||
fzf "$@"
|
||||
fi
|
||||
}
|
||||
|
||||
# Extract the name of the command. e.g. foo=1 bar baz**<tab>
|
||||
__fzf_extract_command() {
|
||||
local token tokens
|
||||
tokens=(${(z)1})
|
||||
for token in $tokens; do
|
||||
token=${(Q)token}
|
||||
if [[ "$token" =~ [[:alnum:]] && ! "$token" =~ "=" ]]; then
|
||||
echo "$token"
|
||||
return
|
||||
fi
|
||||
done
|
||||
echo "${tokens[1]}"
|
||||
}
|
||||
|
||||
__fzf_generic_path_completion() {
|
||||
local base lbuf cmd compgen fzf_opts suffix tail dir leftover matches
|
||||
base=$1
|
||||
lbuf=$2
|
||||
cmd=$(__fzf_extract_command "$lbuf")
|
||||
compgen=$3
|
||||
fzf_opts=$4
|
||||
suffix=$5
|
||||
tail=$6
|
||||
|
||||
setopt localoptions nonomatch
|
||||
eval "base=$base"
|
||||
[[ $base = *"/"* ]] && dir="$base"
|
||||
while [ 1 ]; do
|
||||
if [[ -z "$dir" || -d ${dir} ]]; then
|
||||
leftover=${base/#"$dir"}
|
||||
leftover=${leftover/#\/}
|
||||
[ -z "$dir" ] && dir='.'
|
||||
[ "$dir" != "/" ] && dir="${dir/%\//}"
|
||||
matches=$(eval "$compgen $(printf %q "$dir")" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS" __fzf_comprun "$cmd" ${(Q)${(Z+n+)fzf_opts}} -q "$leftover" | while read item; do
|
||||
echo -n "${(q)item}$suffix "
|
||||
done)
|
||||
matches=${matches% }
|
||||
if [ -n "$matches" ]; then
|
||||
LBUFFER="$lbuf$matches$tail"
|
||||
fi
|
||||
zle reset-prompt
|
||||
break
|
||||
fi
|
||||
dir=$(dirname "$dir")
|
||||
dir=${dir%/}/
|
||||
done
|
||||
}
|
||||
|
||||
_fzf_path_completion() {
|
||||
__fzf_generic_path_completion "$1" "$2" _fzf_compgen_path \
|
||||
"-m" "" " "
|
||||
}
|
||||
|
||||
_fzf_dir_completion() {
|
||||
__fzf_generic_path_completion "$1" "$2" _fzf_compgen_dir \
|
||||
"" "/" ""
|
||||
}
|
||||
|
||||
_fzf_feed_fifo() (
|
||||
command rm -f "$1"
|
||||
mkfifo "$1"
|
||||
cat <&0 > "$1" &
|
||||
)
|
||||
|
||||
_fzf_complete() {
|
||||
setopt localoptions ksh_arrays
|
||||
# Split arguments around --
|
||||
local args rest str_arg i sep
|
||||
args=("$@")
|
||||
sep=
|
||||
for i in {0..${#args[@]}}; do
|
||||
if [[ "${args[$i]}" = -- ]]; then
|
||||
sep=$i
|
||||
break
|
||||
fi
|
||||
done
|
||||
if [[ -n "$sep" ]]; then
|
||||
str_arg=
|
||||
rest=("${args[@]:$((sep + 1)):${#args[@]}}")
|
||||
args=("${args[@]:0:$sep}")
|
||||
else
|
||||
str_arg=$1
|
||||
args=()
|
||||
shift
|
||||
rest=("$@")
|
||||
fi
|
||||
|
||||
local fifo lbuf cmd matches post
|
||||
fifo="${TMPDIR:-/tmp}/fzf-complete-fifo-$$"
|
||||
lbuf=${rest[0]}
|
||||
cmd=$(__fzf_extract_command "$lbuf")
|
||||
post="${funcstack[1]}_post"
|
||||
type $post > /dev/null 2>&1 || post=cat
|
||||
|
||||
_fzf_feed_fifo "$fifo"
|
||||
matches=$(FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_COMPLETION_OPTS $str_arg" __fzf_comprun "$cmd" "${args[@]}" -q "${(Q)prefix}" < "$fifo" | $post | tr '\n' ' ')
|
||||
if [ -n "$matches" ]; then
|
||||
LBUFFER="$lbuf$matches"
|
||||
fi
|
||||
command rm -f "$fifo"
|
||||
}
|
||||
|
||||
_fzf_complete_telnet() {
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0' |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_ssh() {
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
setopt localoptions nonomatch
|
||||
command cat <(command tail -n +1 ~/.ssh/config ~/.ssh/config.d/* /etc/ssh/ssh_config 2> /dev/null | command grep -i '^\s*host\(name\)\? ' | awk '{for (i = 2; i <= NF; i++) print $1 " " $i}' | command grep -v '[*?]') \
|
||||
<(command grep -oE '^[[a-z0-9.,:-]+' ~/.ssh/known_hosts | tr ',' '\n' | tr -d '[' | awk '{ print $1 " " $1 }') \
|
||||
<(command grep -v '^\s*\(#\|$\)' /etc/hosts | command grep -Fv '0.0.0.0') |
|
||||
awk '{if (length($2) > 0) {print $2}}' | sort -u
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_export() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
declare -xp | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_unset() {
|
||||
_fzf_complete -m -- "$@" < <(
|
||||
declare -xp | sed 's/=.*//' | sed 's/.* //'
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_unalias() {
|
||||
_fzf_complete +m -- "$@" < <(
|
||||
alias | sed 's/=.*//'
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_kill() {
|
||||
_fzf_complete -m --preview 'echo {}' --preview-window down:3:wrap --min-height 15 -- "$@" < <(
|
||||
command ps -ef | sed 1d
|
||||
)
|
||||
}
|
||||
|
||||
_fzf_complete_kill_post() {
|
||||
awk '{print $2}'
|
||||
}
|
||||
|
||||
fzf-completion() {
|
||||
local tokens cmd prefix trigger tail matches lbuf d_cmds
|
||||
setopt localoptions noshwordsplit noksh_arrays noposixbuiltins
|
||||
|
||||
# http://zsh.sourceforge.net/FAQ/zshfaq03.html
|
||||
# http://zsh.sourceforge.net/Doc/Release/Expansion.html#Parameter-Expansion-Flags
|
||||
tokens=(${(z)LBUFFER})
|
||||
if [ ${#tokens} -lt 1 ]; then
|
||||
zle ${fzf_default_completion:-expand-or-complete}
|
||||
return
|
||||
fi
|
||||
|
||||
cmd=$(__fzf_extract_command "$LBUFFER")
|
||||
|
||||
# Explicitly allow for empty trigger.
|
||||
trigger=${FZF_COMPLETION_TRIGGER-'**'}
|
||||
[ -z "$trigger" -a ${LBUFFER[-1]} = ' ' ] && tokens+=("")
|
||||
|
||||
# When the trigger starts with ';', it becomes a separate token
|
||||
if [[ ${LBUFFER} = *"${tokens[-2]}${tokens[-1]}" ]]; then
|
||||
tokens[-2]="${tokens[-2]}${tokens[-1]}"
|
||||
tokens=(${tokens[0,-2]})
|
||||
fi
|
||||
|
||||
lbuf=$LBUFFER
|
||||
tail=${LBUFFER:$(( ${#LBUFFER} - ${#trigger} ))}
|
||||
# Kill completion (do not require trigger sequence)
|
||||
if [ "$cmd" = kill -a ${LBUFFER[-1]} = ' ' ]; then
|
||||
tail=$trigger
|
||||
tokens+=$trigger
|
||||
lbuf="$lbuf$trigger"
|
||||
fi
|
||||
|
||||
# Trigger sequence given
|
||||
if [ ${#tokens} -gt 1 -a "$tail" = "$trigger" ]; then
|
||||
d_cmds=(${=FZF_COMPLETION_DIR_COMMANDS:-cd pushd rmdir})
|
||||
|
||||
[ -z "$trigger" ] && prefix=${tokens[-1]} || prefix=${tokens[-1]:0:-${#trigger}}
|
||||
[ -n "${tokens[-1]}" ] && lbuf=${lbuf:0:-${#tokens[-1]}}
|
||||
|
||||
if eval "type _fzf_complete_${cmd} > /dev/null"; then
|
||||
prefix="$prefix" eval _fzf_complete_${cmd} ${(q)lbuf}
|
||||
zle reset-prompt
|
||||
elif [ ${d_cmds[(i)$cmd]} -le ${#d_cmds} ]; then
|
||||
_fzf_dir_completion "$prefix" "$lbuf"
|
||||
else
|
||||
_fzf_path_completion "$prefix" "$lbuf"
|
||||
fi
|
||||
# Fall back to default completion
|
||||
else
|
||||
zle ${fzf_default_completion:-expand-or-complete}
|
||||
fi
|
||||
}
|
||||
|
||||
[ -z "$fzf_default_completion" ] && {
|
||||
binding=$(bindkey '^I')
|
||||
[[ $binding =~ 'undefined-key' ]] || fzf_default_completion=$binding[(s: :w)2]
|
||||
unset binding
|
||||
}
|
||||
|
||||
zle -N fzf-completion
|
||||
bindkey '^I' fzf-completion
|
||||
|
||||
} always {
|
||||
# Restore the original options.
|
||||
eval $__fzf_completion_options
|
||||
'unset' '__fzf_completion_options'
|
||||
}
|
||||
@ -1,96 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.bash
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
__fzf_select__() {
|
||||
local cmd="${FZF_CTRL_T_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | cut -b3-"}"
|
||||
eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS" $(__fzfcmd) -m "$@" | while read -r item; do
|
||||
printf '%q ' "$item"
|
||||
done
|
||||
echo
|
||||
}
|
||||
|
||||
if [[ $- =~ i ]]; then
|
||||
|
||||
__fzfcmd() {
|
||||
[[ -n "$TMUX_PANE" ]] && { [[ "${FZF_TMUX:-0}" != 0 ]] || [[ -n "$FZF_TMUX_OPTS" ]]; } &&
|
||||
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
||||
}
|
||||
|
||||
fzf-file-widget() {
|
||||
local selected="$(__fzf_select__)"
|
||||
READLINE_LINE="${READLINE_LINE:0:$READLINE_POINT}$selected${READLINE_LINE:$READLINE_POINT}"
|
||||
READLINE_POINT=$(( READLINE_POINT + ${#selected} ))
|
||||
}
|
||||
|
||||
__fzf_cd__() {
|
||||
local cmd dir
|
||||
cmd="${FZF_ALT_C_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | cut -b3-"}"
|
||||
dir=$(eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS" $(__fzfcmd) +m) && printf 'cd %q' "$dir"
|
||||
}
|
||||
|
||||
__fzf_history__() {
|
||||
local output
|
||||
output=$(
|
||||
builtin fc -lnr -2147483648 |
|
||||
last_hist=$(HISTTIMEFORMAT='' builtin history 1) perl -n -l0 -e 'BEGIN { getc; $/ = "\n\t"; $HISTCMD = $ENV{last_hist} + 1 } s/^[ *]//; print $HISTCMD - $. . "\t$_" if !$seen{$_}++' |
|
||||
FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} $FZF_DEFAULT_OPTS -n2..,.. --tiebreak=index --bind=ctrl-r:toggle-sort,ctrl-z:ignore $FZF_CTRL_R_OPTS +m --read0" $(__fzfcmd) --query "$READLINE_LINE"
|
||||
) || return
|
||||
READLINE_LINE=${output#*$'\t'}
|
||||
if [[ -z "$READLINE_POINT" ]]; then
|
||||
echo "$READLINE_LINE"
|
||||
else
|
||||
READLINE_POINT=0x7fffffff
|
||||
fi
|
||||
}
|
||||
|
||||
# Required to refresh the prompt after fzf
|
||||
bind -m emacs-standard '"\er": redraw-current-line'
|
||||
|
||||
bind -m vi-command '"\C-z": emacs-editing-mode'
|
||||
bind -m vi-insert '"\C-z": emacs-editing-mode'
|
||||
bind -m emacs-standard '"\C-z": vi-editing-mode'
|
||||
|
||||
if (( BASH_VERSINFO[0] < 4 )); then
|
||||
# CTRL-T - Paste the selected file path into the command line
|
||||
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`__fzf_select__`\e\C-e\er\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f"'
|
||||
bind -m vi-command '"\C-t": "\C-z\C-t\C-z"'
|
||||
bind -m vi-insert '"\C-t": "\C-z\C-t\C-z"'
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
bind -m emacs-standard '"\C-r": "\C-e \C-u\C-y\ey\C-u"$(__fzf_history__)"\e\C-e\er"'
|
||||
bind -m vi-command '"\C-r": "\C-z\C-r\C-z"'
|
||||
bind -m vi-insert '"\C-r": "\C-z\C-r\C-z"'
|
||||
else
|
||||
# CTRL-T - Paste the selected file path into the command line
|
||||
bind -m emacs-standard -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-command -x '"\C-t": fzf-file-widget'
|
||||
bind -m vi-insert -x '"\C-t": fzf-file-widget'
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
bind -m emacs-standard -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-command -x '"\C-r": __fzf_history__'
|
||||
bind -m vi-insert -x '"\C-r": __fzf_history__'
|
||||
fi
|
||||
|
||||
# ALT-C - cd into the selected directory
|
||||
bind -m emacs-standard '"\ec": " \C-b\C-k \C-u`__fzf_cd__`\e\C-e\er\C-m\C-y\C-h\e \C-y\ey\C-x\C-x\C-d"'
|
||||
bind -m vi-command '"\ec": "\C-z\ec\C-z"'
|
||||
bind -m vi-insert '"\ec": "\C-z\ec\C-z"'
|
||||
|
||||
fi
|
||||
@ -1,172 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.fish
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
function fzf_key_bindings
|
||||
|
||||
# Store current token in $dir as root for the 'find' command
|
||||
function fzf-file-widget -d "List files and folders"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -l dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
# "-path \$dir'*/\\.*'" matches hidden files/folders inside $dir but not
|
||||
# $dir itself, even if hidden.
|
||||
test -n "$FZF_CTRL_T_COMMAND"; or set -l FZF_CTRL_T_COMMAND "
|
||||
command find -L \$dir -mindepth 1 \\( -path \$dir'*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | sed 's@^\./@@'"
|
||||
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS"
|
||||
eval "$FZF_CTRL_T_COMMAND | "(__fzfcmd)' -m --query "'$fzf_query'"' | while read -l r; set result $result $r; end
|
||||
end
|
||||
if [ -z "$result" ]
|
||||
commandline -f repaint
|
||||
return
|
||||
else
|
||||
# Remove last token from commandline.
|
||||
commandline -t ""
|
||||
end
|
||||
for i in $result
|
||||
commandline -it -- $prefix
|
||||
commandline -it -- (string escape $i)
|
||||
commandline -it -- ' '
|
||||
end
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function fzf-history-widget -d "Show command history"
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT $FZF_DEFAULT_OPTS --tiebreak=index --bind=ctrl-r:toggle-sort,ctrl-z:ignore $FZF_CTRL_R_OPTS +m"
|
||||
|
||||
set -l FISH_MAJOR (echo $version | cut -f1 -d.)
|
||||
set -l FISH_MINOR (echo $version | cut -f2 -d.)
|
||||
|
||||
# history's -z flag is needed for multi-line support.
|
||||
# history's -z flag was added in fish 2.4.0, so don't use it for versions
|
||||
# before 2.4.0.
|
||||
if [ "$FISH_MAJOR" -gt 2 -o \( "$FISH_MAJOR" -eq 2 -a "$FISH_MINOR" -ge 4 \) ];
|
||||
history -z | eval (__fzfcmd) --read0 --print0 -q '(commandline)' | read -lz result
|
||||
and commandline -- $result
|
||||
else
|
||||
history | eval (__fzfcmd) -q '(commandline)' | read -l result
|
||||
and commandline -- $result
|
||||
end
|
||||
end
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function fzf-cd-widget -d "Change directory"
|
||||
set -l commandline (__fzf_parse_commandline)
|
||||
set -l dir $commandline[1]
|
||||
set -l fzf_query $commandline[2]
|
||||
set -l prefix $commandline[3]
|
||||
|
||||
test -n "$FZF_ALT_C_COMMAND"; or set -l FZF_ALT_C_COMMAND "
|
||||
command find -L \$dir -mindepth 1 \\( -path \$dir'*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | sed 's@^\./@@'"
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
begin
|
||||
set -lx FZF_DEFAULT_OPTS "--height $FZF_TMUX_HEIGHT --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS"
|
||||
eval "$FZF_ALT_C_COMMAND | "(__fzfcmd)' +m --query "'$fzf_query'"' | read -l result
|
||||
|
||||
if [ -n "$result" ]
|
||||
cd $result
|
||||
|
||||
# Remove last token from commandline.
|
||||
commandline -t ""
|
||||
commandline -it -- $prefix
|
||||
end
|
||||
end
|
||||
|
||||
commandline -f repaint
|
||||
end
|
||||
|
||||
function __fzfcmd
|
||||
test -n "$FZF_TMUX"; or set FZF_TMUX 0
|
||||
test -n "$FZF_TMUX_HEIGHT"; or set FZF_TMUX_HEIGHT 40%
|
||||
if [ -n "$FZF_TMUX_OPTS" ]
|
||||
echo "fzf-tmux $FZF_TMUX_OPTS -- "
|
||||
else if [ $FZF_TMUX -eq 1 ]
|
||||
echo "fzf-tmux -d$FZF_TMUX_HEIGHT -- "
|
||||
else
|
||||
echo "fzf"
|
||||
end
|
||||
end
|
||||
|
||||
bind \ct fzf-file-widget
|
||||
bind \cr fzf-history-widget
|
||||
bind \ec fzf-cd-widget
|
||||
|
||||
if bind -M insert > /dev/null 2>&1
|
||||
bind -M insert \ct fzf-file-widget
|
||||
bind -M insert \cr fzf-history-widget
|
||||
bind -M insert \ec fzf-cd-widget
|
||||
end
|
||||
|
||||
function __fzf_parse_commandline -d 'Parse the current command line token and return split of existing filepath, fzf query, and optional -option= prefix'
|
||||
set -l commandline (commandline -t)
|
||||
|
||||
# strip -option= from token if present
|
||||
set -l prefix (string match -r -- '^-[^\s=]+=' $commandline)
|
||||
set commandline (string replace -- "$prefix" '' $commandline)
|
||||
|
||||
# eval is used to do shell expansion on paths
|
||||
eval set commandline $commandline
|
||||
|
||||
if [ -z $commandline ]
|
||||
# Default to current directory with no --query
|
||||
set dir '.'
|
||||
set fzf_query ''
|
||||
else
|
||||
set dir (__fzf_get_dir $commandline)
|
||||
|
||||
if [ "$dir" = "." -a (string sub -l 1 -- $commandline) != '.' ]
|
||||
# if $dir is "." but commandline is not a relative path, this means no file path found
|
||||
set fzf_query $commandline
|
||||
else
|
||||
# Also remove trailing slash after dir, to "split" input properly
|
||||
set fzf_query (string replace -r "^$dir/?" -- '' "$commandline")
|
||||
end
|
||||
end
|
||||
|
||||
echo $dir
|
||||
echo $fzf_query
|
||||
echo $prefix
|
||||
end
|
||||
|
||||
function __fzf_get_dir -d 'Find the longest existing filepath from input string'
|
||||
set dir $argv
|
||||
|
||||
# Strip all trailing slashes. Ignore if $dir is root dir (/)
|
||||
if [ (string length -- $dir) -gt 1 ]
|
||||
set dir (string replace -r '/*$' -- '' $dir)
|
||||
end
|
||||
|
||||
# Iteratively check if dir exists and strip tail end of path
|
||||
while [ ! -d "$dir" ]
|
||||
# If path is absolute, this can keep going until ends up at /
|
||||
# If path is relative, this can keep going until entire input is consumed, dirname returns "."
|
||||
set dir (dirname -- "$dir")
|
||||
end
|
||||
|
||||
echo $dir
|
||||
end
|
||||
|
||||
end
|
||||
@ -1,114 +0,0 @@
|
||||
# ____ ____
|
||||
# / __/___ / __/
|
||||
# / /_/_ / / /_
|
||||
# / __/ / /_/ __/
|
||||
# /_/ /___/_/ key-bindings.zsh
|
||||
#
|
||||
# - $FZF_TMUX_OPTS
|
||||
# - $FZF_CTRL_T_COMMAND
|
||||
# - $FZF_CTRL_T_OPTS
|
||||
# - $FZF_CTRL_R_OPTS
|
||||
# - $FZF_ALT_C_COMMAND
|
||||
# - $FZF_ALT_C_OPTS
|
||||
|
||||
# Key bindings
|
||||
# ------------
|
||||
|
||||
# The code at the top and the bottom of this file is the same as in completion.zsh.
|
||||
# Refer to that file for explanation.
|
||||
if 'zmodload' 'zsh/parameter' 2>'/dev/null' && (( ${+options} )); then
|
||||
__fzf_key_bindings_options="options=(${(j: :)${(kv)options[@]}})"
|
||||
else
|
||||
() {
|
||||
__fzf_key_bindings_options="setopt"
|
||||
'local' '__fzf_opt'
|
||||
for __fzf_opt in "${(@)${(@f)$(set -o)}%% *}"; do
|
||||
if [[ -o "$__fzf_opt" ]]; then
|
||||
__fzf_key_bindings_options+=" -o $__fzf_opt"
|
||||
else
|
||||
__fzf_key_bindings_options+=" +o $__fzf_opt"
|
||||
fi
|
||||
done
|
||||
}
|
||||
fi
|
||||
|
||||
'emulate' 'zsh' '-o' 'no_aliases'
|
||||
|
||||
{
|
||||
|
||||
[[ -o interactive ]] || return 0
|
||||
|
||||
# CTRL-T - Paste the selected file path(s) into the command line
|
||||
__fsel() {
|
||||
local cmd="${FZF_CTRL_T_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type f -print \
|
||||
-o -type d -print \
|
||||
-o -type l -print 2> /dev/null | cut -b3-"}"
|
||||
setopt localoptions pipefail no_aliases 2> /dev/null
|
||||
local item
|
||||
eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_CTRL_T_OPTS" $(__fzfcmd) -m "$@" | while read item; do
|
||||
echo -n "${(q)item} "
|
||||
done
|
||||
local ret=$?
|
||||
echo
|
||||
return $ret
|
||||
}
|
||||
|
||||
__fzfcmd() {
|
||||
[ -n "$TMUX_PANE" ] && { [ "${FZF_TMUX:-0}" != 0 ] || [ -n "$FZF_TMUX_OPTS" ]; } &&
|
||||
echo "fzf-tmux ${FZF_TMUX_OPTS:--d${FZF_TMUX_HEIGHT:-40%}} -- " || echo "fzf"
|
||||
}
|
||||
|
||||
fzf-file-widget() {
|
||||
LBUFFER="${LBUFFER}$(__fsel)"
|
||||
local ret=$?
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
zle -N fzf-file-widget
|
||||
bindkey '^T' fzf-file-widget
|
||||
|
||||
# ALT-C - cd into the selected directory
|
||||
fzf-cd-widget() {
|
||||
local cmd="${FZF_ALT_C_COMMAND:-"command find -L . -mindepth 1 \\( -path '*/\\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \\) -prune \
|
||||
-o -type d -print 2> /dev/null | cut -b3-"}"
|
||||
setopt localoptions pipefail no_aliases 2> /dev/null
|
||||
local dir="$(eval "$cmd" | FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} --reverse --bind=ctrl-z:ignore $FZF_DEFAULT_OPTS $FZF_ALT_C_OPTS" $(__fzfcmd) +m)"
|
||||
if [[ -z "$dir" ]]; then
|
||||
zle redisplay
|
||||
return 0
|
||||
fi
|
||||
zle push-line # Clear buffer. Auto-restored on next prompt.
|
||||
BUFFER="cd ${(q)dir}"
|
||||
zle accept-line
|
||||
local ret=$?
|
||||
unset dir # ensure this doesn't end up appearing in prompt expansion
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
zle -N fzf-cd-widget
|
||||
bindkey '\ec' fzf-cd-widget
|
||||
|
||||
# CTRL-R - Paste the selected command from history into the command line
|
||||
fzf-history-widget() {
|
||||
local selected num
|
||||
setopt localoptions noglobsubst noposixbuiltins pipefail no_aliases 2> /dev/null
|
||||
selected=( $(fc -rl 1 | perl -ne 'print if !$seen{(/^\s*[0-9]+\**\s+(.*)/, $1)}++' |
|
||||
FZF_DEFAULT_OPTS="--height ${FZF_TMUX_HEIGHT:-40%} $FZF_DEFAULT_OPTS -n2..,.. --tiebreak=index --bind=ctrl-r:toggle-sort,ctrl-z:ignore $FZF_CTRL_R_OPTS --query=${(qqq)LBUFFER} +m" $(__fzfcmd)) )
|
||||
local ret=$?
|
||||
if [ -n "$selected" ]; then
|
||||
num=$selected[1]
|
||||
if [ -n "$num" ]; then
|
||||
zle vi-fetch-history -n $num
|
||||
fi
|
||||
fi
|
||||
zle reset-prompt
|
||||
return $ret
|
||||
}
|
||||
zle -N fzf-history-widget
|
||||
bindkey '^R' fzf-history-widget
|
||||
|
||||
} always {
|
||||
eval $__fzf_key_bindings_options
|
||||
'unset' '__fzf_key_bindings_options'
|
||||
}
|
||||
@ -1,21 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
@ -1,884 +0,0 @@
|
||||
package algo
|
||||
|
||||
/*
|
||||
|
||||
Algorithm
|
||||
---------
|
||||
|
||||
FuzzyMatchV1 finds the first "fuzzy" occurrence of the pattern within the given
|
||||
text in O(n) time where n is the length of the text. Once the position of the
|
||||
last character is located, it traverses backwards to see if there's a shorter
|
||||
substring that matches the pattern.
|
||||
|
||||
a_____b___abc__ To find "abc"
|
||||
*-----*-----*> 1. Forward scan
|
||||
<*** 2. Backward scan
|
||||
|
||||
The algorithm is simple and fast, but as it only sees the first occurrence,
|
||||
it is not guaranteed to find the occurrence with the highest score.
|
||||
|
||||
a_____b__c__abc
|
||||
*-----*--* ***
|
||||
|
||||
FuzzyMatchV2 implements a modified version of Smith-Waterman algorithm to find
|
||||
the optimal solution (highest score) according to the scoring criteria. Unlike
|
||||
the original algorithm, omission or mismatch of a character in the pattern is
|
||||
not allowed.
|
||||
|
||||
Performance
|
||||
-----------
|
||||
|
||||
The new V2 algorithm is slower than V1 as it examines all occurrences of the
|
||||
pattern instead of stopping immediately after finding the first one. The time
|
||||
complexity of the algorithm is O(nm) if a match is found and O(n) otherwise
|
||||
where n is the length of the item and m is the length of the pattern. Thus, the
|
||||
performance overhead may not be noticeable for a query with high selectivity.
|
||||
However, if the performance is more important than the quality of the result,
|
||||
you can still choose v1 algorithm with --algo=v1.
|
||||
|
||||
Scoring criteria
|
||||
----------------
|
||||
|
||||
- We prefer matches at special positions, such as the start of a word, or
|
||||
uppercase character in camelCase words.
|
||||
|
||||
- That is, we prefer an occurrence of the pattern with more characters
|
||||
matching at special positions, even if the total match length is longer.
|
||||
e.g. "fuzzyfinder" vs. "fuzzy-finder" on "ff"
|
||||
````````````
|
||||
- Also, if the first character in the pattern appears at one of the special
|
||||
positions, the bonus point for the position is multiplied by a constant
|
||||
as it is extremely likely that the first character in the typed pattern
|
||||
has more significance than the rest.
|
||||
e.g. "fo-bar" vs. "foob-r" on "br"
|
||||
``````
|
||||
- But since fzf is still a fuzzy finder, not an acronym finder, we should also
|
||||
consider the total length of the matched substring. This is why we have the
|
||||
gap penalty. The gap penalty increases as the length of the gap (distance
|
||||
between the matching characters) increases, so the effect of the bonus is
|
||||
eventually cancelled at some point.
|
||||
e.g. "fuzzyfinder" vs. "fuzzy-blurry-finder" on "ff"
|
||||
```````````
|
||||
- Consequently, it is crucial to find the right balance between the bonus
|
||||
and the gap penalty. The parameters were chosen that the bonus is cancelled
|
||||
when the gap size increases beyond 8 characters.
|
||||
|
||||
- The bonus mechanism can have the undesirable side effect where consecutive
|
||||
matches are ranked lower than the ones with gaps.
|
||||
e.g. "foobar" vs. "foo-bar" on "foob"
|
||||
```````
|
||||
- To correct this anomaly, we also give extra bonus point to each character
|
||||
in a consecutive matching chunk.
|
||||
e.g. "foobar" vs. "foo-bar" on "foob"
|
||||
``````
|
||||
- The amount of consecutive bonus is primarily determined by the bonus of the
|
||||
first character in the chunk.
|
||||
e.g. "foobar" vs. "out-of-bound" on "oob"
|
||||
````````````
|
||||
*/
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"strings"
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
var DEBUG bool
|
||||
|
||||
func indexAt(index int, max int, forward bool) int {
|
||||
if forward {
|
||||
return index
|
||||
}
|
||||
return max - index - 1
|
||||
}
|
||||
|
||||
// Result contains the results of running a match function.
|
||||
type Result struct {
|
||||
// TODO int32 should suffice
|
||||
Start int
|
||||
End int
|
||||
Score int
|
||||
}
|
||||
|
||||
const (
|
||||
scoreMatch = 16
|
||||
scoreGapStart = -3
|
||||
scoreGapExtension = -1
|
||||
|
||||
// We prefer matches at the beginning of a word, but the bonus should not be
|
||||
// too great to prevent the longer acronym matches from always winning over
|
||||
// shorter fuzzy matches. The bonus point here was specifically chosen that
|
||||
// the bonus is cancelled when the gap between the acronyms grows over
|
||||
// 8 characters, which is approximately the average length of the words found
|
||||
// in web2 dictionary and my file system.
|
||||
bonusBoundary = scoreMatch / 2
|
||||
|
||||
// Although bonus point for non-word characters is non-contextual, we need it
|
||||
// for computing bonus points for consecutive chunks starting with a non-word
|
||||
// character.
|
||||
bonusNonWord = scoreMatch / 2
|
||||
|
||||
// Edge-triggered bonus for matches in camelCase words.
|
||||
// Compared to word-boundary case, they don't accompany single-character gaps
|
||||
// (e.g. FooBar vs. foo-bar), so we deduct bonus point accordingly.
|
||||
bonusCamel123 = bonusBoundary + scoreGapExtension
|
||||
|
||||
// Minimum bonus point given to characters in consecutive chunks.
|
||||
// Note that bonus points for consecutive matches shouldn't have needed if we
|
||||
// used fixed match score as in the original algorithm.
|
||||
bonusConsecutive = -(scoreGapStart + scoreGapExtension)
|
||||
|
||||
// The first character in the typed pattern usually has more significance
|
||||
// than the rest so it's important that it appears at special positions where
|
||||
// bonus points are given, e.g. "to-go" vs. "ongoing" on "og" or on "ogo".
|
||||
// The amount of the extra bonus should be limited so that the gap penalty is
|
||||
// still respected.
|
||||
bonusFirstCharMultiplier = 2
|
||||
)
|
||||
|
||||
type charClass int
|
||||
|
||||
const (
|
||||
charNonWord charClass = iota
|
||||
charLower
|
||||
charUpper
|
||||
charLetter
|
||||
charNumber
|
||||
)
|
||||
|
||||
func posArray(withPos bool, len int) *[]int {
|
||||
if withPos {
|
||||
pos := make([]int, 0, len)
|
||||
return &pos
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func alloc16(offset int, slab *util.Slab, size int) (int, []int16) {
|
||||
if slab != nil && cap(slab.I16) > offset+size {
|
||||
slice := slab.I16[offset : offset+size]
|
||||
return offset + size, slice
|
||||
}
|
||||
return offset, make([]int16, size)
|
||||
}
|
||||
|
||||
func alloc32(offset int, slab *util.Slab, size int) (int, []int32) {
|
||||
if slab != nil && cap(slab.I32) > offset+size {
|
||||
slice := slab.I32[offset : offset+size]
|
||||
return offset + size, slice
|
||||
}
|
||||
return offset, make([]int32, size)
|
||||
}
|
||||
|
||||
func charClassOfAscii(char rune) charClass {
|
||||
if char >= 'a' && char <= 'z' {
|
||||
return charLower
|
||||
} else if char >= 'A' && char <= 'Z' {
|
||||
return charUpper
|
||||
} else if char >= '0' && char <= '9' {
|
||||
return charNumber
|
||||
}
|
||||
return charNonWord
|
||||
}
|
||||
|
||||
func charClassOfNonAscii(char rune) charClass {
|
||||
if unicode.IsLower(char) {
|
||||
return charLower
|
||||
} else if unicode.IsUpper(char) {
|
||||
return charUpper
|
||||
} else if unicode.IsNumber(char) {
|
||||
return charNumber
|
||||
} else if unicode.IsLetter(char) {
|
||||
return charLetter
|
||||
}
|
||||
return charNonWord
|
||||
}
|
||||
|
||||
func charClassOf(char rune) charClass {
|
||||
if char <= unicode.MaxASCII {
|
||||
return charClassOfAscii(char)
|
||||
}
|
||||
return charClassOfNonAscii(char)
|
||||
}
|
||||
|
||||
func bonusFor(prevClass charClass, class charClass) int16 {
|
||||
if prevClass == charNonWord && class != charNonWord {
|
||||
// Word boundary
|
||||
return bonusBoundary
|
||||
} else if prevClass == charLower && class == charUpper ||
|
||||
prevClass != charNumber && class == charNumber {
|
||||
// camelCase letter123
|
||||
return bonusCamel123
|
||||
} else if class == charNonWord {
|
||||
return bonusNonWord
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
func bonusAt(input *util.Chars, idx int) int16 {
|
||||
if idx == 0 {
|
||||
return bonusBoundary
|
||||
}
|
||||
return bonusFor(charClassOf(input.Get(idx-1)), charClassOf(input.Get(idx)))
|
||||
}
|
||||
|
||||
func normalizeRune(r rune) rune {
|
||||
if r < 0x00C0 || r > 0x2184 {
|
||||
return r
|
||||
}
|
||||
|
||||
n := normalized[r]
|
||||
if n > 0 {
|
||||
return n
|
||||
}
|
||||
return r
|
||||
}
|
||||
|
||||
// Algo functions make two assumptions
|
||||
// 1. "pattern" is given in lowercase if "caseSensitive" is false
|
||||
// 2. "pattern" is already normalized if "normalize" is true
|
||||
type Algo func(caseSensitive bool, normalize bool, forward bool, input *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int)
|
||||
|
||||
func trySkip(input *util.Chars, caseSensitive bool, b byte, from int) int {
|
||||
byteArray := input.Bytes()[from:]
|
||||
idx := bytes.IndexByte(byteArray, b)
|
||||
if idx == 0 {
|
||||
// Can't skip any further
|
||||
return from
|
||||
}
|
||||
// We may need to search for the uppercase letter again. We don't have to
|
||||
// consider normalization as we can be sure that this is an ASCII string.
|
||||
if !caseSensitive && b >= 'a' && b <= 'z' {
|
||||
if idx > 0 {
|
||||
byteArray = byteArray[:idx]
|
||||
}
|
||||
uidx := bytes.IndexByte(byteArray, b-32)
|
||||
if uidx >= 0 {
|
||||
idx = uidx
|
||||
}
|
||||
}
|
||||
if idx < 0 {
|
||||
return -1
|
||||
}
|
||||
return from + idx
|
||||
}
|
||||
|
||||
func isAscii(runes []rune) bool {
|
||||
for _, r := range runes {
|
||||
if r >= utf8.RuneSelf {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func asciiFuzzyIndex(input *util.Chars, pattern []rune, caseSensitive bool) int {
|
||||
// Can't determine
|
||||
if !input.IsBytes() {
|
||||
return 0
|
||||
}
|
||||
|
||||
// Not possible
|
||||
if !isAscii(pattern) {
|
||||
return -1
|
||||
}
|
||||
|
||||
firstIdx, idx := 0, 0
|
||||
for pidx := 0; pidx < len(pattern); pidx++ {
|
||||
idx = trySkip(input, caseSensitive, byte(pattern[pidx]), idx)
|
||||
if idx < 0 {
|
||||
return -1
|
||||
}
|
||||
if pidx == 0 && idx > 0 {
|
||||
// Step back to find the right bonus point
|
||||
firstIdx = idx - 1
|
||||
}
|
||||
idx++
|
||||
}
|
||||
return firstIdx
|
||||
}
|
||||
|
||||
func debugV2(T []rune, pattern []rune, F []int32, lastIdx int, H []int16, C []int16) {
|
||||
width := lastIdx - int(F[0]) + 1
|
||||
|
||||
for i, f := range F {
|
||||
I := i * width
|
||||
if i == 0 {
|
||||
fmt.Print(" ")
|
||||
for j := int(f); j <= lastIdx; j++ {
|
||||
fmt.Printf(" " + string(T[j]) + " ")
|
||||
}
|
||||
fmt.Println()
|
||||
}
|
||||
fmt.Print(string(pattern[i]) + " ")
|
||||
for idx := int(F[0]); idx < int(f); idx++ {
|
||||
fmt.Print(" 0 ")
|
||||
}
|
||||
for idx := int(f); idx <= lastIdx; idx++ {
|
||||
fmt.Printf("%2d ", H[i*width+idx-int(F[0])])
|
||||
}
|
||||
fmt.Println()
|
||||
|
||||
fmt.Print(" ")
|
||||
for idx, p := range C[I : I+width] {
|
||||
if idx+int(F[0]) < int(F[i]) {
|
||||
p = 0
|
||||
}
|
||||
if p > 0 {
|
||||
fmt.Printf("%2d ", p)
|
||||
} else {
|
||||
fmt.Print(" ")
|
||||
}
|
||||
}
|
||||
fmt.Println()
|
||||
}
|
||||
}
|
||||
|
||||
func FuzzyMatchV2(caseSensitive bool, normalize bool, forward bool, input *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
// Assume that pattern is given in lowercase if case-insensitive.
|
||||
// First check if there's a match and calculate bonus for each position.
|
||||
// If the input string is too long, consider finding the matching chars in
|
||||
// this phase as well (non-optimal alignment).
|
||||
M := len(pattern)
|
||||
if M == 0 {
|
||||
return Result{0, 0, 0}, posArray(withPos, M)
|
||||
}
|
||||
N := input.Length()
|
||||
|
||||
// Since O(nm) algorithm can be prohibitively expensive for large input,
|
||||
// we fall back to the greedy algorithm.
|
||||
if slab != nil && N*M > cap(slab.I16) {
|
||||
return FuzzyMatchV1(caseSensitive, normalize, forward, input, pattern, withPos, slab)
|
||||
}
|
||||
|
||||
// Phase 1. Optimized search for ASCII string
|
||||
idx := asciiFuzzyIndex(input, pattern, caseSensitive)
|
||||
if idx < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// Reuse pre-allocated integer slice to avoid unnecessary sweeping of garbages
|
||||
offset16 := 0
|
||||
offset32 := 0
|
||||
offset16, H0 := alloc16(offset16, slab, N)
|
||||
offset16, C0 := alloc16(offset16, slab, N)
|
||||
// Bonus point for each position
|
||||
offset16, B := alloc16(offset16, slab, N)
|
||||
// The first occurrence of each character in the pattern
|
||||
offset32, F := alloc32(offset32, slab, M)
|
||||
// Rune array
|
||||
_, T := alloc32(offset32, slab, N)
|
||||
input.CopyRunes(T)
|
||||
|
||||
// Phase 2. Calculate bonus for each point
|
||||
maxScore, maxScorePos := int16(0), 0
|
||||
pidx, lastIdx := 0, 0
|
||||
pchar0, pchar, prevH0, prevClass, inGap := pattern[0], pattern[0], int16(0), charNonWord, false
|
||||
Tsub := T[idx:]
|
||||
H0sub, C0sub, Bsub := H0[idx:][:len(Tsub)], C0[idx:][:len(Tsub)], B[idx:][:len(Tsub)]
|
||||
for off, char := range Tsub {
|
||||
var class charClass
|
||||
if char <= unicode.MaxASCII {
|
||||
class = charClassOfAscii(char)
|
||||
if !caseSensitive && class == charUpper {
|
||||
char += 32
|
||||
}
|
||||
} else {
|
||||
class = charClassOfNonAscii(char)
|
||||
if !caseSensitive && class == charUpper {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
}
|
||||
|
||||
Tsub[off] = char
|
||||
bonus := bonusFor(prevClass, class)
|
||||
Bsub[off] = bonus
|
||||
prevClass = class
|
||||
|
||||
if char == pchar {
|
||||
if pidx < M {
|
||||
F[pidx] = int32(idx + off)
|
||||
pidx++
|
||||
pchar = pattern[util.Min(pidx, M-1)]
|
||||
}
|
||||
lastIdx = idx + off
|
||||
}
|
||||
|
||||
if char == pchar0 {
|
||||
score := scoreMatch + bonus*bonusFirstCharMultiplier
|
||||
H0sub[off] = score
|
||||
C0sub[off] = 1
|
||||
if M == 1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
||||
maxScore, maxScorePos = score, idx+off
|
||||
if forward && bonus == bonusBoundary {
|
||||
break
|
||||
}
|
||||
}
|
||||
inGap = false
|
||||
} else {
|
||||
if inGap {
|
||||
H0sub[off] = util.Max16(prevH0+scoreGapExtension, 0)
|
||||
} else {
|
||||
H0sub[off] = util.Max16(prevH0+scoreGapStart, 0)
|
||||
}
|
||||
C0sub[off] = 0
|
||||
inGap = true
|
||||
}
|
||||
prevH0 = H0sub[off]
|
||||
}
|
||||
if pidx != M {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
if M == 1 {
|
||||
result := Result{maxScorePos, maxScorePos + 1, int(maxScore)}
|
||||
if !withPos {
|
||||
return result, nil
|
||||
}
|
||||
pos := []int{maxScorePos}
|
||||
return result, &pos
|
||||
}
|
||||
|
||||
// Phase 3. Fill in score matrix (H)
|
||||
// Unlike the original algorithm, we do not allow omission.
|
||||
f0 := int(F[0])
|
||||
width := lastIdx - f0 + 1
|
||||
offset16, H := alloc16(offset16, slab, width*M)
|
||||
copy(H, H0[f0:lastIdx+1])
|
||||
|
||||
// Possible length of consecutive chunk at each position.
|
||||
_, C := alloc16(offset16, slab, width*M)
|
||||
copy(C, C0[f0:lastIdx+1])
|
||||
|
||||
Fsub := F[1:]
|
||||
Psub := pattern[1:][:len(Fsub)]
|
||||
for off, f := range Fsub {
|
||||
f := int(f)
|
||||
pchar := Psub[off]
|
||||
pidx := off + 1
|
||||
row := pidx * width
|
||||
inGap := false
|
||||
Tsub := T[f : lastIdx+1]
|
||||
Bsub := B[f:][:len(Tsub)]
|
||||
Csub := C[row+f-f0:][:len(Tsub)]
|
||||
Cdiag := C[row+f-f0-1-width:][:len(Tsub)]
|
||||
Hsub := H[row+f-f0:][:len(Tsub)]
|
||||
Hdiag := H[row+f-f0-1-width:][:len(Tsub)]
|
||||
Hleft := H[row+f-f0-1:][:len(Tsub)]
|
||||
Hleft[0] = 0
|
||||
for off, char := range Tsub {
|
||||
col := off + f
|
||||
var s1, s2, consecutive int16
|
||||
|
||||
if inGap {
|
||||
s2 = Hleft[off] + scoreGapExtension
|
||||
} else {
|
||||
s2 = Hleft[off] + scoreGapStart
|
||||
}
|
||||
|
||||
if pchar == char {
|
||||
s1 = Hdiag[off] + scoreMatch
|
||||
b := Bsub[off]
|
||||
consecutive = Cdiag[off] + 1
|
||||
// Break consecutive chunk
|
||||
if b == bonusBoundary {
|
||||
consecutive = 1
|
||||
} else if consecutive > 1 {
|
||||
b = util.Max16(b, util.Max16(bonusConsecutive, B[col-int(consecutive)+1]))
|
||||
}
|
||||
if s1+b < s2 {
|
||||
s1 += Bsub[off]
|
||||
consecutive = 0
|
||||
} else {
|
||||
s1 += b
|
||||
}
|
||||
}
|
||||
Csub[off] = consecutive
|
||||
|
||||
inGap = s1 < s2
|
||||
score := util.Max16(util.Max16(s1, s2), 0)
|
||||
if pidx == M-1 && (forward && score > maxScore || !forward && score >= maxScore) {
|
||||
maxScore, maxScorePos = score, col
|
||||
}
|
||||
Hsub[off] = score
|
||||
}
|
||||
}
|
||||
|
||||
if DEBUG {
|
||||
debugV2(T, pattern, F, lastIdx, H, C)
|
||||
}
|
||||
|
||||
// Phase 4. (Optional) Backtrace to find character positions
|
||||
pos := posArray(withPos, M)
|
||||
j := f0
|
||||
if withPos {
|
||||
i := M - 1
|
||||
j = maxScorePos
|
||||
preferMatch := true
|
||||
for {
|
||||
I := i * width
|
||||
j0 := j - f0
|
||||
s := H[I+j0]
|
||||
|
||||
var s1, s2 int16
|
||||
if i > 0 && j >= int(F[i]) {
|
||||
s1 = H[I-width+j0-1]
|
||||
}
|
||||
if j > int(F[i]) {
|
||||
s2 = H[I+j0-1]
|
||||
}
|
||||
|
||||
if s > s1 && (s > s2 || s == s2 && preferMatch) {
|
||||
*pos = append(*pos, j)
|
||||
if i == 0 {
|
||||
break
|
||||
}
|
||||
i--
|
||||
}
|
||||
preferMatch = C[I+j0] > 1 || I+width+j0+1 < len(C) && C[I+width+j0+1] > 0
|
||||
j--
|
||||
}
|
||||
}
|
||||
// Start offset we return here is only relevant when begin tiebreak is used.
|
||||
// However finding the accurate offset requires backtracking, and we don't
|
||||
// want to pay extra cost for the option that has lost its importance.
|
||||
return Result{j, maxScorePos + 1, int(maxScore)}, pos
|
||||
}
|
||||
|
||||
// Implement the same sorting criteria as V2
|
||||
func calculateScore(caseSensitive bool, normalize bool, text *util.Chars, pattern []rune, sidx int, eidx int, withPos bool) (int, *[]int) {
|
||||
pidx, score, inGap, consecutive, firstBonus := 0, 0, false, 0, int16(0)
|
||||
pos := posArray(withPos, len(pattern))
|
||||
prevClass := charNonWord
|
||||
if sidx > 0 {
|
||||
prevClass = charClassOf(text.Get(sidx - 1))
|
||||
}
|
||||
for idx := sidx; idx < eidx; idx++ {
|
||||
char := text.Get(idx)
|
||||
class := charClassOf(char)
|
||||
if !caseSensitive {
|
||||
if char >= 'A' && char <= 'Z' {
|
||||
char += 32
|
||||
} else if char > unicode.MaxASCII {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
}
|
||||
// pattern is already normalized
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
if char == pattern[pidx] {
|
||||
if withPos {
|
||||
*pos = append(*pos, idx)
|
||||
}
|
||||
score += scoreMatch
|
||||
bonus := bonusFor(prevClass, class)
|
||||
if consecutive == 0 {
|
||||
firstBonus = bonus
|
||||
} else {
|
||||
// Break consecutive chunk
|
||||
if bonus == bonusBoundary {
|
||||
firstBonus = bonus
|
||||
}
|
||||
bonus = util.Max16(util.Max16(bonus, firstBonus), bonusConsecutive)
|
||||
}
|
||||
if pidx == 0 {
|
||||
score += int(bonus * bonusFirstCharMultiplier)
|
||||
} else {
|
||||
score += int(bonus)
|
||||
}
|
||||
inGap = false
|
||||
consecutive++
|
||||
pidx++
|
||||
} else {
|
||||
if inGap {
|
||||
score += scoreGapExtension
|
||||
} else {
|
||||
score += scoreGapStart
|
||||
}
|
||||
inGap = true
|
||||
consecutive = 0
|
||||
firstBonus = 0
|
||||
}
|
||||
prevClass = class
|
||||
}
|
||||
return score, pos
|
||||
}
|
||||
|
||||
// FuzzyMatchV1 performs fuzzy-match
|
||||
func FuzzyMatchV1(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
if len(pattern) == 0 {
|
||||
return Result{0, 0, 0}, nil
|
||||
}
|
||||
if asciiFuzzyIndex(text, pattern, caseSensitive) < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
pidx := 0
|
||||
sidx := -1
|
||||
eidx := -1
|
||||
|
||||
lenRunes := text.Length()
|
||||
lenPattern := len(pattern)
|
||||
|
||||
for index := 0; index < lenRunes; index++ {
|
||||
char := text.Get(indexAt(index, lenRunes, forward))
|
||||
// This is considerably faster than blindly applying strings.ToLower to the
|
||||
// whole string
|
||||
if !caseSensitive {
|
||||
// Partially inlining `unicode.ToLower`. Ugly, but makes a noticeable
|
||||
// difference in CPU cost. (Measured on Go 1.4.1. Also note that the Go
|
||||
// compiler as of now does not inline non-leaf functions.)
|
||||
if char >= 'A' && char <= 'Z' {
|
||||
char += 32
|
||||
} else if char > unicode.MaxASCII {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
pchar := pattern[indexAt(pidx, lenPattern, forward)]
|
||||
if char == pchar {
|
||||
if sidx < 0 {
|
||||
sidx = index
|
||||
}
|
||||
if pidx++; pidx == lenPattern {
|
||||
eidx = index + 1
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if sidx >= 0 && eidx >= 0 {
|
||||
pidx--
|
||||
for index := eidx - 1; index >= sidx; index-- {
|
||||
tidx := indexAt(index, lenRunes, forward)
|
||||
char := text.Get(tidx)
|
||||
if !caseSensitive {
|
||||
if char >= 'A' && char <= 'Z' {
|
||||
char += 32
|
||||
} else if char > unicode.MaxASCII {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
}
|
||||
|
||||
pidx_ := indexAt(pidx, lenPattern, forward)
|
||||
pchar := pattern[pidx_]
|
||||
if char == pchar {
|
||||
if pidx--; pidx < 0 {
|
||||
sidx = index
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if !forward {
|
||||
sidx, eidx = lenRunes-eidx, lenRunes-sidx
|
||||
}
|
||||
|
||||
score, pos := calculateScore(caseSensitive, normalize, text, pattern, sidx, eidx, withPos)
|
||||
return Result{sidx, eidx, score}, pos
|
||||
}
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// ExactMatchNaive is a basic string searching algorithm that handles case
|
||||
// sensitivity. Although naive, it still performs better than the combination
|
||||
// of strings.ToLower + strings.Index for typical fzf use cases where input
|
||||
// strings and patterns are not very long.
|
||||
//
|
||||
// Since 0.15.0, this function searches for the match with the highest
|
||||
// bonus point, instead of stopping immediately after finding the first match.
|
||||
// The solution is much cheaper since there is only one possible alignment of
|
||||
// the pattern.
|
||||
func ExactMatchNaive(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
if len(pattern) == 0 {
|
||||
return Result{0, 0, 0}, nil
|
||||
}
|
||||
|
||||
lenRunes := text.Length()
|
||||
lenPattern := len(pattern)
|
||||
|
||||
if lenRunes < lenPattern {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
if asciiFuzzyIndex(text, pattern, caseSensitive) < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// For simplicity, only look at the bonus at the first character position
|
||||
pidx := 0
|
||||
bestPos, bonus, bestBonus := -1, int16(0), int16(-1)
|
||||
for index := 0; index < lenRunes; index++ {
|
||||
index_ := indexAt(index, lenRunes, forward)
|
||||
char := text.Get(index_)
|
||||
if !caseSensitive {
|
||||
if char >= 'A' && char <= 'Z' {
|
||||
char += 32
|
||||
} else if char > unicode.MaxASCII {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
pidx_ := indexAt(pidx, lenPattern, forward)
|
||||
pchar := pattern[pidx_]
|
||||
if pchar == char {
|
||||
if pidx_ == 0 {
|
||||
bonus = bonusAt(text, index_)
|
||||
}
|
||||
pidx++
|
||||
if pidx == lenPattern {
|
||||
if bonus > bestBonus {
|
||||
bestPos, bestBonus = index, bonus
|
||||
}
|
||||
if bonus == bonusBoundary {
|
||||
break
|
||||
}
|
||||
index -= pidx - 1
|
||||
pidx, bonus = 0, 0
|
||||
}
|
||||
} else {
|
||||
index -= pidx
|
||||
pidx, bonus = 0, 0
|
||||
}
|
||||
}
|
||||
if bestPos >= 0 {
|
||||
var sidx, eidx int
|
||||
if forward {
|
||||
sidx = bestPos - lenPattern + 1
|
||||
eidx = bestPos + 1
|
||||
} else {
|
||||
sidx = lenRunes - (bestPos + 1)
|
||||
eidx = lenRunes - (bestPos - lenPattern + 1)
|
||||
}
|
||||
score, _ := calculateScore(caseSensitive, normalize, text, pattern, sidx, eidx, false)
|
||||
return Result{sidx, eidx, score}, nil
|
||||
}
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// PrefixMatch performs prefix-match
|
||||
func PrefixMatch(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
if len(pattern) == 0 {
|
||||
return Result{0, 0, 0}, nil
|
||||
}
|
||||
|
||||
trimmedLen := 0
|
||||
if !unicode.IsSpace(pattern[0]) {
|
||||
trimmedLen = text.LeadingWhitespaces()
|
||||
}
|
||||
|
||||
if text.Length()-trimmedLen < len(pattern) {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
for index, r := range pattern {
|
||||
char := text.Get(trimmedLen + index)
|
||||
if !caseSensitive {
|
||||
char = unicode.ToLower(char)
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
if char != r {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
}
|
||||
lenPattern := len(pattern)
|
||||
score, _ := calculateScore(caseSensitive, normalize, text, pattern, trimmedLen, trimmedLen+lenPattern, false)
|
||||
return Result{trimmedLen, trimmedLen + lenPattern, score}, nil
|
||||
}
|
||||
|
||||
// SuffixMatch performs suffix-match
|
||||
func SuffixMatch(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
lenRunes := text.Length()
|
||||
trimmedLen := lenRunes
|
||||
if len(pattern) == 0 || !unicode.IsSpace(pattern[len(pattern)-1]) {
|
||||
trimmedLen -= text.TrailingWhitespaces()
|
||||
}
|
||||
if len(pattern) == 0 {
|
||||
return Result{trimmedLen, trimmedLen, 0}, nil
|
||||
}
|
||||
diff := trimmedLen - len(pattern)
|
||||
if diff < 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
for index, r := range pattern {
|
||||
char := text.Get(index + diff)
|
||||
if !caseSensitive {
|
||||
char = unicode.ToLower(char)
|
||||
}
|
||||
if normalize {
|
||||
char = normalizeRune(char)
|
||||
}
|
||||
if char != r {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
}
|
||||
lenPattern := len(pattern)
|
||||
sidx := trimmedLen - lenPattern
|
||||
eidx := trimmedLen
|
||||
score, _ := calculateScore(caseSensitive, normalize, text, pattern, sidx, eidx, false)
|
||||
return Result{sidx, eidx, score}, nil
|
||||
}
|
||||
|
||||
// EqualMatch performs equal-match
|
||||
func EqualMatch(caseSensitive bool, normalize bool, forward bool, text *util.Chars, pattern []rune, withPos bool, slab *util.Slab) (Result, *[]int) {
|
||||
lenPattern := len(pattern)
|
||||
if lenPattern == 0 {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
|
||||
// Strip leading whitespaces
|
||||
trimmedLen := 0
|
||||
if !unicode.IsSpace(pattern[0]) {
|
||||
trimmedLen = text.LeadingWhitespaces()
|
||||
}
|
||||
|
||||
// Strip trailing whitespaces
|
||||
trimmedEndLen := 0
|
||||
if !unicode.IsSpace(pattern[lenPattern-1]) {
|
||||
trimmedEndLen = text.TrailingWhitespaces()
|
||||
}
|
||||
|
||||
if text.Length()-trimmedLen-trimmedEndLen != lenPattern {
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
match := true
|
||||
if normalize {
|
||||
runes := text.ToRunes()
|
||||
for idx, pchar := range pattern {
|
||||
char := runes[trimmedLen+idx]
|
||||
if !caseSensitive {
|
||||
char = unicode.To(unicode.LowerCase, char)
|
||||
}
|
||||
if normalizeRune(pchar) != normalizeRune(char) {
|
||||
match = false
|
||||
break
|
||||
}
|
||||
}
|
||||
} else {
|
||||
runes := text.ToRunes()
|
||||
runesStr := string(runes[trimmedLen : len(runes)-trimmedEndLen])
|
||||
if !caseSensitive {
|
||||
runesStr = strings.ToLower(runesStr)
|
||||
}
|
||||
match = runesStr == string(pattern)
|
||||
}
|
||||
if match {
|
||||
return Result{trimmedLen, trimmedLen + lenPattern, (scoreMatch+bonusBoundary)*lenPattern +
|
||||
(bonusFirstCharMultiplier-1)*bonusBoundary}, nil
|
||||
}
|
||||
return Result{-1, -1, 0}, nil
|
||||
}
|
||||
@ -1,197 +0,0 @@
|
||||
package algo
|
||||
|
||||
import (
|
||||
"math"
|
||||
"sort"
|
||||
"strings"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func assertMatch(t *testing.T, fun Algo, caseSensitive, forward bool, input, pattern string, sidx int, eidx int, score int) {
|
||||
assertMatch2(t, fun, caseSensitive, false, forward, input, pattern, sidx, eidx, score)
|
||||
}
|
||||
|
||||
func assertMatch2(t *testing.T, fun Algo, caseSensitive, normalize, forward bool, input, pattern string, sidx int, eidx int, score int) {
|
||||
if !caseSensitive {
|
||||
pattern = strings.ToLower(pattern)
|
||||
}
|
||||
chars := util.ToChars([]byte(input))
|
||||
res, pos := fun(caseSensitive, normalize, forward, &chars, []rune(pattern), true, nil)
|
||||
var start, end int
|
||||
if pos == nil || len(*pos) == 0 {
|
||||
start = res.Start
|
||||
end = res.End
|
||||
} else {
|
||||
sort.Ints(*pos)
|
||||
start = (*pos)[0]
|
||||
end = (*pos)[len(*pos)-1] + 1
|
||||
}
|
||||
if start != sidx {
|
||||
t.Errorf("Invalid start index: %d (expected: %d, %s / %s)", start, sidx, input, pattern)
|
||||
}
|
||||
if end != eidx {
|
||||
t.Errorf("Invalid end index: %d (expected: %d, %s / %s)", end, eidx, input, pattern)
|
||||
}
|
||||
if res.Score != score {
|
||||
t.Errorf("Invalid score: %d (expected: %d, %s / %s)", res.Score, score, input, pattern)
|
||||
}
|
||||
}
|
||||
|
||||
func TestFuzzyMatch(t *testing.T) {
|
||||
for _, fn := range []Algo{FuzzyMatchV1, FuzzyMatchV2} {
|
||||
for _, forward := range []bool{true, false} {
|
||||
assertMatch(t, fn, false, forward, "fooBarbaz1", "oBZ", 2, 9,
|
||||
scoreMatch*3+bonusCamel123+scoreGapStart+scoreGapExtension*3)
|
||||
assertMatch(t, fn, false, forward, "foo bar baz", "fbb", 0, 9,
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusBoundary*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "/AutomatorDocument.icns", "rdoc", 9, 13,
|
||||
scoreMatch*4+bonusCamel123+bonusConsecutive*2)
|
||||
assertMatch(t, fn, false, forward, "/man1/zshcompctl.1", "zshc", 6, 10,
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3)
|
||||
assertMatch(t, fn, false, forward, "/.oh-my-zsh/cache", "zshc", 8, 13,
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3+scoreGapStart)
|
||||
assertMatch(t, fn, false, forward, "ab0123 456", "12356", 3, 10,
|
||||
scoreMatch*5+bonusConsecutive*3+scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "abc123 456", "12356", 3, 10,
|
||||
scoreMatch*5+bonusCamel123*bonusFirstCharMultiplier+bonusCamel123*2+bonusConsecutive+scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "foo/bar/baz", "fbb", 0, 9,
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusBoundary*2+2*scoreGapStart+4*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "fooBarBaz", "fbb", 0, 7,
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+
|
||||
bonusCamel123*2+2*scoreGapStart+2*scoreGapExtension)
|
||||
assertMatch(t, fn, false, forward, "foo barbaz", "fbb", 0, 8,
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary+
|
||||
scoreGapStart*2+scoreGapExtension*3)
|
||||
assertMatch(t, fn, false, forward, "fooBar Baz", "foob", 0, 4,
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*3)
|
||||
assertMatch(t, fn, false, forward, "xFoo-Bar Baz", "foo-b", 1, 6,
|
||||
scoreMatch*5+bonusCamel123*bonusFirstCharMultiplier+bonusCamel123*2+
|
||||
bonusNonWord+bonusBoundary)
|
||||
|
||||
assertMatch(t, fn, true, forward, "fooBarbaz", "oBz", 2, 9,
|
||||
scoreMatch*3+bonusCamel123+scoreGapStart+scoreGapExtension*3)
|
||||
assertMatch(t, fn, true, forward, "Foo/Bar/Baz", "FBB", 0, 9,
|
||||
scoreMatch*3+bonusBoundary*(bonusFirstCharMultiplier+2)+
|
||||
scoreGapStart*2+scoreGapExtension*4)
|
||||
assertMatch(t, fn, true, forward, "FooBarBaz", "FBB", 0, 7,
|
||||
scoreMatch*3+bonusBoundary*bonusFirstCharMultiplier+bonusCamel123*2+
|
||||
scoreGapStart*2+scoreGapExtension*2)
|
||||
assertMatch(t, fn, true, forward, "FooBar Baz", "FooB", 0, 4,
|
||||
scoreMatch*4+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary*2+
|
||||
util.Max(bonusCamel123, bonusBoundary))
|
||||
|
||||
// Consecutive bonus updated
|
||||
assertMatch(t, fn, true, forward, "foo-bar", "o-ba", 2, 6,
|
||||
scoreMatch*4+bonusBoundary*3)
|
||||
|
||||
// Non-match
|
||||
assertMatch(t, fn, true, forward, "fooBarbaz", "oBZ", -1, -1, 0)
|
||||
assertMatch(t, fn, true, forward, "Foo Bar Baz", "fbb", -1, -1, 0)
|
||||
assertMatch(t, fn, true, forward, "fooBarbaz", "fooBarbazz", -1, -1, 0)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestFuzzyMatchBackward(t *testing.T) {
|
||||
assertMatch(t, FuzzyMatchV1, false, true, "foobar fb", "fb", 0, 4,
|
||||
scoreMatch*2+bonusBoundary*bonusFirstCharMultiplier+
|
||||
scoreGapStart+scoreGapExtension)
|
||||
assertMatch(t, FuzzyMatchV1, false, false, "foobar fb", "fb", 7, 9,
|
||||
scoreMatch*2+bonusBoundary*bonusFirstCharMultiplier+bonusBoundary)
|
||||
}
|
||||
|
||||
func TestExactMatchNaive(t *testing.T) {
|
||||
for _, dir := range []bool{true, false} {
|
||||
assertMatch(t, ExactMatchNaive, true, dir, "fooBarbaz", "oBA", -1, -1, 0)
|
||||
assertMatch(t, ExactMatchNaive, true, dir, "fooBarbaz", "fooBarbazz", -1, -1, 0)
|
||||
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "fooBarbaz", "oBA", 2, 5,
|
||||
scoreMatch*3+bonusCamel123+bonusConsecutive)
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/AutomatorDocument.icns", "rdoc", 9, 13,
|
||||
scoreMatch*4+bonusCamel123+bonusConsecutive*2)
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/man1/zshcompctl.1", "zshc", 6, 10,
|
||||
scoreMatch*4+bonusBoundary*(bonusFirstCharMultiplier+3))
|
||||
assertMatch(t, ExactMatchNaive, false, dir, "/.oh-my-zsh/cache", "zsh/c", 8, 13,
|
||||
scoreMatch*5+bonusBoundary*(bonusFirstCharMultiplier+4))
|
||||
}
|
||||
}
|
||||
|
||||
func TestExactMatchNaiveBackward(t *testing.T) {
|
||||
assertMatch(t, ExactMatchNaive, false, true, "foobar foob", "oo", 1, 3,
|
||||
scoreMatch*2+bonusConsecutive)
|
||||
assertMatch(t, ExactMatchNaive, false, false, "foobar foob", "oo", 8, 10,
|
||||
scoreMatch*2+bonusConsecutive)
|
||||
}
|
||||
|
||||
func TestPrefixMatch(t *testing.T) {
|
||||
score := (scoreMatch+bonusBoundary)*3 + bonusBoundary*(bonusFirstCharMultiplier-1)
|
||||
|
||||
for _, dir := range []bool{true, false} {
|
||||
assertMatch(t, PrefixMatch, true, dir, "fooBarbaz", "Foo", -1, -1, 0)
|
||||
assertMatch(t, PrefixMatch, false, dir, "fooBarBaz", "baz", -1, -1, 0)
|
||||
assertMatch(t, PrefixMatch, false, dir, "fooBarbaz", "Foo", 0, 3, score)
|
||||
assertMatch(t, PrefixMatch, false, dir, "foOBarBaZ", "foo", 0, 3, score)
|
||||
assertMatch(t, PrefixMatch, false, dir, "f-oBarbaz", "f-o", 0, 3, score)
|
||||
|
||||
assertMatch(t, PrefixMatch, false, dir, " fooBar", "foo", 1, 4, score)
|
||||
assertMatch(t, PrefixMatch, false, dir, " fooBar", " fo", 0, 3, score)
|
||||
assertMatch(t, PrefixMatch, false, dir, " fo", "foo", -1, -1, 0)
|
||||
}
|
||||
}
|
||||
|
||||
func TestSuffixMatch(t *testing.T) {
|
||||
for _, dir := range []bool{true, false} {
|
||||
assertMatch(t, SuffixMatch, true, dir, "fooBarbaz", "Baz", -1, -1, 0)
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz", "Foo", -1, -1, 0)
|
||||
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz", "baz", 6, 9,
|
||||
scoreMatch*3+bonusConsecutive*2)
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarBaZ", "baz", 6, 9,
|
||||
(scoreMatch+bonusCamel123)*3+bonusCamel123*(bonusFirstCharMultiplier-1))
|
||||
|
||||
// Strip trailing white space from the string
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz ", "baz", 6, 9,
|
||||
scoreMatch*3+bonusConsecutive*2)
|
||||
// Only when the pattern doesn't end with a space
|
||||
assertMatch(t, SuffixMatch, false, dir, "fooBarbaz ", "baz ", 6, 10,
|
||||
scoreMatch*4+bonusConsecutive*2+bonusNonWord)
|
||||
}
|
||||
}
|
||||
|
||||
func TestEmptyPattern(t *testing.T) {
|
||||
for _, dir := range []bool{true, false} {
|
||||
assertMatch(t, FuzzyMatchV1, true, dir, "foobar", "", 0, 0, 0)
|
||||
assertMatch(t, FuzzyMatchV2, true, dir, "foobar", "", 0, 0, 0)
|
||||
assertMatch(t, ExactMatchNaive, true, dir, "foobar", "", 0, 0, 0)
|
||||
assertMatch(t, PrefixMatch, true, dir, "foobar", "", 0, 0, 0)
|
||||
assertMatch(t, SuffixMatch, true, dir, "foobar", "", 6, 6, 0)
|
||||
}
|
||||
}
|
||||
|
||||
func TestNormalize(t *testing.T) {
|
||||
caseSensitive := false
|
||||
normalize := true
|
||||
forward := true
|
||||
test := func(input, pattern string, sidx, eidx, score int, funs ...Algo) {
|
||||
for _, fun := range funs {
|
||||
assertMatch2(t, fun, caseSensitive, normalize, forward,
|
||||
input, pattern, sidx, eidx, score)
|
||||
}
|
||||
}
|
||||
test("Só Danço Samba", "So", 0, 2, 56, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, ExactMatchNaive)
|
||||
test("Só Danço Samba", "sodc", 0, 7, 89, FuzzyMatchV1, FuzzyMatchV2)
|
||||
test("Danço", "danco", 0, 5, 128, FuzzyMatchV1, FuzzyMatchV2, PrefixMatch, SuffixMatch, ExactMatchNaive, EqualMatch)
|
||||
}
|
||||
|
||||
func TestLongString(t *testing.T) {
|
||||
bytes := make([]byte, math.MaxUint16*2)
|
||||
for i := range bytes {
|
||||
bytes[i] = 'x'
|
||||
}
|
||||
bytes[math.MaxUint16] = 'z'
|
||||
assertMatch(t, FuzzyMatchV2, true, true, string(bytes), "zx", math.MaxUint16, math.MaxUint16+2, scoreMatch*2+bonusConsecutive)
|
||||
}
|
||||
@ -1,492 +0,0 @@
|
||||
// Normalization of latin script letters
|
||||
// Reference: http://www.unicode.org/Public/UCD/latest/ucd/Index.txt
|
||||
|
||||
package algo
|
||||
|
||||
var normalized map[rune]rune = map[rune]rune{
|
||||
0x00E1: 'a', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0103: 'a', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01CE: 'a', // WITH CARON, LATIN SMALL LETTER
|
||||
0x00E2: 'a', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x00E4: 'a', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x0227: 'a', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1EA1: 'a', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0201: 'a', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x00E0: 'a', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1EA3: 'a', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x0203: 'a', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x0101: 'a', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x0105: 'a', // WITH OGONEK, LATIN SMALL LETTER
|
||||
0x1E9A: 'a', // WITH RIGHT HALF RING, LATIN SMALL LETTER
|
||||
0x00E5: 'a', // WITH RING ABOVE, LATIN SMALL LETTER
|
||||
0x1E01: 'a', // WITH RING BELOW, LATIN SMALL LETTER
|
||||
0x00E3: 'a', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x0363: 'a', // , COMBINING LATIN SMALL LETTER
|
||||
0x0250: 'a', // , LATIN SMALL LETTER TURNED
|
||||
0x1E03: 'b', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E05: 'b', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0253: 'b', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E07: 'b', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x0180: 'b', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x0183: 'b', // WITH TOPBAR, LATIN SMALL LETTER
|
||||
0x0107: 'c', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x010D: 'c', // WITH CARON, LATIN SMALL LETTER
|
||||
0x00E7: 'c', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x0109: 'c', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x0255: 'c', // WITH CURL, LATIN SMALL LETTER
|
||||
0x010B: 'c', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x0188: 'c', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x023C: 'c', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x0368: 'c', // , COMBINING LATIN SMALL LETTER
|
||||
0x0297: 'c', // , LATIN LETTER STRETCHED
|
||||
0x2184: 'c', // , LATIN SMALL LETTER REVERSED
|
||||
0x010F: 'd', // WITH CARON, LATIN SMALL LETTER
|
||||
0x1E11: 'd', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E13: 'd', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x0221: 'd', // WITH CURL, LATIN SMALL LETTER
|
||||
0x1E0B: 'd', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E0D: 'd', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0257: 'd', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E0F: 'd', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x0111: 'd', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x0256: 'd', // WITH TAIL, LATIN SMALL LETTER
|
||||
0x018C: 'd', // WITH TOPBAR, LATIN SMALL LETTER
|
||||
0x0369: 'd', // , COMBINING LATIN SMALL LETTER
|
||||
0x00E9: 'e', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0115: 'e', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x011B: 'e', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0229: 'e', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E19: 'e', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x00EA: 'e', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x00EB: 'e', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x0117: 'e', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1EB9: 'e', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0205: 'e', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x00E8: 'e', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1EBB: 'e', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x025D: 'e', // WITH HOOK, LATIN SMALL LETTER REVERSED OPEN
|
||||
0x0207: 'e', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x0113: 'e', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x0119: 'e', // WITH OGONEK, LATIN SMALL LETTER
|
||||
0x0247: 'e', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x1E1B: 'e', // WITH TILDE BELOW, LATIN SMALL LETTER
|
||||
0x1EBD: 'e', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x0364: 'e', // , COMBINING LATIN SMALL LETTER
|
||||
0x029A: 'e', // , LATIN SMALL LETTER CLOSED OPEN
|
||||
0x025E: 'e', // , LATIN SMALL LETTER CLOSED REVERSED OPEN
|
||||
0x025B: 'e', // , LATIN SMALL LETTER OPEN
|
||||
0x0258: 'e', // , LATIN SMALL LETTER REVERSED
|
||||
0x025C: 'e', // , LATIN SMALL LETTER REVERSED OPEN
|
||||
0x01DD: 'e', // , LATIN SMALL LETTER TURNED
|
||||
0x1D08: 'e', // , LATIN SMALL LETTER TURNED OPEN
|
||||
0x1E1F: 'f', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x0192: 'f', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x01F5: 'g', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x011F: 'g', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01E7: 'g', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0123: 'g', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x011D: 'g', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x0121: 'g', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x0260: 'g', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E21: 'g', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x01E5: 'g', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x0261: 'g', // , LATIN SMALL LETTER SCRIPT
|
||||
0x1E2B: 'h', // WITH BREVE BELOW, LATIN SMALL LETTER
|
||||
0x021F: 'h', // WITH CARON, LATIN SMALL LETTER
|
||||
0x1E29: 'h', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x0125: 'h', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x1E27: 'h', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1E23: 'h', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E25: 'h', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x02AE: 'h', // WITH FISHHOOK, LATIN SMALL LETTER TURNED
|
||||
0x0266: 'h', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E96: 'h', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x0127: 'h', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x036A: 'h', // , COMBINING LATIN SMALL LETTER
|
||||
0x0265: 'h', // , LATIN SMALL LETTER TURNED
|
||||
0x2095: 'h', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x00ED: 'i', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x012D: 'i', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01D0: 'i', // WITH CARON, LATIN SMALL LETTER
|
||||
0x00EE: 'i', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x00EF: 'i', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1ECB: 'i', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0209: 'i', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x00EC: 'i', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1EC9: 'i', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x020B: 'i', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x012B: 'i', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x012F: 'i', // WITH OGONEK, LATIN SMALL LETTER
|
||||
0x0268: 'i', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x1E2D: 'i', // WITH TILDE BELOW, LATIN SMALL LETTER
|
||||
0x0129: 'i', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x0365: 'i', // , COMBINING LATIN SMALL LETTER
|
||||
0x0131: 'i', // , LATIN SMALL LETTER DOTLESS
|
||||
0x1D09: 'i', // , LATIN SMALL LETTER TURNED
|
||||
0x1D62: 'i', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x2071: 'i', // , SUPERSCRIPT LATIN SMALL LETTER
|
||||
0x01F0: 'j', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0135: 'j', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x029D: 'j', // WITH CROSSED-TAIL, LATIN SMALL LETTER
|
||||
0x0249: 'j', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x025F: 'j', // WITH STROKE, LATIN SMALL LETTER DOTLESS
|
||||
0x0237: 'j', // , LATIN SMALL LETTER DOTLESS
|
||||
0x1E31: 'k', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x01E9: 'k', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0137: 'k', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E33: 'k', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0199: 'k', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E35: 'k', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x029E: 'k', // , LATIN SMALL LETTER TURNED
|
||||
0x2096: 'k', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x013A: 'l', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x019A: 'l', // WITH BAR, LATIN SMALL LETTER
|
||||
0x026C: 'l', // WITH BELT, LATIN SMALL LETTER
|
||||
0x013E: 'l', // WITH CARON, LATIN SMALL LETTER
|
||||
0x013C: 'l', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E3D: 'l', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x0234: 'l', // WITH CURL, LATIN SMALL LETTER
|
||||
0x1E37: 'l', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x1E3B: 'l', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x0140: 'l', // WITH MIDDLE DOT, LATIN SMALL LETTER
|
||||
0x026B: 'l', // WITH MIDDLE TILDE, LATIN SMALL LETTER
|
||||
0x026D: 'l', // WITH RETROFLEX HOOK, LATIN SMALL LETTER
|
||||
0x0142: 'l', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x2097: 'l', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x1E3F: 'm', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x1E41: 'm', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E43: 'm', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0271: 'm', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x0270: 'm', // WITH LONG LEG, LATIN SMALL LETTER TURNED
|
||||
0x036B: 'm', // , COMBINING LATIN SMALL LETTER
|
||||
0x1D1F: 'm', // , LATIN SMALL LETTER SIDEWAYS TURNED
|
||||
0x026F: 'm', // , LATIN SMALL LETTER TURNED
|
||||
0x2098: 'm', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x0144: 'n', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0148: 'n', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0146: 'n', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E4B: 'n', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x0235: 'n', // WITH CURL, LATIN SMALL LETTER
|
||||
0x1E45: 'n', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E47: 'n', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x01F9: 'n', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x0272: 'n', // WITH LEFT HOOK, LATIN SMALL LETTER
|
||||
0x1E49: 'n', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x019E: 'n', // WITH LONG RIGHT LEG, LATIN SMALL LETTER
|
||||
0x0273: 'n', // WITH RETROFLEX HOOK, LATIN SMALL LETTER
|
||||
0x00F1: 'n', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x2099: 'n', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x00F3: 'o', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x014F: 'o', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01D2: 'o', // WITH CARON, LATIN SMALL LETTER
|
||||
0x00F4: 'o', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x00F6: 'o', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x022F: 'o', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1ECD: 'o', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0151: 'o', // WITH DOUBLE ACUTE, LATIN SMALL LETTER
|
||||
0x020D: 'o', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x00F2: 'o', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1ECF: 'o', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x01A1: 'o', // WITH HORN, LATIN SMALL LETTER
|
||||
0x020F: 'o', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x014D: 'o', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x01EB: 'o', // WITH OGONEK, LATIN SMALL LETTER
|
||||
0x00F8: 'o', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x1D13: 'o', // WITH STROKE, LATIN SMALL LETTER SIDEWAYS
|
||||
0x00F5: 'o', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x0366: 'o', // , COMBINING LATIN SMALL LETTER
|
||||
0x0275: 'o', // , LATIN SMALL LETTER BARRED
|
||||
0x1D17: 'o', // , LATIN SMALL LETTER BOTTOM HALF
|
||||
0x0254: 'o', // , LATIN SMALL LETTER OPEN
|
||||
0x1D11: 'o', // , LATIN SMALL LETTER SIDEWAYS
|
||||
0x1D12: 'o', // , LATIN SMALL LETTER SIDEWAYS OPEN
|
||||
0x1D16: 'o', // , LATIN SMALL LETTER TOP HALF
|
||||
0x1E55: 'p', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x1E57: 'p', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x01A5: 'p', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x209A: 'p', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x024B: 'q', // WITH HOOK TAIL, LATIN SMALL LETTER
|
||||
0x02A0: 'q', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x0155: 'r', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0159: 'r', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0157: 'r', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E59: 'r', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E5B: 'r', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0211: 'r', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x027E: 'r', // WITH FISHHOOK, LATIN SMALL LETTER
|
||||
0x027F: 'r', // WITH FISHHOOK, LATIN SMALL LETTER REVERSED
|
||||
0x027B: 'r', // WITH HOOK, LATIN SMALL LETTER TURNED
|
||||
0x0213: 'r', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x1E5F: 'r', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x027C: 'r', // WITH LONG LEG, LATIN SMALL LETTER
|
||||
0x027A: 'r', // WITH LONG LEG, LATIN SMALL LETTER TURNED
|
||||
0x024D: 'r', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x027D: 'r', // WITH TAIL, LATIN SMALL LETTER
|
||||
0x036C: 'r', // , COMBINING LATIN SMALL LETTER
|
||||
0x0279: 'r', // , LATIN SMALL LETTER TURNED
|
||||
0x1D63: 'r', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x015B: 's', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0161: 's', // WITH CARON, LATIN SMALL LETTER
|
||||
0x015F: 's', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x015D: 's', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x0219: 's', // WITH COMMA BELOW, LATIN SMALL LETTER
|
||||
0x1E61: 's', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E9B: 's', // WITH DOT ABOVE, LATIN SMALL LETTER LONG
|
||||
0x1E63: 's', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0282: 's', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x023F: 's', // WITH SWASH TAIL, LATIN SMALL LETTER
|
||||
0x017F: 's', // , LATIN SMALL LETTER LONG
|
||||
0x00DF: 's', // , LATIN SMALL LETTER SHARP
|
||||
0x209B: 's', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x0165: 't', // WITH CARON, LATIN SMALL LETTER
|
||||
0x0163: 't', // WITH CEDILLA, LATIN SMALL LETTER
|
||||
0x1E71: 't', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x021B: 't', // WITH COMMA BELOW, LATIN SMALL LETTER
|
||||
0x0236: 't', // WITH CURL, LATIN SMALL LETTER
|
||||
0x1E97: 't', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1E6B: 't', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E6D: 't', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x01AD: 't', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E6F: 't', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x01AB: 't', // WITH PALATAL HOOK, LATIN SMALL LETTER
|
||||
0x0288: 't', // WITH RETROFLEX HOOK, LATIN SMALL LETTER
|
||||
0x0167: 't', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x036D: 't', // , COMBINING LATIN SMALL LETTER
|
||||
0x0287: 't', // , LATIN SMALL LETTER TURNED
|
||||
0x209C: 't', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x0289: 'u', // BAR, LATIN SMALL LETTER
|
||||
0x00FA: 'u', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x016D: 'u', // WITH BREVE, LATIN SMALL LETTER
|
||||
0x01D4: 'u', // WITH CARON, LATIN SMALL LETTER
|
||||
0x1E77: 'u', // WITH CIRCUMFLEX BELOW, LATIN SMALL LETTER
|
||||
0x00FB: 'u', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x1E73: 'u', // WITH DIAERESIS BELOW, LATIN SMALL LETTER
|
||||
0x00FC: 'u', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1EE5: 'u', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0171: 'u', // WITH DOUBLE ACUTE, LATIN SMALL LETTER
|
||||
0x0215: 'u', // WITH DOUBLE GRAVE, LATIN SMALL LETTER
|
||||
0x00F9: 'u', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1EE7: 'u', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x01B0: 'u', // WITH HORN, LATIN SMALL LETTER
|
||||
0x0217: 'u', // WITH INVERTED BREVE, LATIN SMALL LETTER
|
||||
0x016B: 'u', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x0173: 'u', // WITH OGONEK, LATIN SMALL LETTER
|
||||
0x016F: 'u', // WITH RING ABOVE, LATIN SMALL LETTER
|
||||
0x1E75: 'u', // WITH TILDE BELOW, LATIN SMALL LETTER
|
||||
0x0169: 'u', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x0367: 'u', // , COMBINING LATIN SMALL LETTER
|
||||
0x1D1D: 'u', // , LATIN SMALL LETTER SIDEWAYS
|
||||
0x1D1E: 'u', // , LATIN SMALL LETTER SIDEWAYS DIAERESIZED
|
||||
0x1D64: 'u', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x1E7F: 'v', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x028B: 'v', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E7D: 'v', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x036E: 'v', // , COMBINING LATIN SMALL LETTER
|
||||
0x028C: 'v', // , LATIN SMALL LETTER TURNED
|
||||
0x1D65: 'v', // , LATIN SUBSCRIPT SMALL LETTER
|
||||
0x1E83: 'w', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0175: 'w', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x1E85: 'w', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1E87: 'w', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E89: 'w', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x1E81: 'w', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1E98: 'w', // WITH RING ABOVE, LATIN SMALL LETTER
|
||||
0x028D: 'w', // , LATIN SMALL LETTER TURNED
|
||||
0x1E8D: 'x', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1E8B: 'x', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x036F: 'x', // , COMBINING LATIN SMALL LETTER
|
||||
0x00FD: 'y', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x0177: 'y', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x00FF: 'y', // WITH DIAERESIS, LATIN SMALL LETTER
|
||||
0x1E8F: 'y', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1EF5: 'y', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x1EF3: 'y', // WITH GRAVE, LATIN SMALL LETTER
|
||||
0x1EF7: 'y', // WITH HOOK ABOVE, LATIN SMALL LETTER
|
||||
0x01B4: 'y', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x0233: 'y', // WITH MACRON, LATIN SMALL LETTER
|
||||
0x1E99: 'y', // WITH RING ABOVE, LATIN SMALL LETTER
|
||||
0x024F: 'y', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x1EF9: 'y', // WITH TILDE, LATIN SMALL LETTER
|
||||
0x028E: 'y', // , LATIN SMALL LETTER TURNED
|
||||
0x017A: 'z', // WITH ACUTE, LATIN SMALL LETTER
|
||||
0x017E: 'z', // WITH CARON, LATIN SMALL LETTER
|
||||
0x1E91: 'z', // WITH CIRCUMFLEX, LATIN SMALL LETTER
|
||||
0x0291: 'z', // WITH CURL, LATIN SMALL LETTER
|
||||
0x017C: 'z', // WITH DOT ABOVE, LATIN SMALL LETTER
|
||||
0x1E93: 'z', // WITH DOT BELOW, LATIN SMALL LETTER
|
||||
0x0225: 'z', // WITH HOOK, LATIN SMALL LETTER
|
||||
0x1E95: 'z', // WITH LINE BELOW, LATIN SMALL LETTER
|
||||
0x0290: 'z', // WITH RETROFLEX HOOK, LATIN SMALL LETTER
|
||||
0x01B6: 'z', // WITH STROKE, LATIN SMALL LETTER
|
||||
0x0240: 'z', // WITH SWASH TAIL, LATIN SMALL LETTER
|
||||
0x0251: 'a', // , latin small letter script
|
||||
0x00C1: 'A', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x00C2: 'A', // WITH CIRCUMFLEX, LATIN CAPITAL LETTER
|
||||
0x00C4: 'A', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x00C0: 'A', // WITH GRAVE, LATIN CAPITAL LETTER
|
||||
0x00C5: 'A', // WITH RING ABOVE, LATIN CAPITAL LETTER
|
||||
0x023A: 'A', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x00C3: 'A', // WITH TILDE, LATIN CAPITAL LETTER
|
||||
0x1D00: 'A', // , LATIN LETTER SMALL CAPITAL
|
||||
0x0181: 'B', // WITH HOOK, LATIN CAPITAL LETTER
|
||||
0x0243: 'B', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x0299: 'B', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D03: 'B', // , LATIN LETTER SMALL CAPITAL BARRED
|
||||
0x00C7: 'C', // WITH CEDILLA, LATIN CAPITAL LETTER
|
||||
0x023B: 'C', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x1D04: 'C', // , LATIN LETTER SMALL CAPITAL
|
||||
0x018A: 'D', // WITH HOOK, LATIN CAPITAL LETTER
|
||||
0x0189: 'D', // , LATIN CAPITAL LETTER AFRICAN
|
||||
0x1D05: 'D', // , LATIN LETTER SMALL CAPITAL
|
||||
0x00C9: 'E', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x00CA: 'E', // WITH CIRCUMFLEX, LATIN CAPITAL LETTER
|
||||
0x00CB: 'E', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x00C8: 'E', // WITH GRAVE, LATIN CAPITAL LETTER
|
||||
0x0246: 'E', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x0190: 'E', // , LATIN CAPITAL LETTER OPEN
|
||||
0x018E: 'E', // , LATIN CAPITAL LETTER REVERSED
|
||||
0x1D07: 'E', // , LATIN LETTER SMALL CAPITAL
|
||||
0x0193: 'G', // WITH HOOK, LATIN CAPITAL LETTER
|
||||
0x029B: 'G', // WITH HOOK, LATIN LETTER SMALL CAPITAL
|
||||
0x0262: 'G', // , LATIN LETTER SMALL CAPITAL
|
||||
0x029C: 'H', // , LATIN LETTER SMALL CAPITAL
|
||||
0x00CD: 'I', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x00CE: 'I', // WITH CIRCUMFLEX, LATIN CAPITAL LETTER
|
||||
0x00CF: 'I', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x0130: 'I', // WITH DOT ABOVE, LATIN CAPITAL LETTER
|
||||
0x00CC: 'I', // WITH GRAVE, LATIN CAPITAL LETTER
|
||||
0x0197: 'I', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x026A: 'I', // , LATIN LETTER SMALL CAPITAL
|
||||
0x0248: 'J', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x1D0A: 'J', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D0B: 'K', // , LATIN LETTER SMALL CAPITAL
|
||||
0x023D: 'L', // WITH BAR, LATIN CAPITAL LETTER
|
||||
0x1D0C: 'L', // WITH STROKE, LATIN LETTER SMALL CAPITAL
|
||||
0x029F: 'L', // , LATIN LETTER SMALL CAPITAL
|
||||
0x019C: 'M', // , LATIN CAPITAL LETTER TURNED
|
||||
0x1D0D: 'M', // , LATIN LETTER SMALL CAPITAL
|
||||
0x019D: 'N', // WITH LEFT HOOK, LATIN CAPITAL LETTER
|
||||
0x0220: 'N', // WITH LONG RIGHT LEG, LATIN CAPITAL LETTER
|
||||
0x00D1: 'N', // WITH TILDE, LATIN CAPITAL LETTER
|
||||
0x0274: 'N', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D0E: 'N', // , LATIN LETTER SMALL CAPITAL REVERSED
|
||||
0x00D3: 'O', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x00D4: 'O', // WITH CIRCUMFLEX, LATIN CAPITAL LETTER
|
||||
0x00D6: 'O', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x00D2: 'O', // WITH GRAVE, LATIN CAPITAL LETTER
|
||||
0x019F: 'O', // WITH MIDDLE TILDE, LATIN CAPITAL LETTER
|
||||
0x00D8: 'O', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x00D5: 'O', // WITH TILDE, LATIN CAPITAL LETTER
|
||||
0x0186: 'O', // , LATIN CAPITAL LETTER OPEN
|
||||
0x1D0F: 'O', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D10: 'O', // , LATIN LETTER SMALL CAPITAL OPEN
|
||||
0x1D18: 'P', // , LATIN LETTER SMALL CAPITAL
|
||||
0x024A: 'Q', // WITH HOOK TAIL, LATIN CAPITAL LETTER SMALL
|
||||
0x024C: 'R', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x0280: 'R', // , LATIN LETTER SMALL CAPITAL
|
||||
0x0281: 'R', // , LATIN LETTER SMALL CAPITAL INVERTED
|
||||
0x1D19: 'R', // , LATIN LETTER SMALL CAPITAL REVERSED
|
||||
0x1D1A: 'R', // , LATIN LETTER SMALL CAPITAL TURNED
|
||||
0x023E: 'T', // WITH DIAGONAL STROKE, LATIN CAPITAL LETTER
|
||||
0x01AE: 'T', // WITH RETROFLEX HOOK, LATIN CAPITAL LETTER
|
||||
0x1D1B: 'T', // , LATIN LETTER SMALL CAPITAL
|
||||
0x0244: 'U', // BAR, LATIN CAPITAL LETTER
|
||||
0x00DA: 'U', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x00DB: 'U', // WITH CIRCUMFLEX, LATIN CAPITAL LETTER
|
||||
0x00DC: 'U', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x00D9: 'U', // WITH GRAVE, LATIN CAPITAL LETTER
|
||||
0x1D1C: 'U', // , LATIN LETTER SMALL CAPITAL
|
||||
0x01B2: 'V', // WITH HOOK, LATIN CAPITAL LETTER
|
||||
0x0245: 'V', // , LATIN CAPITAL LETTER TURNED
|
||||
0x1D20: 'V', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D21: 'W', // , LATIN LETTER SMALL CAPITAL
|
||||
0x00DD: 'Y', // WITH ACUTE, LATIN CAPITAL LETTER
|
||||
0x0178: 'Y', // WITH DIAERESIS, LATIN CAPITAL LETTER
|
||||
0x024E: 'Y', // WITH STROKE, LATIN CAPITAL LETTER
|
||||
0x028F: 'Y', // , LATIN LETTER SMALL CAPITAL
|
||||
0x1D22: 'Z', // , LATIN LETTER SMALL CAPITAL
|
||||
|
||||
'Ắ': 'A',
|
||||
'Ấ': 'A',
|
||||
'Ằ': 'A',
|
||||
'Ầ': 'A',
|
||||
'Ẳ': 'A',
|
||||
'Ẩ': 'A',
|
||||
'Ẵ': 'A',
|
||||
'Ẫ': 'A',
|
||||
'Ặ': 'A',
|
||||
'Ậ': 'A',
|
||||
|
||||
'ắ': 'a',
|
||||
'ấ': 'a',
|
||||
'ằ': 'a',
|
||||
'ầ': 'a',
|
||||
'ẳ': 'a',
|
||||
'ẩ': 'a',
|
||||
'ẵ': 'a',
|
||||
'ẫ': 'a',
|
||||
'ặ': 'a',
|
||||
'ậ': 'a',
|
||||
|
||||
'Ế': 'E',
|
||||
'Ề': 'E',
|
||||
'Ể': 'E',
|
||||
'Ễ': 'E',
|
||||
'Ệ': 'E',
|
||||
|
||||
'ế': 'e',
|
||||
'ề': 'e',
|
||||
'ể': 'e',
|
||||
'ễ': 'e',
|
||||
'ệ': 'e',
|
||||
|
||||
'Ố': 'O',
|
||||
'Ớ': 'O',
|
||||
'Ồ': 'O',
|
||||
'Ờ': 'O',
|
||||
'Ổ': 'O',
|
||||
'Ở': 'O',
|
||||
'Ỗ': 'O',
|
||||
'Ỡ': 'O',
|
||||
'Ộ': 'O',
|
||||
'Ợ': 'O',
|
||||
|
||||
'ố': 'o',
|
||||
'ớ': 'o',
|
||||
'ồ': 'o',
|
||||
'ờ': 'o',
|
||||
'ổ': 'o',
|
||||
'ở': 'o',
|
||||
'ỗ': 'o',
|
||||
'ỡ': 'o',
|
||||
'ộ': 'o',
|
||||
'ợ': 'o',
|
||||
|
||||
'Ứ': 'U',
|
||||
'Ừ': 'U',
|
||||
'Ử': 'U',
|
||||
'Ữ': 'U',
|
||||
'Ự': 'U',
|
||||
|
||||
'ứ': 'u',
|
||||
'ừ': 'u',
|
||||
'ử': 'u',
|
||||
'ữ': 'u',
|
||||
'ự': 'u',
|
||||
}
|
||||
|
||||
// NormalizeRunes normalizes latin script letters
|
||||
func NormalizeRunes(runes []rune) []rune {
|
||||
ret := make([]rune, len(runes))
|
||||
copy(ret, runes)
|
||||
for idx, r := range runes {
|
||||
if r < 0x00C0 || r > 0x2184 {
|
||||
continue
|
||||
}
|
||||
n := normalized[r]
|
||||
if n > 0 {
|
||||
ret[idx] = normalized[r]
|
||||
}
|
||||
}
|
||||
return ret
|
||||
}
|
||||
409
.fzf/src/ansi.go
409
.fzf/src/ansi.go
@ -1,409 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"strconv"
|
||||
"strings"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
)
|
||||
|
||||
type ansiOffset struct {
|
||||
offset [2]int32
|
||||
color ansiState
|
||||
}
|
||||
|
||||
type ansiState struct {
|
||||
fg tui.Color
|
||||
bg tui.Color
|
||||
attr tui.Attr
|
||||
lbg tui.Color
|
||||
}
|
||||
|
||||
func (s *ansiState) colored() bool {
|
||||
return s.fg != -1 || s.bg != -1 || s.attr > 0 || s.lbg >= 0
|
||||
}
|
||||
|
||||
func (s *ansiState) equals(t *ansiState) bool {
|
||||
if t == nil {
|
||||
return !s.colored()
|
||||
}
|
||||
return s.fg == t.fg && s.bg == t.bg && s.attr == t.attr && s.lbg == t.lbg
|
||||
}
|
||||
|
||||
func (s *ansiState) ToString() string {
|
||||
if !s.colored() {
|
||||
return ""
|
||||
}
|
||||
|
||||
ret := ""
|
||||
if s.attr&tui.Bold > 0 {
|
||||
ret += "1;"
|
||||
}
|
||||
if s.attr&tui.Dim > 0 {
|
||||
ret += "2;"
|
||||
}
|
||||
if s.attr&tui.Italic > 0 {
|
||||
ret += "3;"
|
||||
}
|
||||
if s.attr&tui.Underline > 0 {
|
||||
ret += "4;"
|
||||
}
|
||||
if s.attr&tui.Blink > 0 {
|
||||
ret += "5;"
|
||||
}
|
||||
if s.attr&tui.Reverse > 0 {
|
||||
ret += "7;"
|
||||
}
|
||||
ret += toAnsiString(s.fg, 30) + toAnsiString(s.bg, 40)
|
||||
|
||||
return "\x1b[" + strings.TrimSuffix(ret, ";") + "m"
|
||||
}
|
||||
|
||||
func toAnsiString(color tui.Color, offset int) string {
|
||||
col := int(color)
|
||||
ret := ""
|
||||
if col == -1 {
|
||||
ret += strconv.Itoa(offset + 9)
|
||||
} else if col < 8 {
|
||||
ret += strconv.Itoa(offset + col)
|
||||
} else if col < 16 {
|
||||
ret += strconv.Itoa(offset - 30 + 90 + col - 8)
|
||||
} else if col < 256 {
|
||||
ret += strconv.Itoa(offset+8) + ";5;" + strconv.Itoa(col)
|
||||
} else if col >= (1 << 24) {
|
||||
r := strconv.Itoa((col >> 16) & 0xff)
|
||||
g := strconv.Itoa((col >> 8) & 0xff)
|
||||
b := strconv.Itoa(col & 0xff)
|
||||
ret += strconv.Itoa(offset+8) + ";2;" + r + ";" + g + ";" + b
|
||||
}
|
||||
return ret + ";"
|
||||
}
|
||||
|
||||
func isPrint(c uint8) bool {
|
||||
return '\x20' <= c && c <= '\x7e'
|
||||
}
|
||||
|
||||
func matchOperatingSystemCommand(s string) int {
|
||||
// `\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
// ^ match starting here
|
||||
//
|
||||
i := 5 // prefix matched in nextAnsiEscapeSequence()
|
||||
for ; i < len(s) && isPrint(s[i]); i++ {
|
||||
}
|
||||
if i < len(s) {
|
||||
if s[i] == '\x07' {
|
||||
return i + 1
|
||||
}
|
||||
if s[i] == '\x1b' && i < len(s)-1 && s[i+1] == '\\' {
|
||||
return i + 2
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
func matchControlSequence(s string) int {
|
||||
// `\x1b[\\[()][0-9;?]*[a-zA-Z@]`
|
||||
// ^ match starting here
|
||||
//
|
||||
i := 2 // prefix matched in nextAnsiEscapeSequence()
|
||||
for ; i < len(s) && (isNumeric(s[i]) || s[i] == ';' || s[i] == '?'); i++ {
|
||||
}
|
||||
if i < len(s) {
|
||||
c := s[i]
|
||||
if 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' || c == '@' {
|
||||
return i + 1
|
||||
}
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
func isCtrlSeqStart(c uint8) bool {
|
||||
return c == '\\' || c == '[' || c == '(' || c == ')'
|
||||
}
|
||||
|
||||
// nextAnsiEscapeSequence returns the ANSI escape sequence and is equivalent to
|
||||
// calling FindStringIndex() on the below regex (which was originally used):
|
||||
//
|
||||
// "(?:\x1b[\\[()][0-9;?]*[a-zA-Z@]|\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)"
|
||||
//
|
||||
func nextAnsiEscapeSequence(s string) (int, int) {
|
||||
// fast check for ANSI escape sequences
|
||||
i := 0
|
||||
for ; i < len(s); i++ {
|
||||
switch s[i] {
|
||||
case '\x0e', '\x0f', '\x1b', '\x08':
|
||||
// We ignore the fact that '\x08' cannot be the first char
|
||||
// in the string and be an escape sequence for the sake of
|
||||
// speed and simplicity.
|
||||
goto Loop
|
||||
}
|
||||
}
|
||||
return -1, -1
|
||||
|
||||
Loop:
|
||||
for ; i < len(s); i++ {
|
||||
switch s[i] {
|
||||
case '\x08':
|
||||
// backtrack to match: `.\x08`
|
||||
if i > 0 && s[i-1] != '\n' {
|
||||
if s[i-1] < utf8.RuneSelf {
|
||||
return i - 1, i + 1
|
||||
}
|
||||
_, n := utf8.DecodeLastRuneInString(s[:i])
|
||||
return i - n, i + 1
|
||||
}
|
||||
case '\x1b':
|
||||
// match: `\x1b[\\[()][0-9;?]*[a-zA-Z@]`
|
||||
if i+2 < len(s) && isCtrlSeqStart(s[i+1]) {
|
||||
if j := matchControlSequence(s[i:]); j != -1 {
|
||||
return i, i + j
|
||||
}
|
||||
}
|
||||
|
||||
// match: `\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)`
|
||||
if i+5 < len(s) && s[i+1] == ']' && isNumeric(s[i+2]) &&
|
||||
s[i+3] == ';' && isPrint(s[i+4]) {
|
||||
|
||||
if j := matchOperatingSystemCommand(s[i:]); j != -1 {
|
||||
return i, i + j
|
||||
}
|
||||
}
|
||||
|
||||
// match: `\x1b.`
|
||||
if i+1 < len(s) && s[i+1] != '\n' {
|
||||
if s[i+1] < utf8.RuneSelf {
|
||||
return i, i + 2
|
||||
}
|
||||
_, n := utf8.DecodeRuneInString(s[i+1:])
|
||||
return i, i + n + 1
|
||||
}
|
||||
case '\x0e', '\x0f':
|
||||
// match: `[\x0e\x0f]`
|
||||
return i, i + 1
|
||||
}
|
||||
}
|
||||
return -1, -1
|
||||
}
|
||||
|
||||
func extractColor(str string, state *ansiState, proc func(string, *ansiState) bool) (string, *[]ansiOffset, *ansiState) {
|
||||
// We append to a stack allocated variable that we'll
|
||||
// later copy and return, to save on allocations.
|
||||
offsets := make([]ansiOffset, 0, 32)
|
||||
|
||||
if state != nil {
|
||||
offsets = append(offsets, ansiOffset{[2]int32{0, 0}, *state})
|
||||
}
|
||||
|
||||
var (
|
||||
pstate *ansiState // lazily allocated
|
||||
output strings.Builder
|
||||
prevIdx int
|
||||
runeCount int
|
||||
)
|
||||
for idx := 0; idx < len(str); {
|
||||
// Make sure that we found an ANSI code
|
||||
start, end := nextAnsiEscapeSequence(str[idx:])
|
||||
if start == -1 {
|
||||
break
|
||||
}
|
||||
start += idx
|
||||
idx += end
|
||||
|
||||
// Check if we should continue
|
||||
prev := str[prevIdx:start]
|
||||
if proc != nil && !proc(prev, state) {
|
||||
return "", nil, nil
|
||||
}
|
||||
prevIdx = idx
|
||||
|
||||
if len(prev) != 0 {
|
||||
runeCount += utf8.RuneCountInString(prev)
|
||||
// Grow the buffer size to the maximum possible length (string length
|
||||
// containing ansi codes) to avoid repetitive allocation
|
||||
if output.Cap() == 0 {
|
||||
output.Grow(len(str))
|
||||
}
|
||||
output.WriteString(prev)
|
||||
}
|
||||
|
||||
newState := interpretCode(str[start:idx], state)
|
||||
if !newState.equals(state) {
|
||||
if state != nil {
|
||||
// Update last offset
|
||||
(&offsets[len(offsets)-1]).offset[1] = int32(runeCount)
|
||||
}
|
||||
|
||||
if newState.colored() {
|
||||
// Append new offset
|
||||
if pstate == nil {
|
||||
pstate = &ansiState{}
|
||||
}
|
||||
*pstate = newState
|
||||
state = pstate
|
||||
offsets = append(offsets, ansiOffset{
|
||||
[2]int32{int32(runeCount), int32(runeCount)},
|
||||
newState,
|
||||
})
|
||||
} else {
|
||||
// Discard state
|
||||
state = nil
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
var rest string
|
||||
var trimmed string
|
||||
if prevIdx == 0 {
|
||||
// No ANSI code found
|
||||
rest = str
|
||||
trimmed = str
|
||||
} else {
|
||||
rest = str[prevIdx:]
|
||||
output.WriteString(rest)
|
||||
trimmed = output.String()
|
||||
}
|
||||
if proc != nil {
|
||||
proc(rest, state)
|
||||
}
|
||||
if len(offsets) > 0 {
|
||||
if len(rest) > 0 && state != nil {
|
||||
// Update last offset
|
||||
runeCount += utf8.RuneCountInString(rest)
|
||||
(&offsets[len(offsets)-1]).offset[1] = int32(runeCount)
|
||||
}
|
||||
// Return a copy of the offsets slice
|
||||
a := make([]ansiOffset, len(offsets))
|
||||
copy(a, offsets)
|
||||
return trimmed, &a, state
|
||||
}
|
||||
return trimmed, nil, state
|
||||
}
|
||||
|
||||
func parseAnsiCode(s string) (int, string) {
|
||||
var remaining string
|
||||
if i := strings.IndexByte(s, ';'); i >= 0 {
|
||||
remaining = s[i+1:]
|
||||
s = s[:i]
|
||||
}
|
||||
|
||||
if len(s) > 0 {
|
||||
// Inlined version of strconv.Atoi() that only handles positive
|
||||
// integers and does not allocate on error.
|
||||
code := 0
|
||||
for _, ch := range []byte(s) {
|
||||
ch -= '0'
|
||||
if ch > 9 {
|
||||
return -1, remaining
|
||||
}
|
||||
code = code*10 + int(ch)
|
||||
}
|
||||
return code, remaining
|
||||
}
|
||||
|
||||
return -1, remaining
|
||||
}
|
||||
|
||||
func interpretCode(ansiCode string, prevState *ansiState) ansiState {
|
||||
var state ansiState
|
||||
if prevState == nil {
|
||||
state = ansiState{-1, -1, 0, -1}
|
||||
} else {
|
||||
state = ansiState{prevState.fg, prevState.bg, prevState.attr, prevState.lbg}
|
||||
}
|
||||
if ansiCode[0] != '\x1b' || ansiCode[1] != '[' || ansiCode[len(ansiCode)-1] != 'm' {
|
||||
if prevState != nil && strings.HasSuffix(ansiCode, "0K") {
|
||||
state.lbg = prevState.bg
|
||||
}
|
||||
return state
|
||||
}
|
||||
|
||||
if len(ansiCode) <= 3 {
|
||||
state.fg = -1
|
||||
state.bg = -1
|
||||
state.attr = 0
|
||||
return state
|
||||
}
|
||||
ansiCode = ansiCode[2 : len(ansiCode)-1]
|
||||
|
||||
state256 := 0
|
||||
ptr := &state.fg
|
||||
|
||||
for len(ansiCode) != 0 {
|
||||
var num int
|
||||
if num, ansiCode = parseAnsiCode(ansiCode); num != -1 {
|
||||
switch state256 {
|
||||
case 0:
|
||||
switch num {
|
||||
case 38:
|
||||
ptr = &state.fg
|
||||
state256++
|
||||
case 48:
|
||||
ptr = &state.bg
|
||||
state256++
|
||||
case 39:
|
||||
state.fg = -1
|
||||
case 49:
|
||||
state.bg = -1
|
||||
case 1:
|
||||
state.attr = state.attr | tui.Bold
|
||||
case 2:
|
||||
state.attr = state.attr | tui.Dim
|
||||
case 3:
|
||||
state.attr = state.attr | tui.Italic
|
||||
case 4:
|
||||
state.attr = state.attr | tui.Underline
|
||||
case 5:
|
||||
state.attr = state.attr | tui.Blink
|
||||
case 7:
|
||||
state.attr = state.attr | tui.Reverse
|
||||
case 23: // tput rmso
|
||||
state.attr = state.attr &^ tui.Italic
|
||||
case 24: // tput rmul
|
||||
state.attr = state.attr &^ tui.Underline
|
||||
case 0:
|
||||
state.fg = -1
|
||||
state.bg = -1
|
||||
state.attr = 0
|
||||
state256 = 0
|
||||
default:
|
||||
if num >= 30 && num <= 37 {
|
||||
state.fg = tui.Color(num - 30)
|
||||
} else if num >= 40 && num <= 47 {
|
||||
state.bg = tui.Color(num - 40)
|
||||
} else if num >= 90 && num <= 97 {
|
||||
state.fg = tui.Color(num - 90 + 8)
|
||||
} else if num >= 100 && num <= 107 {
|
||||
state.bg = tui.Color(num - 100 + 8)
|
||||
}
|
||||
}
|
||||
case 1:
|
||||
switch num {
|
||||
case 2:
|
||||
state256 = 10 // MAGIC
|
||||
case 5:
|
||||
state256++
|
||||
default:
|
||||
state256 = 0
|
||||
}
|
||||
case 2:
|
||||
*ptr = tui.Color(num)
|
||||
state256 = 0
|
||||
case 10:
|
||||
*ptr = tui.Color(1<<24) | tui.Color(num<<16)
|
||||
state256++
|
||||
case 11:
|
||||
*ptr = *ptr | tui.Color(num<<8)
|
||||
state256++
|
||||
case 12:
|
||||
*ptr = *ptr | tui.Color(num)
|
||||
state256 = 0
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if state256 > 0 {
|
||||
*ptr = -1
|
||||
}
|
||||
return state
|
||||
}
|
||||
@ -1,427 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"math/rand"
|
||||
"regexp"
|
||||
"strings"
|
||||
"testing"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
)
|
||||
|
||||
// The following regular expression will include not all but most of the
|
||||
// frequently used ANSI sequences. This regex is used as a reference for
|
||||
// testing nextAnsiEscapeSequence().
|
||||
//
|
||||
// References:
|
||||
// - https://github.com/gnachman/iTerm2
|
||||
// - https://web.archive.org/web/20090204053813/http://ascii-table.com/ansi-escape-sequences.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences.php)
|
||||
// - https://web.archive.org/web/20090227051140/http://ascii-table.com/ansi-escape-sequences-vt-100.php
|
||||
// (archived from http://ascii-table.com/ansi-escape-sequences-vt-100.php)
|
||||
// - http://tldp.org/HOWTO/Bash-Prompt-HOWTO/x405.html
|
||||
// - https://invisible-island.net/xterm/ctlseqs/ctlseqs.html
|
||||
var ansiRegexReference = regexp.MustCompile("(?:\x1b[\\[()][0-9;]*[a-zA-Z@]|\x1b][0-9];[[:print:]]+(?:\x1b\\\\|\x07)|\x1b.|[\x0e\x0f]|.\x08)")
|
||||
|
||||
func testParserReference(t testing.TB, str string) {
|
||||
t.Helper()
|
||||
|
||||
toSlice := func(start, end int) []int {
|
||||
if start == -1 {
|
||||
return nil
|
||||
}
|
||||
return []int{start, end}
|
||||
}
|
||||
|
||||
s := str
|
||||
for i := 0; ; i++ {
|
||||
got := toSlice(nextAnsiEscapeSequence(s))
|
||||
exp := ansiRegexReference.FindStringIndex(s)
|
||||
|
||||
equal := len(got) == len(exp)
|
||||
if equal {
|
||||
for i := 0; i < len(got); i++ {
|
||||
if got[i] != exp[i] {
|
||||
equal = false
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
if !equal {
|
||||
var exps, gots []rune
|
||||
if len(got) == 2 {
|
||||
gots = []rune(s[got[0]:got[1]])
|
||||
}
|
||||
if len(exp) == 2 {
|
||||
exps = []rune(s[exp[0]:exp[1]])
|
||||
}
|
||||
t.Errorf("%d: %q: got: %v (%q) want: %v (%q)", i, s, got, gots, exp, exps)
|
||||
return
|
||||
}
|
||||
if len(exp) == 0 {
|
||||
return
|
||||
}
|
||||
s = s[exp[1]:]
|
||||
}
|
||||
}
|
||||
|
||||
func TestNextAnsiEscapeSequence(t *testing.T) {
|
||||
testStrs := []string{
|
||||
"\x1b[0mhello world",
|
||||
"\x1b[1mhello world",
|
||||
"椙\x1b[1m椙",
|
||||
"椙\x1b[1椙m椙",
|
||||
"\x1b[1mhello \x1b[mw\x1b7o\x1b8r\x1b(Bl\x1b[2@d",
|
||||
"\x1b[1mhello \x1b[Kworld",
|
||||
"hello \x1b[34;45;1mworld",
|
||||
"hello \x1b[34;45;1mwor\x1b[34;45;1mld",
|
||||
"hello \x1b[34;45;1mwor\x1b[0mld",
|
||||
"hello \x1b[34;48;5;233;1mwo\x1b[38;5;161mr\x1b[0ml\x1b[38;5;161md",
|
||||
"hello \x1b[38;5;38;48;5;48;1mwor\x1b[38;5;48;48;5;38ml\x1b[0md",
|
||||
"hello \x1b[32;1mworld",
|
||||
"hello world",
|
||||
"hello \x1b[0;38;5;200;48;5;100mworld",
|
||||
"\x1b椙",
|
||||
"椙\x08",
|
||||
"\n\x08",
|
||||
"X\x08",
|
||||
"",
|
||||
"\x1b]4;3;rgb:aa/bb/cc\x07 ",
|
||||
"\x1b]4;3;rgb:aa/bb/cc\x1b\\ ",
|
||||
ansiBenchmarkString,
|
||||
}
|
||||
|
||||
for _, s := range testStrs {
|
||||
testParserReference(t, s)
|
||||
}
|
||||
}
|
||||
|
||||
func TestNextAnsiEscapeSequence_Fuzz_Modified(t *testing.T) {
|
||||
t.Parallel()
|
||||
if testing.Short() {
|
||||
t.Skip("short test")
|
||||
}
|
||||
|
||||
testStrs := []string{
|
||||
"\x1b[0mhello world",
|
||||
"\x1b[1mhello world",
|
||||
"椙\x1b[1m椙",
|
||||
"椙\x1b[1椙m椙",
|
||||
"\x1b[1mhello \x1b[mw\x1b7o\x1b8r\x1b(Bl\x1b[2@d",
|
||||
"\x1b[1mhello \x1b[Kworld",
|
||||
"hello \x1b[34;45;1mworld",
|
||||
"hello \x1b[34;45;1mwor\x1b[34;45;1mld",
|
||||
"hello \x1b[34;45;1mwor\x1b[0mld",
|
||||
"hello \x1b[34;48;5;233;1mwo\x1b[38;5;161mr\x1b[0ml\x1b[38;5;161md",
|
||||
"hello \x1b[38;5;38;48;5;48;1mwor\x1b[38;5;48;48;5;38ml\x1b[0md",
|
||||
"hello \x1b[32;1mworld",
|
||||
"hello world",
|
||||
"hello \x1b[0;38;5;200;48;5;100mworld",
|
||||
ansiBenchmarkString,
|
||||
}
|
||||
|
||||
replacementBytes := [...]rune{'\x0e', '\x0f', '\x1b', '\x08'}
|
||||
|
||||
modifyString := func(s string, rr *rand.Rand) string {
|
||||
n := rr.Intn(len(s))
|
||||
b := []rune(s)
|
||||
for ; n >= 0 && len(b) != 0; n-- {
|
||||
i := rr.Intn(len(b))
|
||||
switch x := rr.Intn(4); x {
|
||||
case 0:
|
||||
b = append(b[:i], b[i+1:]...)
|
||||
case 1:
|
||||
j := rr.Intn(len(replacementBytes) - 1)
|
||||
b[i] = replacementBytes[j]
|
||||
case 2:
|
||||
x := rune(rr.Intn(utf8.MaxRune))
|
||||
for !utf8.ValidRune(x) {
|
||||
x = rune(rr.Intn(utf8.MaxRune))
|
||||
}
|
||||
b[i] = x
|
||||
case 3:
|
||||
b[i] = rune(rr.Intn(utf8.MaxRune)) // potentially invalid
|
||||
default:
|
||||
t.Fatalf("unsupported value: %d", x)
|
||||
}
|
||||
}
|
||||
return string(b)
|
||||
}
|
||||
|
||||
rr := rand.New(rand.NewSource(1))
|
||||
for _, s := range testStrs {
|
||||
for i := 1_000; i >= 0; i-- {
|
||||
testParserReference(t, modifyString(s, rr))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestNextAnsiEscapeSequence_Fuzz_Random(t *testing.T) {
|
||||
t.Parallel()
|
||||
|
||||
if testing.Short() {
|
||||
t.Skip("short test")
|
||||
}
|
||||
|
||||
randomString := func(rr *rand.Rand) string {
|
||||
numChars := rand.Intn(50)
|
||||
codePoints := make([]rune, numChars)
|
||||
for i := 0; i < len(codePoints); i++ {
|
||||
var r rune
|
||||
for n := 0; n < 1000; n++ {
|
||||
r = rune(rr.Intn(utf8.MaxRune))
|
||||
// Allow 10% of runes to be invalid
|
||||
if utf8.ValidRune(r) || rr.Float64() < 0.10 {
|
||||
break
|
||||
}
|
||||
}
|
||||
codePoints[i] = r
|
||||
}
|
||||
return string(codePoints)
|
||||
}
|
||||
|
||||
rr := rand.New(rand.NewSource(1))
|
||||
for i := 0; i < 100_000; i++ {
|
||||
testParserReference(t, randomString(rr))
|
||||
}
|
||||
}
|
||||
|
||||
func TestExtractColor(t *testing.T) {
|
||||
assert := func(offset ansiOffset, b int32, e int32, fg tui.Color, bg tui.Color, bold bool) {
|
||||
var attr tui.Attr
|
||||
if bold {
|
||||
attr = tui.Bold
|
||||
}
|
||||
if offset.offset[0] != b || offset.offset[1] != e ||
|
||||
offset.color.fg != fg || offset.color.bg != bg || offset.color.attr != attr {
|
||||
t.Error(offset, b, e, fg, bg, attr)
|
||||
}
|
||||
}
|
||||
|
||||
src := "hello world"
|
||||
var state *ansiState
|
||||
clean := "\x1b[0m"
|
||||
check := func(assertion func(ansiOffsets *[]ansiOffset, state *ansiState)) {
|
||||
output, ansiOffsets, newState := extractColor(src, state, nil)
|
||||
state = newState
|
||||
if output != "hello world" {
|
||||
t.Errorf("Invalid output: %s %v", output, []rune(output))
|
||||
}
|
||||
t.Log(src, ansiOffsets, clean)
|
||||
assertion(ansiOffsets, state)
|
||||
}
|
||||
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if offsets != nil {
|
||||
t.Fail()
|
||||
}
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "\x1b[0mhello world"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if offsets != nil {
|
||||
t.Fail()
|
||||
}
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "\x1b[1mhello world"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 11, -1, -1, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "\x1b[1mhello \x1b[mw\x1b7o\x1b8r\x1b(Bl\x1b[2@d"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 6, -1, -1, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "\x1b[1mhello \x1b[Kworld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 11, -1, -1, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "hello \x1b[34;45;1mworld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 11, 4, 5, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "hello \x1b[34;45;1mwor\x1b[34;45;1mld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 11, 4, 5, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "hello \x1b[34;45;1mwor\x1b[0mld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 9, 4, 5, true)
|
||||
})
|
||||
|
||||
state = nil
|
||||
src = "hello \x1b[34;48;5;233;1mwo\x1b[38;5;161mr\x1b[0ml\x1b[38;5;161md"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 3 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 8, 4, 233, true)
|
||||
assert((*offsets)[1], 8, 9, 161, 233, true)
|
||||
assert((*offsets)[2], 10, 11, 161, -1, false)
|
||||
})
|
||||
|
||||
// {38,48};5;{38,48}
|
||||
state = nil
|
||||
src = "hello \x1b[38;5;38;48;5;48;1mwor\x1b[38;5;48;48;5;38ml\x1b[0md"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 2 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 9, 38, 48, true)
|
||||
assert((*offsets)[1], 9, 10, 48, 38, true)
|
||||
})
|
||||
|
||||
src = "hello \x1b[32;1mworld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
if state.fg != 2 || state.bg != -1 || state.attr == 0 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 6, 11, 2, -1, true)
|
||||
})
|
||||
|
||||
src = "hello world"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 1 {
|
||||
t.Fail()
|
||||
}
|
||||
if state.fg != 2 || state.bg != -1 || state.attr == 0 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 11, 2, -1, true)
|
||||
})
|
||||
|
||||
src = "hello \x1b[0;38;5;200;48;5;100mworld"
|
||||
check(func(offsets *[]ansiOffset, state *ansiState) {
|
||||
if len(*offsets) != 2 {
|
||||
t.Fail()
|
||||
}
|
||||
if state.fg != 200 || state.bg != 100 || state.attr > 0 {
|
||||
t.Fail()
|
||||
}
|
||||
assert((*offsets)[0], 0, 6, 2, -1, true)
|
||||
assert((*offsets)[1], 6, 11, 200, 100, false)
|
||||
})
|
||||
}
|
||||
|
||||
func TestAnsiCodeStringConversion(t *testing.T) {
|
||||
assert := func(code string, prevState *ansiState, expected string) {
|
||||
state := interpretCode(code, prevState)
|
||||
if expected != state.ToString() {
|
||||
t.Errorf("expected: %s, actual: %s",
|
||||
strings.Replace(expected, "\x1b[", "\\x1b[", -1),
|
||||
strings.Replace(state.ToString(), "\x1b[", "\\x1b[", -1))
|
||||
}
|
||||
}
|
||||
assert("\x1b[m", nil, "")
|
||||
assert("\x1b[m", &ansiState{attr: tui.Blink, lbg: -1}, "")
|
||||
|
||||
assert("\x1b[31m", nil, "\x1b[31;49m")
|
||||
assert("\x1b[41m", nil, "\x1b[39;41m")
|
||||
|
||||
assert("\x1b[92m", nil, "\x1b[92;49m")
|
||||
assert("\x1b[102m", nil, "\x1b[39;102m")
|
||||
|
||||
assert("\x1b[31m", &ansiState{fg: 4, bg: 4, lbg: -1}, "\x1b[31;44m")
|
||||
assert("\x1b[1;2;31m", &ansiState{fg: 2, bg: -1, attr: tui.Reverse, lbg: -1}, "\x1b[1;2;7;31;49m")
|
||||
assert("\x1b[38;5;100;48;5;200m", nil, "\x1b[38;5;100;48;5;200m")
|
||||
assert("\x1b[48;5;100;38;5;200m", nil, "\x1b[38;5;200;48;5;100m")
|
||||
assert("\x1b[48;5;100;38;2;10;20;30;1m", nil, "\x1b[1;38;2;10;20;30;48;5;100m")
|
||||
assert("\x1b[48;5;100;38;2;10;20;30;7m",
|
||||
&ansiState{attr: tui.Dim | tui.Italic, fg: 1, bg: 1},
|
||||
"\x1b[2;3;7;38;2;10;20;30;48;5;100m")
|
||||
}
|
||||
|
||||
func TestParseAnsiCode(t *testing.T) {
|
||||
tests := []struct {
|
||||
In, Exp string
|
||||
N int
|
||||
}{
|
||||
{"123", "", 123},
|
||||
{"1a", "", -1},
|
||||
{"1a;12", "12", -1},
|
||||
{"12;a", "a", 12},
|
||||
{"-2", "", -1},
|
||||
}
|
||||
for _, x := range tests {
|
||||
n, s := parseAnsiCode(x.In)
|
||||
if n != x.N || s != x.Exp {
|
||||
t.Fatalf("%q: got: (%d %q) want: (%d %q)", x.In, n, s, x.N, x.Exp)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// kernel/bpf/preload/iterators/README
|
||||
const ansiBenchmarkString = "\x1b[38;5;81m\x1b[01;31m\x1b[Kkernel/\x1b[0m\x1b[38;5;81mbpf/" +
|
||||
"\x1b[0m\x1b[38;5;81mpreload/\x1b[0m\x1b[38;5;81miterators/" +
|
||||
"\x1b[0m\x1b[38;5;149mMakefile\x1b[m\x1b[K\x1b[0m"
|
||||
|
||||
func BenchmarkNextAnsiEscapeSequence(b *testing.B) {
|
||||
b.SetBytes(int64(len(ansiBenchmarkString)))
|
||||
for i := 0; i < b.N; i++ {
|
||||
s := ansiBenchmarkString
|
||||
for {
|
||||
_, o := nextAnsiEscapeSequence(s)
|
||||
if o == -1 {
|
||||
break
|
||||
}
|
||||
s = s[o:]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Baseline test to compare the speed of nextAnsiEscapeSequence() to the
|
||||
// previously used regex based implementation.
|
||||
func BenchmarkNextAnsiEscapeSequence_Regex(b *testing.B) {
|
||||
b.SetBytes(int64(len(ansiBenchmarkString)))
|
||||
for i := 0; i < b.N; i++ {
|
||||
s := ansiBenchmarkString
|
||||
for {
|
||||
a := ansiRegexReference.FindStringIndex(s)
|
||||
if len(a) == 0 {
|
||||
break
|
||||
}
|
||||
s = s[a[1]:]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func BenchmarkExtractColor(b *testing.B) {
|
||||
b.SetBytes(int64(len(ansiBenchmarkString)))
|
||||
for i := 0; i < b.N; i++ {
|
||||
extractColor(ansiBenchmarkString, nil, nil)
|
||||
}
|
||||
}
|
||||
@ -1,81 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import "sync"
|
||||
|
||||
// queryCache associates strings to lists of items
|
||||
type queryCache map[string][]Result
|
||||
|
||||
// ChunkCache associates Chunk and query string to lists of items
|
||||
type ChunkCache struct {
|
||||
mutex sync.Mutex
|
||||
cache map[*Chunk]*queryCache
|
||||
}
|
||||
|
||||
// NewChunkCache returns a new ChunkCache
|
||||
func NewChunkCache() ChunkCache {
|
||||
return ChunkCache{sync.Mutex{}, make(map[*Chunk]*queryCache)}
|
||||
}
|
||||
|
||||
// Add adds the list to the cache
|
||||
func (cc *ChunkCache) Add(chunk *Chunk, key string, list []Result) {
|
||||
if len(key) == 0 || !chunk.IsFull() || len(list) > queryCacheMax {
|
||||
return
|
||||
}
|
||||
|
||||
cc.mutex.Lock()
|
||||
defer cc.mutex.Unlock()
|
||||
|
||||
qc, ok := cc.cache[chunk]
|
||||
if !ok {
|
||||
cc.cache[chunk] = &queryCache{}
|
||||
qc = cc.cache[chunk]
|
||||
}
|
||||
(*qc)[key] = list
|
||||
}
|
||||
|
||||
// Lookup is called to lookup ChunkCache
|
||||
func (cc *ChunkCache) Lookup(chunk *Chunk, key string) []Result {
|
||||
if len(key) == 0 || !chunk.IsFull() {
|
||||
return nil
|
||||
}
|
||||
|
||||
cc.mutex.Lock()
|
||||
defer cc.mutex.Unlock()
|
||||
|
||||
qc, ok := cc.cache[chunk]
|
||||
if ok {
|
||||
list, ok := (*qc)[key]
|
||||
if ok {
|
||||
return list
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (cc *ChunkCache) Search(chunk *Chunk, key string) []Result {
|
||||
if len(key) == 0 || !chunk.IsFull() {
|
||||
return nil
|
||||
}
|
||||
|
||||
cc.mutex.Lock()
|
||||
defer cc.mutex.Unlock()
|
||||
|
||||
qc, ok := cc.cache[chunk]
|
||||
if !ok {
|
||||
return nil
|
||||
}
|
||||
|
||||
for idx := 1; idx < len(key); idx++ {
|
||||
// [---------| ] | [ |---------]
|
||||
// [--------| ] | [ |--------]
|
||||
// [-------| ] | [ |-------]
|
||||
prefix := key[:len(key)-idx]
|
||||
suffix := key[idx:]
|
||||
for _, substr := range [2]string{prefix, suffix} {
|
||||
if cached, found := (*qc)[substr]; found {
|
||||
return cached
|
||||
}
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
@ -1,39 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import "testing"
|
||||
|
||||
func TestChunkCache(t *testing.T) {
|
||||
cache := NewChunkCache()
|
||||
chunk1p := &Chunk{}
|
||||
chunk2p := &Chunk{count: chunkSize}
|
||||
items1 := []Result{{}}
|
||||
items2 := []Result{{}, {}}
|
||||
cache.Add(chunk1p, "foo", items1)
|
||||
cache.Add(chunk2p, "foo", items1)
|
||||
cache.Add(chunk2p, "bar", items2)
|
||||
|
||||
{ // chunk1 is not full
|
||||
cached := cache.Lookup(chunk1p, "foo")
|
||||
if cached != nil {
|
||||
t.Error("Cached disabled for non-empty chunks", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk2p, "foo")
|
||||
if cached == nil || len(cached) != 1 {
|
||||
t.Error("Expected 1 item cached", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk2p, "bar")
|
||||
if cached == nil || len(cached) != 2 {
|
||||
t.Error("Expected 2 items cached", cached)
|
||||
}
|
||||
}
|
||||
{
|
||||
cached := cache.Lookup(chunk1p, "foobar")
|
||||
if cached != nil {
|
||||
t.Error("Expected 0 item cached", cached)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1,89 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import "sync"
|
||||
|
||||
// Chunk is a list of Items whose size has the upper limit of chunkSize
|
||||
type Chunk struct {
|
||||
items [chunkSize]Item
|
||||
count int
|
||||
}
|
||||
|
||||
// ItemBuilder is a closure type that builds Item object from byte array
|
||||
type ItemBuilder func(*Item, []byte) bool
|
||||
|
||||
// ChunkList is a list of Chunks
|
||||
type ChunkList struct {
|
||||
chunks []*Chunk
|
||||
mutex sync.Mutex
|
||||
trans ItemBuilder
|
||||
}
|
||||
|
||||
// NewChunkList returns a new ChunkList
|
||||
func NewChunkList(trans ItemBuilder) *ChunkList {
|
||||
return &ChunkList{
|
||||
chunks: []*Chunk{},
|
||||
mutex: sync.Mutex{},
|
||||
trans: trans}
|
||||
}
|
||||
|
||||
func (c *Chunk) push(trans ItemBuilder, data []byte) bool {
|
||||
if trans(&c.items[c.count], data) {
|
||||
c.count++
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// IsFull returns true if the Chunk is full
|
||||
func (c *Chunk) IsFull() bool {
|
||||
return c.count == chunkSize
|
||||
}
|
||||
|
||||
func (cl *ChunkList) lastChunk() *Chunk {
|
||||
return cl.chunks[len(cl.chunks)-1]
|
||||
}
|
||||
|
||||
// CountItems returns the total number of Items
|
||||
func CountItems(cs []*Chunk) int {
|
||||
if len(cs) == 0 {
|
||||
return 0
|
||||
}
|
||||
return chunkSize*(len(cs)-1) + cs[len(cs)-1].count
|
||||
}
|
||||
|
||||
// Push adds the item to the list
|
||||
func (cl *ChunkList) Push(data []byte) bool {
|
||||
cl.mutex.Lock()
|
||||
|
||||
if len(cl.chunks) == 0 || cl.lastChunk().IsFull() {
|
||||
cl.chunks = append(cl.chunks, &Chunk{})
|
||||
}
|
||||
|
||||
ret := cl.lastChunk().push(cl.trans, data)
|
||||
cl.mutex.Unlock()
|
||||
return ret
|
||||
}
|
||||
|
||||
// Clear clears the data
|
||||
func (cl *ChunkList) Clear() {
|
||||
cl.mutex.Lock()
|
||||
cl.chunks = nil
|
||||
cl.mutex.Unlock()
|
||||
}
|
||||
|
||||
// Snapshot returns immutable snapshot of the ChunkList
|
||||
func (cl *ChunkList) Snapshot() ([]*Chunk, int) {
|
||||
cl.mutex.Lock()
|
||||
|
||||
ret := make([]*Chunk, len(cl.chunks))
|
||||
copy(ret, cl.chunks)
|
||||
|
||||
// Duplicate the last chunk
|
||||
if cnt := len(ret); cnt > 0 {
|
||||
newChunk := *ret[cnt-1]
|
||||
ret[cnt-1] = &newChunk
|
||||
}
|
||||
|
||||
cl.mutex.Unlock()
|
||||
return ret, CountItems(ret)
|
||||
}
|
||||
@ -1,80 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func TestChunkList(t *testing.T) {
|
||||
// FIXME global
|
||||
sortCriteria = []criterion{byScore, byLength}
|
||||
|
||||
cl := NewChunkList(func(item *Item, s []byte) bool {
|
||||
item.text = util.ToChars(s)
|
||||
return true
|
||||
})
|
||||
|
||||
// Snapshot
|
||||
snapshot, count := cl.Snapshot()
|
||||
if len(snapshot) > 0 || count > 0 {
|
||||
t.Error("Snapshot should be empty now")
|
||||
}
|
||||
|
||||
// Add some data
|
||||
cl.Push([]byte("hello"))
|
||||
cl.Push([]byte("world"))
|
||||
|
||||
// Previously created snapshot should remain the same
|
||||
if len(snapshot) > 0 {
|
||||
t.Error("Snapshot should not have changed")
|
||||
}
|
||||
|
||||
// But the new snapshot should contain the added items
|
||||
snapshot, count = cl.Snapshot()
|
||||
if len(snapshot) != 1 && count != 2 {
|
||||
t.Error("Snapshot should not be empty now")
|
||||
}
|
||||
|
||||
// Check the content of the ChunkList
|
||||
chunk1 := snapshot[0]
|
||||
if chunk1.count != 2 {
|
||||
t.Error("Snapshot should contain only two items")
|
||||
}
|
||||
if chunk1.items[0].text.ToString() != "hello" ||
|
||||
chunk1.items[1].text.ToString() != "world" {
|
||||
t.Error("Invalid data")
|
||||
}
|
||||
if chunk1.IsFull() {
|
||||
t.Error("Chunk should not have been marked full yet")
|
||||
}
|
||||
|
||||
// Add more data
|
||||
for i := 0; i < chunkSize*2; i++ {
|
||||
cl.Push([]byte(fmt.Sprintf("item %d", i)))
|
||||
}
|
||||
|
||||
// Previous snapshot should remain the same
|
||||
if len(snapshot) != 1 {
|
||||
t.Error("Snapshot should stay the same")
|
||||
}
|
||||
|
||||
// New snapshot
|
||||
snapshot, count = cl.Snapshot()
|
||||
if len(snapshot) != 3 || !snapshot[0].IsFull() ||
|
||||
!snapshot[1].IsFull() || snapshot[2].IsFull() || count != chunkSize*2+2 {
|
||||
t.Error("Expected two full chunks and one more chunk")
|
||||
}
|
||||
if snapshot[2].count != 2 {
|
||||
t.Error("Unexpected number of items")
|
||||
}
|
||||
|
||||
cl.Push([]byte("hello"))
|
||||
cl.Push([]byte("world"))
|
||||
|
||||
lastChunkCount := snapshot[len(snapshot)-1].count
|
||||
if lastChunkCount != 2 {
|
||||
t.Error("Unexpected number of items:", lastChunkCount)
|
||||
}
|
||||
}
|
||||
@ -1,85 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"os"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
const (
|
||||
// Core
|
||||
coordinatorDelayMax time.Duration = 100 * time.Millisecond
|
||||
coordinatorDelayStep time.Duration = 10 * time.Millisecond
|
||||
|
||||
// Reader
|
||||
readerBufferSize = 64 * 1024
|
||||
readerPollIntervalMin = 10 * time.Millisecond
|
||||
readerPollIntervalStep = 5 * time.Millisecond
|
||||
readerPollIntervalMax = 50 * time.Millisecond
|
||||
|
||||
// Terminal
|
||||
initialDelay = 20 * time.Millisecond
|
||||
initialDelayTac = 100 * time.Millisecond
|
||||
spinnerDuration = 100 * time.Millisecond
|
||||
previewCancelWait = 500 * time.Millisecond
|
||||
previewChunkDelay = 100 * time.Millisecond
|
||||
previewDelayed = 500 * time.Millisecond
|
||||
maxPatternLength = 300
|
||||
maxMulti = math.MaxInt32
|
||||
|
||||
// Matcher
|
||||
numPartitionsMultiplier = 8
|
||||
maxPartitions = 32
|
||||
progressMinDuration = 200 * time.Millisecond
|
||||
|
||||
// Capacity of each chunk
|
||||
chunkSize int = 100
|
||||
|
||||
// Pre-allocated memory slices to minimize GC
|
||||
slab16Size int = 100 * 1024 // 200KB * 32 = 12.8MB
|
||||
slab32Size int = 2048 // 8KB * 32 = 256KB
|
||||
|
||||
// Do not cache results of low selectivity queries
|
||||
queryCacheMax int = chunkSize / 5
|
||||
|
||||
// Not to cache mergers with large lists
|
||||
mergerCacheMax int = 100000
|
||||
|
||||
// History
|
||||
defaultHistoryMax int = 1000
|
||||
|
||||
// Jump labels
|
||||
defaultJumpLabels string = "asdfghjklqwertyuiopzxcvbnm1234567890ASDFGHJKLQWERTYUIOPZXCVBNM`~;:,<.>/?'\"!@#$%^&*()[{]}-_=+"
|
||||
)
|
||||
|
||||
var defaultCommand string
|
||||
|
||||
func init() {
|
||||
if !util.IsWindows() {
|
||||
defaultCommand = `set -o pipefail; command find -L . -mindepth 1 \( -path '*/\.*' -o -fstype 'sysfs' -o -fstype 'devfs' -o -fstype 'devtmpfs' -o -fstype 'proc' \) -prune -o -type f -print -o -type l -print 2> /dev/null | cut -b3-`
|
||||
} else if os.Getenv("TERM") == "cygwin" {
|
||||
defaultCommand = `sh -c "command find -L . -mindepth 1 -path '*/\.*' -prune -o -type f -print -o -type l -print 2> /dev/null | cut -b3-"`
|
||||
}
|
||||
}
|
||||
|
||||
// fzf events
|
||||
const (
|
||||
EvtReadNew util.EventType = iota
|
||||
EvtReadFin
|
||||
EvtSearchNew
|
||||
EvtSearchProgress
|
||||
EvtSearchFin
|
||||
EvtHeader
|
||||
EvtReady
|
||||
EvtQuit
|
||||
)
|
||||
|
||||
const (
|
||||
exitCancel = -1
|
||||
exitOk = 0
|
||||
exitNoMatch = 1
|
||||
exitError = 2
|
||||
exitInterrupt = 130
|
||||
)
|
||||
351
.fzf/src/core.go
351
.fzf/src/core.go
@ -1,351 +0,0 @@
|
||||
/*
|
||||
Package fzf implements fzf, a command-line fuzzy finder.
|
||||
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2013-2021 Junegunn Choi
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
*/
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
/*
|
||||
Reader -> EvtReadFin
|
||||
Reader -> EvtReadNew -> Matcher (restart)
|
||||
Terminal -> EvtSearchNew:bool -> Matcher (restart)
|
||||
Matcher -> EvtSearchProgress -> Terminal (update info)
|
||||
Matcher -> EvtSearchFin -> Terminal (update list)
|
||||
Matcher -> EvtHeader -> Terminal (update header)
|
||||
*/
|
||||
|
||||
// Run starts fzf
|
||||
func Run(opts *Options, version string, revision string) {
|
||||
sort := opts.Sort > 0
|
||||
sortCriteria = opts.Criteria
|
||||
|
||||
if opts.Version {
|
||||
if len(revision) > 0 {
|
||||
fmt.Printf("%s (%s)\n", version, revision)
|
||||
} else {
|
||||
fmt.Println(version)
|
||||
}
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
|
||||
// Event channel
|
||||
eventBox := util.NewEventBox()
|
||||
|
||||
// ANSI code processor
|
||||
ansiProcessor := func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
return util.ToChars(data), nil
|
||||
}
|
||||
|
||||
var lineAnsiState, prevLineAnsiState *ansiState
|
||||
if opts.Ansi {
|
||||
if opts.Theme.Colored {
|
||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
prevLineAnsiState = lineAnsiState
|
||||
trimmed, offsets, newState := extractColor(string(data), lineAnsiState, nil)
|
||||
lineAnsiState = newState
|
||||
return util.ToChars([]byte(trimmed)), offsets
|
||||
}
|
||||
} else {
|
||||
// When color is disabled but ansi option is given,
|
||||
// we simply strip out ANSI codes from the input
|
||||
ansiProcessor = func(data []byte) (util.Chars, *[]ansiOffset) {
|
||||
trimmed, _, _ := extractColor(string(data), nil, nil)
|
||||
return util.ToChars([]byte(trimmed)), nil
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Chunk list
|
||||
var chunkList *ChunkList
|
||||
var itemIndex int32
|
||||
header := make([]string, 0, opts.HeaderLines)
|
||||
if len(opts.WithNth) == 0 {
|
||||
chunkList = NewChunkList(func(item *Item, data []byte) bool {
|
||||
if len(header) < opts.HeaderLines {
|
||||
header = append(header, string(data))
|
||||
eventBox.Set(EvtHeader, header)
|
||||
return false
|
||||
}
|
||||
item.text, item.colors = ansiProcessor(data)
|
||||
item.text.Index = itemIndex
|
||||
itemIndex++
|
||||
return true
|
||||
})
|
||||
} else {
|
||||
chunkList = NewChunkList(func(item *Item, data []byte) bool {
|
||||
tokens := Tokenize(string(data), opts.Delimiter)
|
||||
if opts.Ansi && opts.Theme.Colored && len(tokens) > 1 {
|
||||
var ansiState *ansiState
|
||||
if prevLineAnsiState != nil {
|
||||
ansiStateDup := *prevLineAnsiState
|
||||
ansiState = &ansiStateDup
|
||||
}
|
||||
for _, token := range tokens {
|
||||
prevAnsiState := ansiState
|
||||
_, _, ansiState = extractColor(token.text.ToString(), ansiState, nil)
|
||||
if prevAnsiState != nil {
|
||||
token.text.Prepend("\x1b[m" + prevAnsiState.ToString())
|
||||
} else {
|
||||
token.text.Prepend("\x1b[m")
|
||||
}
|
||||
}
|
||||
}
|
||||
trans := Transform(tokens, opts.WithNth)
|
||||
transformed := joinTokens(trans)
|
||||
if len(header) < opts.HeaderLines {
|
||||
header = append(header, transformed)
|
||||
eventBox.Set(EvtHeader, header)
|
||||
return false
|
||||
}
|
||||
item.text, item.colors = ansiProcessor([]byte(transformed))
|
||||
item.text.TrimTrailingWhitespaces()
|
||||
item.text.Index = itemIndex
|
||||
item.origText = &data
|
||||
itemIndex++
|
||||
return true
|
||||
})
|
||||
}
|
||||
|
||||
// Reader
|
||||
streamingFilter := opts.Filter != nil && !sort && !opts.Tac && !opts.Sync
|
||||
var reader *Reader
|
||||
if !streamingFilter {
|
||||
reader = NewReader(func(data []byte) bool {
|
||||
return chunkList.Push(data)
|
||||
}, eventBox, opts.ReadZero, opts.Filter == nil)
|
||||
go reader.ReadSource()
|
||||
}
|
||||
|
||||
// Matcher
|
||||
forward := true
|
||||
for _, cri := range opts.Criteria[1:] {
|
||||
if cri == byEnd {
|
||||
forward = false
|
||||
break
|
||||
}
|
||||
if cri == byBegin {
|
||||
break
|
||||
}
|
||||
}
|
||||
patternBuilder := func(runes []rune) *Pattern {
|
||||
return BuildPattern(
|
||||
opts.Fuzzy, opts.FuzzyAlgo, opts.Extended, opts.Case, opts.Normalize, forward,
|
||||
opts.Filter == nil, opts.Nth, opts.Delimiter, runes)
|
||||
}
|
||||
matcher := NewMatcher(patternBuilder, sort, opts.Tac, eventBox)
|
||||
|
||||
// Filtering mode
|
||||
if opts.Filter != nil {
|
||||
if opts.PrintQuery {
|
||||
opts.Printer(*opts.Filter)
|
||||
}
|
||||
|
||||
pattern := patternBuilder([]rune(*opts.Filter))
|
||||
matcher.sort = pattern.sortable
|
||||
|
||||
found := false
|
||||
if streamingFilter {
|
||||
slab := util.MakeSlab(slab16Size, slab32Size)
|
||||
reader := NewReader(
|
||||
func(runes []byte) bool {
|
||||
item := Item{}
|
||||
if chunkList.trans(&item, runes) {
|
||||
if result, _, _ := pattern.MatchItem(&item, false, slab); result != nil {
|
||||
opts.Printer(item.text.ToString())
|
||||
found = true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}, eventBox, opts.ReadZero, false)
|
||||
reader.ReadSource()
|
||||
} else {
|
||||
eventBox.Unwatch(EvtReadNew)
|
||||
eventBox.WaitFor(EvtReadFin)
|
||||
|
||||
snapshot, _ := chunkList.Snapshot()
|
||||
merger, _ := matcher.scan(MatchRequest{
|
||||
chunks: snapshot,
|
||||
pattern: pattern})
|
||||
for i := 0; i < merger.Length(); i++ {
|
||||
opts.Printer(merger.Get(i).item.AsString(opts.Ansi))
|
||||
found = true
|
||||
}
|
||||
}
|
||||
if found {
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
os.Exit(exitNoMatch)
|
||||
}
|
||||
|
||||
// Synchronous search
|
||||
if opts.Sync {
|
||||
eventBox.Unwatch(EvtReadNew)
|
||||
eventBox.WaitFor(EvtReadFin)
|
||||
}
|
||||
|
||||
// Go interactive
|
||||
go matcher.Loop()
|
||||
|
||||
// Terminal I/O
|
||||
terminal := NewTerminal(opts, eventBox)
|
||||
deferred := opts.Select1 || opts.Exit0
|
||||
go terminal.Loop()
|
||||
if !deferred {
|
||||
terminal.startChan <- true
|
||||
}
|
||||
|
||||
// Event coordination
|
||||
reading := true
|
||||
clearCache := util.Once(false)
|
||||
clearSelection := util.Once(false)
|
||||
ticks := 0
|
||||
var nextCommand *string
|
||||
restart := func(command string) {
|
||||
reading = true
|
||||
clearCache = util.Once(true)
|
||||
clearSelection = util.Once(true)
|
||||
chunkList.Clear()
|
||||
itemIndex = 0
|
||||
header = make([]string, 0, opts.HeaderLines)
|
||||
go reader.restart(command)
|
||||
}
|
||||
eventBox.Watch(EvtReadNew)
|
||||
query := []rune{}
|
||||
for {
|
||||
delay := true
|
||||
ticks++
|
||||
input := func() []rune {
|
||||
paused, input := terminal.Input()
|
||||
if !paused {
|
||||
query = input
|
||||
}
|
||||
return query
|
||||
}
|
||||
eventBox.Wait(func(events *util.Events) {
|
||||
if _, fin := (*events)[EvtReadFin]; fin {
|
||||
delete(*events, EvtReadNew)
|
||||
}
|
||||
for evt, value := range *events {
|
||||
switch evt {
|
||||
case EvtQuit:
|
||||
if reading {
|
||||
reader.terminate()
|
||||
}
|
||||
os.Exit(value.(int))
|
||||
case EvtReadNew, EvtReadFin:
|
||||
if evt == EvtReadFin && nextCommand != nil {
|
||||
restart(*nextCommand)
|
||||
nextCommand = nil
|
||||
break
|
||||
} else {
|
||||
reading = reading && evt == EvtReadNew
|
||||
}
|
||||
snapshot, count := chunkList.Snapshot()
|
||||
terminal.UpdateCount(count, !reading, value.(*string))
|
||||
if opts.Sync {
|
||||
opts.Sync = false
|
||||
terminal.UpdateList(PassMerger(&snapshot, opts.Tac), false)
|
||||
}
|
||||
matcher.Reset(snapshot, input(), false, !reading, sort, clearCache())
|
||||
|
||||
case EvtSearchNew:
|
||||
var command *string
|
||||
switch val := value.(type) {
|
||||
case searchRequest:
|
||||
sort = val.sort
|
||||
command = val.command
|
||||
}
|
||||
if command != nil {
|
||||
if reading {
|
||||
reader.terminate()
|
||||
nextCommand = command
|
||||
} else {
|
||||
restart(*command)
|
||||
}
|
||||
break
|
||||
}
|
||||
snapshot, _ := chunkList.Snapshot()
|
||||
matcher.Reset(snapshot, input(), true, !reading, sort, clearCache())
|
||||
delay = false
|
||||
|
||||
case EvtSearchProgress:
|
||||
switch val := value.(type) {
|
||||
case float32:
|
||||
terminal.UpdateProgress(val)
|
||||
}
|
||||
|
||||
case EvtHeader:
|
||||
headerPadded := make([]string, opts.HeaderLines)
|
||||
copy(headerPadded, value.([]string))
|
||||
terminal.UpdateHeader(headerPadded)
|
||||
|
||||
case EvtSearchFin:
|
||||
switch val := value.(type) {
|
||||
case *Merger:
|
||||
if deferred {
|
||||
count := val.Length()
|
||||
if opts.Select1 && count > 1 || opts.Exit0 && !opts.Select1 && count > 0 {
|
||||
deferred = false
|
||||
terminal.startChan <- true
|
||||
} else if val.final {
|
||||
if opts.Exit0 && count == 0 || opts.Select1 && count == 1 {
|
||||
if opts.PrintQuery {
|
||||
opts.Printer(opts.Query)
|
||||
}
|
||||
if len(opts.Expect) > 0 {
|
||||
opts.Printer("")
|
||||
}
|
||||
for i := 0; i < count; i++ {
|
||||
opts.Printer(val.Get(i).item.AsString(opts.Ansi))
|
||||
}
|
||||
if count > 0 {
|
||||
os.Exit(exitOk)
|
||||
}
|
||||
os.Exit(exitNoMatch)
|
||||
}
|
||||
deferred = false
|
||||
terminal.startChan <- true
|
||||
}
|
||||
}
|
||||
terminal.UpdateList(val, clearSelection())
|
||||
}
|
||||
}
|
||||
}
|
||||
events.Clear()
|
||||
})
|
||||
if delay && reading {
|
||||
dur := util.DurWithin(
|
||||
time.Duration(ticks)*coordinatorDelayStep,
|
||||
0, coordinatorDelayMax)
|
||||
time.Sleep(dur)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1,96 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// History struct represents input history
|
||||
type History struct {
|
||||
path string
|
||||
lines []string
|
||||
modified map[int]string
|
||||
maxSize int
|
||||
cursor int
|
||||
}
|
||||
|
||||
// NewHistory returns the pointer to a new History struct
|
||||
func NewHistory(path string, maxSize int) (*History, error) {
|
||||
fmtError := func(e error) error {
|
||||
if os.IsPermission(e) {
|
||||
return errors.New("permission denied: " + path)
|
||||
}
|
||||
return errors.New("invalid history file: " + e.Error())
|
||||
}
|
||||
|
||||
// Read history file
|
||||
data, err := ioutil.ReadFile(path)
|
||||
if err != nil {
|
||||
// If it doesn't exist, check if we can create a file with the name
|
||||
if os.IsNotExist(err) {
|
||||
data = []byte{}
|
||||
if err := ioutil.WriteFile(path, data, 0600); err != nil {
|
||||
return nil, fmtError(err)
|
||||
}
|
||||
} else {
|
||||
return nil, fmtError(err)
|
||||
}
|
||||
}
|
||||
// Split lines and limit the maximum number of lines
|
||||
lines := strings.Split(strings.Trim(string(data), "\n"), "\n")
|
||||
if len(lines[len(lines)-1]) > 0 {
|
||||
lines = append(lines, "")
|
||||
}
|
||||
return &History{
|
||||
path: path,
|
||||
maxSize: maxSize,
|
||||
lines: lines,
|
||||
modified: make(map[int]string),
|
||||
cursor: len(lines) - 1}, nil
|
||||
}
|
||||
|
||||
func (h *History) append(line string) error {
|
||||
// We don't append empty lines
|
||||
if len(line) == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
lines := append(h.lines[:len(h.lines)-1], line)
|
||||
if len(lines) > h.maxSize {
|
||||
lines = lines[len(lines)-h.maxSize:]
|
||||
}
|
||||
h.lines = append(lines, "")
|
||||
return ioutil.WriteFile(h.path, []byte(strings.Join(h.lines, "\n")), 0600)
|
||||
}
|
||||
|
||||
func (h *History) override(str string) {
|
||||
// You can update the history but they're not written to the file
|
||||
if h.cursor == len(h.lines)-1 {
|
||||
h.lines[h.cursor] = str
|
||||
} else if h.cursor < len(h.lines)-1 {
|
||||
h.modified[h.cursor] = str
|
||||
}
|
||||
}
|
||||
|
||||
func (h *History) current() string {
|
||||
if str, prs := h.modified[h.cursor]; prs {
|
||||
return str
|
||||
}
|
||||
return h.lines[h.cursor]
|
||||
}
|
||||
|
||||
func (h *History) previous() string {
|
||||
if h.cursor > 0 {
|
||||
h.cursor--
|
||||
}
|
||||
return h.current()
|
||||
}
|
||||
|
||||
func (h *History) next() string {
|
||||
if h.cursor < len(h.lines)-1 {
|
||||
h.cursor++
|
||||
}
|
||||
return h.current()
|
||||
}
|
||||
@ -1,68 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"runtime"
|
||||
"testing"
|
||||
)
|
||||
|
||||
func TestHistory(t *testing.T) {
|
||||
maxHistory := 50
|
||||
|
||||
// Invalid arguments
|
||||
var paths []string
|
||||
if runtime.GOOS == "windows" {
|
||||
// GOPATH should exist, so we shouldn't be able to override it
|
||||
paths = []string{os.Getenv("GOPATH")}
|
||||
} else {
|
||||
paths = []string{"/etc", "/proc"}
|
||||
}
|
||||
|
||||
for _, path := range paths {
|
||||
if _, e := NewHistory(path, maxHistory); e == nil {
|
||||
t.Error("Error expected for: " + path)
|
||||
}
|
||||
}
|
||||
|
||||
f, _ := ioutil.TempFile("", "fzf-history")
|
||||
f.Close()
|
||||
|
||||
{ // Append lines
|
||||
h, _ := NewHistory(f.Name(), maxHistory)
|
||||
for i := 0; i < maxHistory+10; i++ {
|
||||
h.append("foobar")
|
||||
}
|
||||
}
|
||||
{ // Read lines
|
||||
h, _ := NewHistory(f.Name(), maxHistory)
|
||||
if len(h.lines) != maxHistory+1 {
|
||||
t.Errorf("Expected: %d, actual: %d\n", maxHistory+1, len(h.lines))
|
||||
}
|
||||
for i := 0; i < maxHistory; i++ {
|
||||
if h.lines[i] != "foobar" {
|
||||
t.Error("Expected: foobar, actual: " + h.lines[i])
|
||||
}
|
||||
}
|
||||
}
|
||||
{ // Append lines
|
||||
h, _ := NewHistory(f.Name(), maxHistory)
|
||||
h.append("barfoo")
|
||||
h.append("")
|
||||
h.append("foobarbaz")
|
||||
}
|
||||
{ // Read lines again
|
||||
h, _ := NewHistory(f.Name(), maxHistory)
|
||||
if len(h.lines) != maxHistory+1 {
|
||||
t.Errorf("Expected: %d, actual: %d\n", maxHistory+1, len(h.lines))
|
||||
}
|
||||
compare := func(idx int, exp string) {
|
||||
if h.lines[idx] != exp {
|
||||
t.Errorf("Expected: %s, actual: %s\n", exp, h.lines[idx])
|
||||
}
|
||||
}
|
||||
compare(maxHistory-3, "foobar")
|
||||
compare(maxHistory-2, "barfoo")
|
||||
compare(maxHistory-1, "foobarbaz")
|
||||
}
|
||||
}
|
||||
@ -1,44 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
// Item represents each input line. 56 bytes.
|
||||
type Item struct {
|
||||
text util.Chars // 32 = 24 + 1 + 1 + 2 + 4
|
||||
transformed *[]Token // 8
|
||||
origText *[]byte // 8
|
||||
colors *[]ansiOffset // 8
|
||||
}
|
||||
|
||||
// Index returns ordinal index of the Item
|
||||
func (item *Item) Index() int32 {
|
||||
return item.text.Index
|
||||
}
|
||||
|
||||
var minItem = Item{text: util.Chars{Index: -1}}
|
||||
|
||||
func (item *Item) TrimLength() uint16 {
|
||||
return item.text.TrimLength()
|
||||
}
|
||||
|
||||
// Colors returns ansiOffsets of the Item
|
||||
func (item *Item) Colors() []ansiOffset {
|
||||
if item.colors == nil {
|
||||
return []ansiOffset{}
|
||||
}
|
||||
return *item.colors
|
||||
}
|
||||
|
||||
// AsString returns the original string
|
||||
func (item *Item) AsString(stripAnsi bool) string {
|
||||
if item.origText != nil {
|
||||
if stripAnsi {
|
||||
trimmed, _, _ := extractColor(string(*item.origText), nil, nil)
|
||||
return trimmed
|
||||
}
|
||||
return string(*item.origText)
|
||||
}
|
||||
return item.text.ToString()
|
||||
}
|
||||
@ -1,23 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func TestStringPtr(t *testing.T) {
|
||||
orig := []byte("\x1b[34mfoo")
|
||||
text := []byte("\x1b[34mbar")
|
||||
item := Item{origText: &orig, text: util.ToChars(text)}
|
||||
if item.AsString(true) != "foo" || item.AsString(false) != string(orig) {
|
||||
t.Fail()
|
||||
}
|
||||
if item.AsString(true) != "foo" {
|
||||
t.Fail()
|
||||
}
|
||||
item.origText = nil
|
||||
if item.AsString(true) != string(text) || item.AsString(false) != string(text) {
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
@ -1,235 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"runtime"
|
||||
"sort"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
// MatchRequest represents a search request
|
||||
type MatchRequest struct {
|
||||
chunks []*Chunk
|
||||
pattern *Pattern
|
||||
final bool
|
||||
sort bool
|
||||
clearCache bool
|
||||
}
|
||||
|
||||
// Matcher is responsible for performing search
|
||||
type Matcher struct {
|
||||
patternBuilder func([]rune) *Pattern
|
||||
sort bool
|
||||
tac bool
|
||||
eventBox *util.EventBox
|
||||
reqBox *util.EventBox
|
||||
partitions int
|
||||
slab []*util.Slab
|
||||
mergerCache map[string]*Merger
|
||||
}
|
||||
|
||||
const (
|
||||
reqRetry util.EventType = iota
|
||||
reqReset
|
||||
)
|
||||
|
||||
// NewMatcher returns a new Matcher
|
||||
func NewMatcher(patternBuilder func([]rune) *Pattern,
|
||||
sort bool, tac bool, eventBox *util.EventBox) *Matcher {
|
||||
partitions := util.Min(numPartitionsMultiplier*runtime.NumCPU(), maxPartitions)
|
||||
return &Matcher{
|
||||
patternBuilder: patternBuilder,
|
||||
sort: sort,
|
||||
tac: tac,
|
||||
eventBox: eventBox,
|
||||
reqBox: util.NewEventBox(),
|
||||
partitions: partitions,
|
||||
slab: make([]*util.Slab, partitions),
|
||||
mergerCache: make(map[string]*Merger)}
|
||||
}
|
||||
|
||||
// Loop puts Matcher in action
|
||||
func (m *Matcher) Loop() {
|
||||
prevCount := 0
|
||||
|
||||
for {
|
||||
var request MatchRequest
|
||||
|
||||
m.reqBox.Wait(func(events *util.Events) {
|
||||
for _, val := range *events {
|
||||
switch val := val.(type) {
|
||||
case MatchRequest:
|
||||
request = val
|
||||
default:
|
||||
panic(fmt.Sprintf("Unexpected type: %T", val))
|
||||
}
|
||||
}
|
||||
events.Clear()
|
||||
})
|
||||
|
||||
if request.sort != m.sort || request.clearCache {
|
||||
m.sort = request.sort
|
||||
m.mergerCache = make(map[string]*Merger)
|
||||
clearChunkCache()
|
||||
}
|
||||
|
||||
// Restart search
|
||||
patternString := request.pattern.AsString()
|
||||
var merger *Merger
|
||||
cancelled := false
|
||||
count := CountItems(request.chunks)
|
||||
|
||||
foundCache := false
|
||||
if count == prevCount {
|
||||
// Look up mergerCache
|
||||
if cached, found := m.mergerCache[patternString]; found {
|
||||
foundCache = true
|
||||
merger = cached
|
||||
}
|
||||
} else {
|
||||
// Invalidate mergerCache
|
||||
prevCount = count
|
||||
m.mergerCache = make(map[string]*Merger)
|
||||
}
|
||||
|
||||
if !foundCache {
|
||||
merger, cancelled = m.scan(request)
|
||||
}
|
||||
|
||||
if !cancelled {
|
||||
if merger.cacheable() {
|
||||
m.mergerCache[patternString] = merger
|
||||
}
|
||||
merger.final = request.final
|
||||
m.eventBox.Set(EvtSearchFin, merger)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (m *Matcher) sliceChunks(chunks []*Chunk) [][]*Chunk {
|
||||
partitions := m.partitions
|
||||
perSlice := len(chunks) / partitions
|
||||
|
||||
if perSlice == 0 {
|
||||
partitions = len(chunks)
|
||||
perSlice = 1
|
||||
}
|
||||
|
||||
slices := make([][]*Chunk, partitions)
|
||||
for i := 0; i < partitions; i++ {
|
||||
start := i * perSlice
|
||||
end := start + perSlice
|
||||
if i == partitions-1 {
|
||||
end = len(chunks)
|
||||
}
|
||||
slices[i] = chunks[start:end]
|
||||
}
|
||||
return slices
|
||||
}
|
||||
|
||||
type partialResult struct {
|
||||
index int
|
||||
matches []Result
|
||||
}
|
||||
|
||||
func (m *Matcher) scan(request MatchRequest) (*Merger, bool) {
|
||||
startedAt := time.Now()
|
||||
|
||||
numChunks := len(request.chunks)
|
||||
if numChunks == 0 {
|
||||
return EmptyMerger, false
|
||||
}
|
||||
pattern := request.pattern
|
||||
if pattern.IsEmpty() {
|
||||
return PassMerger(&request.chunks, m.tac), false
|
||||
}
|
||||
|
||||
cancelled := util.NewAtomicBool(false)
|
||||
|
||||
slices := m.sliceChunks(request.chunks)
|
||||
numSlices := len(slices)
|
||||
resultChan := make(chan partialResult, numSlices)
|
||||
countChan := make(chan int, numChunks)
|
||||
waitGroup := sync.WaitGroup{}
|
||||
|
||||
for idx, chunks := range slices {
|
||||
waitGroup.Add(1)
|
||||
if m.slab[idx] == nil {
|
||||
m.slab[idx] = util.MakeSlab(slab16Size, slab32Size)
|
||||
}
|
||||
go func(idx int, slab *util.Slab, chunks []*Chunk) {
|
||||
defer func() { waitGroup.Done() }()
|
||||
count := 0
|
||||
allMatches := make([][]Result, len(chunks))
|
||||
for idx, chunk := range chunks {
|
||||
matches := request.pattern.Match(chunk, slab)
|
||||
allMatches[idx] = matches
|
||||
count += len(matches)
|
||||
if cancelled.Get() {
|
||||
return
|
||||
}
|
||||
countChan <- len(matches)
|
||||
}
|
||||
sliceMatches := make([]Result, 0, count)
|
||||
for _, matches := range allMatches {
|
||||
sliceMatches = append(sliceMatches, matches...)
|
||||
}
|
||||
if m.sort {
|
||||
if m.tac {
|
||||
sort.Sort(ByRelevanceTac(sliceMatches))
|
||||
} else {
|
||||
sort.Sort(ByRelevance(sliceMatches))
|
||||
}
|
||||
}
|
||||
resultChan <- partialResult{idx, sliceMatches}
|
||||
}(idx, m.slab[idx], chunks)
|
||||
}
|
||||
|
||||
wait := func() bool {
|
||||
cancelled.Set(true)
|
||||
waitGroup.Wait()
|
||||
return true
|
||||
}
|
||||
|
||||
count := 0
|
||||
matchCount := 0
|
||||
for matchesInChunk := range countChan {
|
||||
count++
|
||||
matchCount += matchesInChunk
|
||||
|
||||
if count == numChunks {
|
||||
break
|
||||
}
|
||||
|
||||
if m.reqBox.Peek(reqReset) {
|
||||
return nil, wait()
|
||||
}
|
||||
|
||||
if time.Since(startedAt) > progressMinDuration {
|
||||
m.eventBox.Set(EvtSearchProgress, float32(count)/float32(numChunks))
|
||||
}
|
||||
}
|
||||
|
||||
partialResults := make([][]Result, numSlices)
|
||||
for range slices {
|
||||
partialResult := <-resultChan
|
||||
partialResults[partialResult.index] = partialResult.matches
|
||||
}
|
||||
return NewMerger(pattern, partialResults, m.sort, m.tac), false
|
||||
}
|
||||
|
||||
// Reset is called to interrupt/signal the ongoing search
|
||||
func (m *Matcher) Reset(chunks []*Chunk, patternRunes []rune, cancel bool, final bool, sort bool, clearCache bool) {
|
||||
pattern := m.patternBuilder(patternRunes)
|
||||
|
||||
var event util.EventType
|
||||
if cancel {
|
||||
event = reqReset
|
||||
} else {
|
||||
event = reqRetry
|
||||
}
|
||||
m.reqBox.Set(event, MatchRequest{chunks, pattern, final, sort && pattern.sortable, clearCache})
|
||||
}
|
||||
@ -1,120 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import "fmt"
|
||||
|
||||
// EmptyMerger is a Merger with no data
|
||||
var EmptyMerger = NewMerger(nil, [][]Result{}, false, false)
|
||||
|
||||
// Merger holds a set of locally sorted lists of items and provides the view of
|
||||
// a single, globally-sorted list
|
||||
type Merger struct {
|
||||
pattern *Pattern
|
||||
lists [][]Result
|
||||
merged []Result
|
||||
chunks *[]*Chunk
|
||||
cursors []int
|
||||
sorted bool
|
||||
tac bool
|
||||
final bool
|
||||
count int
|
||||
}
|
||||
|
||||
// PassMerger returns a new Merger that simply returns the items in the
|
||||
// original order
|
||||
func PassMerger(chunks *[]*Chunk, tac bool) *Merger {
|
||||
mg := Merger{
|
||||
pattern: nil,
|
||||
chunks: chunks,
|
||||
tac: tac,
|
||||
count: 0}
|
||||
|
||||
for _, chunk := range *mg.chunks {
|
||||
mg.count += chunk.count
|
||||
}
|
||||
return &mg
|
||||
}
|
||||
|
||||
// NewMerger returns a new Merger
|
||||
func NewMerger(pattern *Pattern, lists [][]Result, sorted bool, tac bool) *Merger {
|
||||
mg := Merger{
|
||||
pattern: pattern,
|
||||
lists: lists,
|
||||
merged: []Result{},
|
||||
chunks: nil,
|
||||
cursors: make([]int, len(lists)),
|
||||
sorted: sorted,
|
||||
tac: tac,
|
||||
final: false,
|
||||
count: 0}
|
||||
|
||||
for _, list := range mg.lists {
|
||||
mg.count += len(list)
|
||||
}
|
||||
return &mg
|
||||
}
|
||||
|
||||
// Length returns the number of items
|
||||
func (mg *Merger) Length() int {
|
||||
return mg.count
|
||||
}
|
||||
|
||||
// Get returns the pointer to the Result object indexed by the given integer
|
||||
func (mg *Merger) Get(idx int) Result {
|
||||
if mg.chunks != nil {
|
||||
if mg.tac {
|
||||
idx = mg.count - idx - 1
|
||||
}
|
||||
chunk := (*mg.chunks)[idx/chunkSize]
|
||||
return Result{item: &chunk.items[idx%chunkSize]}
|
||||
}
|
||||
|
||||
if mg.sorted {
|
||||
return mg.mergedGet(idx)
|
||||
}
|
||||
|
||||
if mg.tac {
|
||||
idx = mg.count - idx - 1
|
||||
}
|
||||
for _, list := range mg.lists {
|
||||
numItems := len(list)
|
||||
if idx < numItems {
|
||||
return list[idx]
|
||||
}
|
||||
idx -= numItems
|
||||
}
|
||||
panic(fmt.Sprintf("Index out of bounds (unsorted, %d/%d)", idx, mg.count))
|
||||
}
|
||||
|
||||
func (mg *Merger) cacheable() bool {
|
||||
return mg.count < mergerCacheMax
|
||||
}
|
||||
|
||||
func (mg *Merger) mergedGet(idx int) Result {
|
||||
for i := len(mg.merged); i <= idx; i++ {
|
||||
minRank := minRank()
|
||||
minIdx := -1
|
||||
for listIdx, list := range mg.lists {
|
||||
cursor := mg.cursors[listIdx]
|
||||
if cursor < 0 || cursor == len(list) {
|
||||
mg.cursors[listIdx] = -1
|
||||
continue
|
||||
}
|
||||
if cursor >= 0 {
|
||||
rank := list[cursor]
|
||||
if minIdx < 0 || compareRanks(rank, minRank, mg.tac) {
|
||||
minRank = rank
|
||||
minIdx = listIdx
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if minIdx >= 0 {
|
||||
chosen := mg.lists[minIdx]
|
||||
mg.merged = append(mg.merged, chosen[mg.cursors[minIdx]])
|
||||
mg.cursors[minIdx]++
|
||||
} else {
|
||||
panic(fmt.Sprintf("Index out of bounds (sorted, %d/%d)", i, mg.count))
|
||||
}
|
||||
}
|
||||
return mg.merged[idx]
|
||||
}
|
||||
@ -1,88 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"math/rand"
|
||||
"sort"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func assert(t *testing.T, cond bool, msg ...string) {
|
||||
if !cond {
|
||||
t.Error(msg)
|
||||
}
|
||||
}
|
||||
|
||||
func randResult() Result {
|
||||
str := fmt.Sprintf("%d", rand.Uint32())
|
||||
chars := util.ToChars([]byte(str))
|
||||
chars.Index = rand.Int31()
|
||||
return Result{item: &Item{text: chars}}
|
||||
}
|
||||
|
||||
func TestEmptyMerger(t *testing.T) {
|
||||
assert(t, EmptyMerger.Length() == 0, "Not empty")
|
||||
assert(t, EmptyMerger.count == 0, "Invalid count")
|
||||
assert(t, len(EmptyMerger.lists) == 0, "Invalid lists")
|
||||
assert(t, len(EmptyMerger.merged) == 0, "Invalid merged list")
|
||||
}
|
||||
|
||||
func buildLists(partiallySorted bool) ([][]Result, []Result) {
|
||||
numLists := 4
|
||||
lists := make([][]Result, numLists)
|
||||
cnt := 0
|
||||
for i := 0; i < numLists; i++ {
|
||||
numResults := rand.Int() % 20
|
||||
cnt += numResults
|
||||
lists[i] = make([]Result, numResults)
|
||||
for j := 0; j < numResults; j++ {
|
||||
item := randResult()
|
||||
lists[i][j] = item
|
||||
}
|
||||
if partiallySorted {
|
||||
sort.Sort(ByRelevance(lists[i]))
|
||||
}
|
||||
}
|
||||
items := []Result{}
|
||||
for _, list := range lists {
|
||||
items = append(items, list...)
|
||||
}
|
||||
return lists, items
|
||||
}
|
||||
|
||||
func TestMergerUnsorted(t *testing.T) {
|
||||
lists, items := buildLists(false)
|
||||
cnt := len(items)
|
||||
|
||||
// Not sorted: same order
|
||||
mg := NewMerger(nil, lists, false, false)
|
||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||
for i := 0; i < cnt; i++ {
|
||||
assert(t, items[i] == mg.Get(i), "Invalid Get")
|
||||
}
|
||||
}
|
||||
|
||||
func TestMergerSorted(t *testing.T) {
|
||||
lists, items := buildLists(true)
|
||||
cnt := len(items)
|
||||
|
||||
// Sorted sorted order
|
||||
mg := NewMerger(nil, lists, true, false)
|
||||
assert(t, cnt == mg.Length(), "Invalid Length")
|
||||
sort.Sort(ByRelevance(items))
|
||||
for i := 0; i < cnt; i++ {
|
||||
if items[i] != mg.Get(i) {
|
||||
t.Error("Not sorted", items[i], mg.Get(i))
|
||||
}
|
||||
}
|
||||
|
||||
// Inverse order
|
||||
mg2 := NewMerger(nil, lists, true, false)
|
||||
for i := cnt - 1; i >= 0; i-- {
|
||||
if items[i] != mg2.Get(i) {
|
||||
t.Error("Not sorted", items[i], mg2.Get(i))
|
||||
}
|
||||
}
|
||||
}
|
||||
1691
.fzf/src/options.go
1691
.fzf/src/options.go
File diff suppressed because it is too large
Load Diff
@ -1,457 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
)
|
||||
|
||||
func TestDelimiterRegex(t *testing.T) {
|
||||
// Valid regex
|
||||
delim := delimiterRegexp(".")
|
||||
if delim.regex == nil || delim.str != nil {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Broken regex -> string
|
||||
delim = delimiterRegexp("[0-9")
|
||||
if delim.regex != nil || *delim.str != "[0-9" {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Valid regex
|
||||
delim = delimiterRegexp("[0-9]")
|
||||
if delim.regex.String() != "[0-9]" || delim.str != nil {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Tab character
|
||||
delim = delimiterRegexp("\t")
|
||||
if delim.regex != nil || *delim.str != "\t" {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Tab expression
|
||||
delim = delimiterRegexp("\\t")
|
||||
if delim.regex != nil || *delim.str != "\t" {
|
||||
t.Error(delim)
|
||||
}
|
||||
// Tabs -> regex
|
||||
delim = delimiterRegexp("\t+")
|
||||
if delim.regex == nil || delim.str != nil {
|
||||
t.Error(delim)
|
||||
}
|
||||
}
|
||||
|
||||
func TestDelimiterRegexString(t *testing.T) {
|
||||
delim := delimiterRegexp("*")
|
||||
tokens := Tokenize("-*--*---**---", delim)
|
||||
if delim.regex != nil ||
|
||||
tokens[0].text.ToString() != "-*" ||
|
||||
tokens[1].text.ToString() != "--*" ||
|
||||
tokens[2].text.ToString() != "---*" ||
|
||||
tokens[3].text.ToString() != "*" ||
|
||||
tokens[4].text.ToString() != "---" {
|
||||
t.Errorf("%s %v %d", delim, tokens, len(tokens))
|
||||
}
|
||||
}
|
||||
|
||||
func TestDelimiterRegexRegex(t *testing.T) {
|
||||
delim := delimiterRegexp("--\\*")
|
||||
tokens := Tokenize("-*--*---**---", delim)
|
||||
if delim.str != nil ||
|
||||
tokens[0].text.ToString() != "-*--*" ||
|
||||
tokens[1].text.ToString() != "---*" ||
|
||||
tokens[2].text.ToString() != "*---" {
|
||||
t.Errorf("%s %d", tokens, len(tokens))
|
||||
}
|
||||
}
|
||||
|
||||
func TestSplitNth(t *testing.T) {
|
||||
{
|
||||
ranges := splitNth("..")
|
||||
if len(ranges) != 1 ||
|
||||
ranges[0].begin != rangeEllipsis ||
|
||||
ranges[0].end != rangeEllipsis {
|
||||
t.Errorf("%v", ranges)
|
||||
}
|
||||
}
|
||||
{
|
||||
ranges := splitNth("..3,1..,2..3,4..-1,-3..-2,..,2,-2,2..-2,1..-1")
|
||||
if len(ranges) != 10 ||
|
||||
ranges[0].begin != rangeEllipsis || ranges[0].end != 3 ||
|
||||
ranges[1].begin != rangeEllipsis || ranges[1].end != rangeEllipsis ||
|
||||
ranges[2].begin != 2 || ranges[2].end != 3 ||
|
||||
ranges[3].begin != 4 || ranges[3].end != rangeEllipsis ||
|
||||
ranges[4].begin != -3 || ranges[4].end != -2 ||
|
||||
ranges[5].begin != rangeEllipsis || ranges[5].end != rangeEllipsis ||
|
||||
ranges[6].begin != 2 || ranges[6].end != 2 ||
|
||||
ranges[7].begin != -2 || ranges[7].end != -2 ||
|
||||
ranges[8].begin != 2 || ranges[8].end != -2 ||
|
||||
ranges[9].begin != rangeEllipsis || ranges[9].end != rangeEllipsis {
|
||||
t.Errorf("%v", ranges)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestIrrelevantNth(t *testing.T) {
|
||||
{
|
||||
opts := defaultOptions()
|
||||
words := []string{"--nth", "..", "-x"}
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 0 {
|
||||
t.Errorf("nth should be empty: %v", opts.Nth)
|
||||
}
|
||||
}
|
||||
for _, words := range [][]string{{"--nth", "..,3", "+x"}, {"--nth", "3,1..", "+x"}, {"--nth", "..-1,1", "+x"}} {
|
||||
{
|
||||
opts := defaultOptions()
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 0 {
|
||||
t.Errorf("nth should be empty: %v", opts.Nth)
|
||||
}
|
||||
}
|
||||
{
|
||||
opts := defaultOptions()
|
||||
words = append(words, "-x")
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if len(opts.Nth) != 2 {
|
||||
t.Errorf("nth should not be empty: %v", opts.Nth)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestParseKeys(t *testing.T) {
|
||||
pairs := parseKeyChords("ctrl-z,alt-z,f2,@,Alt-a,!,ctrl-G,J,g,ctrl-alt-a,ALT-enter,alt-SPACE", "")
|
||||
checkEvent := func(e tui.Event, s string) {
|
||||
if pairs[e] != s {
|
||||
t.Errorf("%s != %s", pairs[e], s)
|
||||
}
|
||||
}
|
||||
check := func(et tui.EventType, s string) {
|
||||
checkEvent(et.AsEvent(), s)
|
||||
}
|
||||
if len(pairs) != 12 {
|
||||
t.Error(12)
|
||||
}
|
||||
check(tui.CtrlZ, "ctrl-z")
|
||||
check(tui.F2, "f2")
|
||||
check(tui.CtrlG, "ctrl-G")
|
||||
checkEvent(tui.AltKey('z'), "alt-z")
|
||||
checkEvent(tui.Key('@'), "@")
|
||||
checkEvent(tui.AltKey('a'), "Alt-a")
|
||||
checkEvent(tui.Key('!'), "!")
|
||||
checkEvent(tui.Key('J'), "J")
|
||||
checkEvent(tui.Key('g'), "g")
|
||||
checkEvent(tui.CtrlAltKey('a'), "ctrl-alt-a")
|
||||
checkEvent(tui.CtrlAltKey('m'), "ALT-enter")
|
||||
checkEvent(tui.AltKey(' '), "alt-SPACE")
|
||||
|
||||
// Synonyms
|
||||
pairs = parseKeyChords("enter,Return,space,tab,btab,esc,up,down,left,right", "")
|
||||
if len(pairs) != 9 {
|
||||
t.Error(9)
|
||||
}
|
||||
check(tui.CtrlM, "Return")
|
||||
checkEvent(tui.Key(' '), "space")
|
||||
check(tui.Tab, "tab")
|
||||
check(tui.BTab, "btab")
|
||||
check(tui.ESC, "esc")
|
||||
check(tui.Up, "up")
|
||||
check(tui.Down, "down")
|
||||
check(tui.Left, "left")
|
||||
check(tui.Right, "right")
|
||||
|
||||
pairs = parseKeyChords("Tab,Ctrl-I,PgUp,page-up,pgdn,Page-Down,Home,End,Alt-BS,Alt-BSpace,shift-left,shift-right,btab,shift-tab,return,Enter,bspace", "")
|
||||
if len(pairs) != 11 {
|
||||
t.Error(11)
|
||||
}
|
||||
check(tui.Tab, "Ctrl-I")
|
||||
check(tui.PgUp, "page-up")
|
||||
check(tui.PgDn, "Page-Down")
|
||||
check(tui.Home, "Home")
|
||||
check(tui.End, "End")
|
||||
check(tui.AltBS, "Alt-BSpace")
|
||||
check(tui.SLeft, "shift-left")
|
||||
check(tui.SRight, "shift-right")
|
||||
check(tui.BTab, "shift-tab")
|
||||
check(tui.CtrlM, "Enter")
|
||||
check(tui.BSpace, "bspace")
|
||||
}
|
||||
|
||||
func TestParseKeysWithComma(t *testing.T) {
|
||||
checkN := func(a int, b int) {
|
||||
if a != b {
|
||||
t.Errorf("%d != %d", a, b)
|
||||
}
|
||||
}
|
||||
check := func(pairs map[tui.Event]string, e tui.Event, s string) {
|
||||
if pairs[e] != s {
|
||||
t.Errorf("%s != %s", pairs[e], s)
|
||||
}
|
||||
}
|
||||
|
||||
pairs := parseKeyChords(",", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords(",,a,b", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords("a,b,,", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords("a,,,b", "")
|
||||
checkN(len(pairs), 3)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords("a,,,b,c", "")
|
||||
checkN(len(pairs), 4)
|
||||
check(pairs, tui.Key('a'), "a")
|
||||
check(pairs, tui.Key('b'), "b")
|
||||
check(pairs, tui.Key('c'), "c")
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords(",,,", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.Key(','), ",")
|
||||
|
||||
pairs = parseKeyChords(",ALT-,,", "")
|
||||
checkN(len(pairs), 1)
|
||||
check(pairs, tui.AltKey(','), "ALT-,")
|
||||
}
|
||||
|
||||
func TestBind(t *testing.T) {
|
||||
keymap := defaultKeymap()
|
||||
check := func(event tui.Event, arg1 string, types ...actionType) {
|
||||
if len(keymap[event]) != len(types) {
|
||||
t.Errorf("invalid number of actions for %v (%d != %d)",
|
||||
event, len(types), len(keymap[event]))
|
||||
return
|
||||
}
|
||||
for idx, action := range keymap[event] {
|
||||
if types[idx] != action.t {
|
||||
t.Errorf("invalid action type (%d != %d)", types[idx], action.t)
|
||||
}
|
||||
}
|
||||
if len(arg1) > 0 && keymap[event][0].a != arg1 {
|
||||
t.Errorf("invalid action argument: (%s != %s)", arg1, keymap[event][0].a)
|
||||
}
|
||||
}
|
||||
check(tui.CtrlA.AsEvent(), "", actBeginningOfLine)
|
||||
parseKeymap(keymap,
|
||||
"ctrl-a:kill-line,ctrl-b:toggle-sort+up+down,c:page-up,alt-z:page-down,"+
|
||||
"f1:execute(ls {+})+abort+execute(echo {+})+select-all,f2:execute/echo {}, {}, {}/,f3:execute[echo '({})'],f4:execute;less {};,"+
|
||||
"alt-a:execute-Multi@echo (,),[,],/,:,;,%,{}@,alt-b:execute;echo (,),[,],/,:,@,%,{};,"+
|
||||
"x:Execute(foo+bar),X:execute/bar+baz/"+
|
||||
",f1:+first,f1:+top"+
|
||||
",,:abort,::accept,+:execute:++\nfoobar,Y:execute(baz)+up")
|
||||
check(tui.CtrlA.AsEvent(), "", actKillLine)
|
||||
check(tui.CtrlB.AsEvent(), "", actToggleSort, actUp, actDown)
|
||||
check(tui.Key('c'), "", actPageUp)
|
||||
check(tui.Key(','), "", actAbort)
|
||||
check(tui.Key(':'), "", actAccept)
|
||||
check(tui.AltKey('z'), "", actPageDown)
|
||||
check(tui.F1.AsEvent(), "ls {+}", actExecute, actAbort, actExecute, actSelectAll, actFirst, actFirst)
|
||||
check(tui.F2.AsEvent(), "echo {}, {}, {}", actExecute)
|
||||
check(tui.F3.AsEvent(), "echo '({})'", actExecute)
|
||||
check(tui.F4.AsEvent(), "less {}", actExecute)
|
||||
check(tui.Key('x'), "foo+bar", actExecute)
|
||||
check(tui.Key('X'), "bar+baz", actExecute)
|
||||
check(tui.AltKey('a'), "echo (,),[,],/,:,;,%,{}", actExecuteMulti)
|
||||
check(tui.AltKey('b'), "echo (,),[,],/,:,@,%,{}", actExecute)
|
||||
check(tui.Key('+'), "++\nfoobar,Y:execute(baz)+up", actExecute)
|
||||
|
||||
for idx, char := range []rune{'~', '!', '@', '#', '$', '%', '^', '&', '*', '|', ';', '/'} {
|
||||
parseKeymap(keymap, fmt.Sprintf("%d:execute%cfoobar%c", idx%10, char, char))
|
||||
check(tui.Key([]rune(fmt.Sprintf("%d", idx%10))[0]), "foobar", actExecute)
|
||||
}
|
||||
|
||||
parseKeymap(keymap, "f1:abort")
|
||||
check(tui.F1.AsEvent(), "", actAbort)
|
||||
}
|
||||
|
||||
func TestColorSpec(t *testing.T) {
|
||||
theme := tui.Dark256
|
||||
dark := parseTheme(theme, "dark")
|
||||
if *dark != *theme {
|
||||
t.Errorf("colors should be equivalent")
|
||||
}
|
||||
if dark == theme {
|
||||
t.Errorf("point should not be equivalent")
|
||||
}
|
||||
|
||||
light := parseTheme(theme, "dark,light")
|
||||
if *light == *theme {
|
||||
t.Errorf("should not be equivalent")
|
||||
}
|
||||
if *light != *tui.Light256 {
|
||||
t.Errorf("colors should be equivalent")
|
||||
}
|
||||
if light == theme {
|
||||
t.Errorf("point should not be equivalent")
|
||||
}
|
||||
|
||||
customized := parseTheme(theme, "fg:231,bg:232")
|
||||
if customized.Fg.Color != 231 || customized.Bg.Color != 232 {
|
||||
t.Errorf("color not customized")
|
||||
}
|
||||
if *tui.Dark256 == *customized {
|
||||
t.Errorf("colors should not be equivalent")
|
||||
}
|
||||
customized.Fg = tui.Dark256.Fg
|
||||
customized.Bg = tui.Dark256.Bg
|
||||
if *tui.Dark256 != *customized {
|
||||
t.Errorf("colors should now be equivalent: %v, %v", tui.Dark256, customized)
|
||||
}
|
||||
|
||||
customized = parseTheme(theme, "fg:231,dark,bg:232")
|
||||
if customized.Fg != tui.Dark256.Fg || customized.Bg == tui.Dark256.Bg {
|
||||
t.Errorf("color not customized")
|
||||
}
|
||||
}
|
||||
|
||||
func TestDefaultCtrlNP(t *testing.T) {
|
||||
check := func(words []string, et tui.EventType, expected actionType) {
|
||||
e := et.AsEvent()
|
||||
opts := defaultOptions()
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
if opts.Keymap[e][0].t != expected {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
check([]string{}, tui.CtrlN, actDown)
|
||||
check([]string{}, tui.CtrlP, actUp)
|
||||
|
||||
check([]string{"--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
||||
check([]string{"--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
||||
|
||||
f, _ := ioutil.TempFile("", "fzf-history")
|
||||
f.Close()
|
||||
hist := "--history=" + f.Name()
|
||||
check([]string{hist}, tui.CtrlN, actNextHistory)
|
||||
check([]string{hist}, tui.CtrlP, actPreviousHistory)
|
||||
|
||||
check([]string{hist, "--bind=ctrl-n:accept"}, tui.CtrlN, actAccept)
|
||||
check([]string{hist, "--bind=ctrl-n:accept"}, tui.CtrlP, actPreviousHistory)
|
||||
|
||||
check([]string{hist, "--bind=ctrl-p:accept"}, tui.CtrlN, actNextHistory)
|
||||
check([]string{hist, "--bind=ctrl-p:accept"}, tui.CtrlP, actAccept)
|
||||
}
|
||||
|
||||
func optsFor(words ...string) *Options {
|
||||
opts := defaultOptions()
|
||||
parseOptions(opts, words)
|
||||
postProcessOptions(opts)
|
||||
return opts
|
||||
}
|
||||
|
||||
func TestToggle(t *testing.T) {
|
||||
opts := optsFor()
|
||||
if opts.ToggleSort {
|
||||
t.Error()
|
||||
}
|
||||
|
||||
opts = optsFor("--bind=a:toggle-sort")
|
||||
if !opts.ToggleSort {
|
||||
t.Error()
|
||||
}
|
||||
|
||||
opts = optsFor("--bind=a:toggle-sort", "--bind=a:up")
|
||||
if opts.ToggleSort {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
|
||||
func TestPreviewOpts(t *testing.T) {
|
||||
opts := optsFor()
|
||||
if !(opts.Preview.command == "" &&
|
||||
opts.Preview.hidden == false &&
|
||||
opts.Preview.wrap == false &&
|
||||
opts.Preview.position == posRight &&
|
||||
opts.Preview.size.percent == true &&
|
||||
opts.Preview.size.size == 50) {
|
||||
t.Error()
|
||||
}
|
||||
opts = optsFor("--preview", "cat {}", "--preview-window=left:15,hidden,wrap:+{1}-/2")
|
||||
if !(opts.Preview.command == "cat {}" &&
|
||||
opts.Preview.hidden == true &&
|
||||
opts.Preview.wrap == true &&
|
||||
opts.Preview.position == posLeft &&
|
||||
opts.Preview.scroll == "+{1}-/2" &&
|
||||
opts.Preview.size.percent == false &&
|
||||
opts.Preview.size.size == 15) {
|
||||
t.Error(opts.Preview)
|
||||
}
|
||||
opts = optsFor("--preview-window=up,15,wrap,hidden,+{1}+3-1-2/2", "--preview-window=down", "--preview-window=cycle")
|
||||
if !(opts.Preview.command == "" &&
|
||||
opts.Preview.hidden == true &&
|
||||
opts.Preview.wrap == true &&
|
||||
opts.Preview.cycle == true &&
|
||||
opts.Preview.position == posDown &&
|
||||
opts.Preview.scroll == "+{1}+3-1-2/2" &&
|
||||
opts.Preview.size.percent == false &&
|
||||
opts.Preview.size.size == 15) {
|
||||
t.Error(opts.Preview.size.size)
|
||||
}
|
||||
opts = optsFor("--preview-window=up:15:wrap:hidden")
|
||||
if !(opts.Preview.command == "" &&
|
||||
opts.Preview.hidden == true &&
|
||||
opts.Preview.wrap == true &&
|
||||
opts.Preview.position == posUp &&
|
||||
opts.Preview.size.percent == false &&
|
||||
opts.Preview.size.size == 15) {
|
||||
t.Error(opts.Preview)
|
||||
}
|
||||
opts = optsFor("--preview=foo", "--preview-window=up", "--preview-window=default:70%")
|
||||
if !(opts.Preview.command == "foo" &&
|
||||
opts.Preview.position == posRight &&
|
||||
opts.Preview.size.percent == true &&
|
||||
opts.Preview.size.size == 70) {
|
||||
t.Error(opts.Preview)
|
||||
}
|
||||
}
|
||||
|
||||
func TestAdditiveExpect(t *testing.T) {
|
||||
opts := optsFor("--expect=a", "--expect", "b", "--expect=c")
|
||||
if len(opts.Expect) != 3 {
|
||||
t.Error(opts.Expect)
|
||||
}
|
||||
}
|
||||
|
||||
func TestValidateSign(t *testing.T) {
|
||||
testCases := []struct {
|
||||
inputSign string
|
||||
isValid bool
|
||||
}{
|
||||
{"> ", true},
|
||||
{"아", true},
|
||||
{"😀", true},
|
||||
{"", false},
|
||||
{">>>", false},
|
||||
{"\n", false},
|
||||
{"\t", false},
|
||||
}
|
||||
|
||||
for _, testCase := range testCases {
|
||||
err := validateSign(testCase.inputSign, "")
|
||||
if testCase.isValid && err != nil {
|
||||
t.Errorf("Input sign `%s` caused error", testCase.inputSign)
|
||||
}
|
||||
|
||||
if !testCase.isValid && err == nil {
|
||||
t.Errorf("Input sign `%s` did not cause error", testCase.inputSign)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1,425 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"regexp"
|
||||
"strings"
|
||||
|
||||
"github.com/junegunn/fzf/src/algo"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
// fuzzy
|
||||
// 'exact
|
||||
// ^prefix-exact
|
||||
// suffix-exact$
|
||||
// !inverse-exact
|
||||
// !'inverse-fuzzy
|
||||
// !^inverse-prefix-exact
|
||||
// !inverse-suffix-exact$
|
||||
|
||||
type termType int
|
||||
|
||||
const (
|
||||
termFuzzy termType = iota
|
||||
termExact
|
||||
termPrefix
|
||||
termSuffix
|
||||
termEqual
|
||||
)
|
||||
|
||||
type term struct {
|
||||
typ termType
|
||||
inv bool
|
||||
text []rune
|
||||
caseSensitive bool
|
||||
normalize bool
|
||||
}
|
||||
|
||||
// String returns the string representation of a term.
|
||||
func (t term) String() string {
|
||||
return fmt.Sprintf("term{typ: %d, inv: %v, text: []rune(%q), caseSensitive: %v}", t.typ, t.inv, string(t.text), t.caseSensitive)
|
||||
}
|
||||
|
||||
type termSet []term
|
||||
|
||||
// Pattern represents search pattern
|
||||
type Pattern struct {
|
||||
fuzzy bool
|
||||
fuzzyAlgo algo.Algo
|
||||
extended bool
|
||||
caseSensitive bool
|
||||
normalize bool
|
||||
forward bool
|
||||
text []rune
|
||||
termSets []termSet
|
||||
sortable bool
|
||||
cacheable bool
|
||||
cacheKey string
|
||||
delimiter Delimiter
|
||||
nth []Range
|
||||
procFun map[termType]algo.Algo
|
||||
}
|
||||
|
||||
var (
|
||||
_patternCache map[string]*Pattern
|
||||
_splitRegex *regexp.Regexp
|
||||
_cache ChunkCache
|
||||
)
|
||||
|
||||
func init() {
|
||||
_splitRegex = regexp.MustCompile(" +")
|
||||
clearPatternCache()
|
||||
clearChunkCache()
|
||||
}
|
||||
|
||||
func clearPatternCache() {
|
||||
// We can uniquely identify the pattern for a given string since
|
||||
// search mode and caseMode do not change while the program is running
|
||||
_patternCache = make(map[string]*Pattern)
|
||||
}
|
||||
|
||||
func clearChunkCache() {
|
||||
_cache = NewChunkCache()
|
||||
}
|
||||
|
||||
// BuildPattern builds Pattern object from the given arguments
|
||||
func BuildPattern(fuzzy bool, fuzzyAlgo algo.Algo, extended bool, caseMode Case, normalize bool, forward bool,
|
||||
cacheable bool, nth []Range, delimiter Delimiter, runes []rune) *Pattern {
|
||||
|
||||
var asString string
|
||||
if extended {
|
||||
asString = strings.TrimLeft(string(runes), " ")
|
||||
for strings.HasSuffix(asString, " ") && !strings.HasSuffix(asString, "\\ ") {
|
||||
asString = asString[:len(asString)-1]
|
||||
}
|
||||
} else {
|
||||
asString = string(runes)
|
||||
}
|
||||
|
||||
cached, found := _patternCache[asString]
|
||||
if found {
|
||||
return cached
|
||||
}
|
||||
|
||||
caseSensitive := true
|
||||
sortable := true
|
||||
termSets := []termSet{}
|
||||
|
||||
if extended {
|
||||
termSets = parseTerms(fuzzy, caseMode, normalize, asString)
|
||||
// We should not sort the result if there are only inverse search terms
|
||||
sortable = false
|
||||
Loop:
|
||||
for _, termSet := range termSets {
|
||||
for idx, term := range termSet {
|
||||
if !term.inv {
|
||||
sortable = true
|
||||
}
|
||||
// If the query contains inverse search terms or OR operators,
|
||||
// we cannot cache the search scope
|
||||
if !cacheable || idx > 0 || term.inv || fuzzy && term.typ != termFuzzy || !fuzzy && term.typ != termExact {
|
||||
cacheable = false
|
||||
if sortable {
|
||||
// Can't break until we see at least one non-inverse term
|
||||
break Loop
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
} else {
|
||||
lowerString := strings.ToLower(asString)
|
||||
normalize = normalize &&
|
||||
lowerString == string(algo.NormalizeRunes([]rune(lowerString)))
|
||||
caseSensitive = caseMode == CaseRespect ||
|
||||
caseMode == CaseSmart && lowerString != asString
|
||||
if !caseSensitive {
|
||||
asString = lowerString
|
||||
}
|
||||
}
|
||||
|
||||
ptr := &Pattern{
|
||||
fuzzy: fuzzy,
|
||||
fuzzyAlgo: fuzzyAlgo,
|
||||
extended: extended,
|
||||
caseSensitive: caseSensitive,
|
||||
normalize: normalize,
|
||||
forward: forward,
|
||||
text: []rune(asString),
|
||||
termSets: termSets,
|
||||
sortable: sortable,
|
||||
cacheable: cacheable,
|
||||
nth: nth,
|
||||
delimiter: delimiter,
|
||||
procFun: make(map[termType]algo.Algo)}
|
||||
|
||||
ptr.cacheKey = ptr.buildCacheKey()
|
||||
ptr.procFun[termFuzzy] = fuzzyAlgo
|
||||
ptr.procFun[termEqual] = algo.EqualMatch
|
||||
ptr.procFun[termExact] = algo.ExactMatchNaive
|
||||
ptr.procFun[termPrefix] = algo.PrefixMatch
|
||||
ptr.procFun[termSuffix] = algo.SuffixMatch
|
||||
|
||||
_patternCache[asString] = ptr
|
||||
return ptr
|
||||
}
|
||||
|
||||
func parseTerms(fuzzy bool, caseMode Case, normalize bool, str string) []termSet {
|
||||
str = strings.Replace(str, "\\ ", "\t", -1)
|
||||
tokens := _splitRegex.Split(str, -1)
|
||||
sets := []termSet{}
|
||||
set := termSet{}
|
||||
switchSet := false
|
||||
afterBar := false
|
||||
for _, token := range tokens {
|
||||
typ, inv, text := termFuzzy, false, strings.Replace(token, "\t", " ", -1)
|
||||
lowerText := strings.ToLower(text)
|
||||
caseSensitive := caseMode == CaseRespect ||
|
||||
caseMode == CaseSmart && text != lowerText
|
||||
normalizeTerm := normalize &&
|
||||
lowerText == string(algo.NormalizeRunes([]rune(lowerText)))
|
||||
if !caseSensitive {
|
||||
text = lowerText
|
||||
}
|
||||
if !fuzzy {
|
||||
typ = termExact
|
||||
}
|
||||
|
||||
if len(set) > 0 && !afterBar && text == "|" {
|
||||
switchSet = false
|
||||
afterBar = true
|
||||
continue
|
||||
}
|
||||
afterBar = false
|
||||
|
||||
if strings.HasPrefix(text, "!") {
|
||||
inv = true
|
||||
typ = termExact
|
||||
text = text[1:]
|
||||
}
|
||||
|
||||
if text != "$" && strings.HasSuffix(text, "$") {
|
||||
typ = termSuffix
|
||||
text = text[:len(text)-1]
|
||||
}
|
||||
|
||||
if strings.HasPrefix(text, "'") {
|
||||
// Flip exactness
|
||||
if fuzzy && !inv {
|
||||
typ = termExact
|
||||
text = text[1:]
|
||||
} else {
|
||||
typ = termFuzzy
|
||||
text = text[1:]
|
||||
}
|
||||
} else if strings.HasPrefix(text, "^") {
|
||||
if typ == termSuffix {
|
||||
typ = termEqual
|
||||
} else {
|
||||
typ = termPrefix
|
||||
}
|
||||
text = text[1:]
|
||||
}
|
||||
|
||||
if len(text) > 0 {
|
||||
if switchSet {
|
||||
sets = append(sets, set)
|
||||
set = termSet{}
|
||||
}
|
||||
textRunes := []rune(text)
|
||||
if normalizeTerm {
|
||||
textRunes = algo.NormalizeRunes(textRunes)
|
||||
}
|
||||
set = append(set, term{
|
||||
typ: typ,
|
||||
inv: inv,
|
||||
text: textRunes,
|
||||
caseSensitive: caseSensitive,
|
||||
normalize: normalizeTerm})
|
||||
switchSet = true
|
||||
}
|
||||
}
|
||||
if len(set) > 0 {
|
||||
sets = append(sets, set)
|
||||
}
|
||||
return sets
|
||||
}
|
||||
|
||||
// IsEmpty returns true if the pattern is effectively empty
|
||||
func (p *Pattern) IsEmpty() bool {
|
||||
if !p.extended {
|
||||
return len(p.text) == 0
|
||||
}
|
||||
return len(p.termSets) == 0
|
||||
}
|
||||
|
||||
// AsString returns the search query in string type
|
||||
func (p *Pattern) AsString() string {
|
||||
return string(p.text)
|
||||
}
|
||||
|
||||
func (p *Pattern) buildCacheKey() string {
|
||||
if !p.extended {
|
||||
return p.AsString()
|
||||
}
|
||||
cacheableTerms := []string{}
|
||||
for _, termSet := range p.termSets {
|
||||
if len(termSet) == 1 && !termSet[0].inv && (p.fuzzy || termSet[0].typ == termExact) {
|
||||
cacheableTerms = append(cacheableTerms, string(termSet[0].text))
|
||||
}
|
||||
}
|
||||
return strings.Join(cacheableTerms, "\t")
|
||||
}
|
||||
|
||||
// CacheKey is used to build string to be used as the key of result cache
|
||||
func (p *Pattern) CacheKey() string {
|
||||
return p.cacheKey
|
||||
}
|
||||
|
||||
// Match returns the list of matches Items in the given Chunk
|
||||
func (p *Pattern) Match(chunk *Chunk, slab *util.Slab) []Result {
|
||||
// ChunkCache: Exact match
|
||||
cacheKey := p.CacheKey()
|
||||
if p.cacheable {
|
||||
if cached := _cache.Lookup(chunk, cacheKey); cached != nil {
|
||||
return cached
|
||||
}
|
||||
}
|
||||
|
||||
// Prefix/suffix cache
|
||||
space := _cache.Search(chunk, cacheKey)
|
||||
|
||||
matches := p.matchChunk(chunk, space, slab)
|
||||
|
||||
if p.cacheable {
|
||||
_cache.Add(chunk, cacheKey, matches)
|
||||
}
|
||||
return matches
|
||||
}
|
||||
|
||||
func (p *Pattern) matchChunk(chunk *Chunk, space []Result, slab *util.Slab) []Result {
|
||||
matches := []Result{}
|
||||
|
||||
if space == nil {
|
||||
for idx := 0; idx < chunk.count; idx++ {
|
||||
if match, _, _ := p.MatchItem(&chunk.items[idx], false, slab); match != nil {
|
||||
matches = append(matches, *match)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
for _, result := range space {
|
||||
if match, _, _ := p.MatchItem(result.item, false, slab); match != nil {
|
||||
matches = append(matches, *match)
|
||||
}
|
||||
}
|
||||
}
|
||||
return matches
|
||||
}
|
||||
|
||||
// MatchItem returns true if the Item is a match
|
||||
func (p *Pattern) MatchItem(item *Item, withPos bool, slab *util.Slab) (*Result, []Offset, *[]int) {
|
||||
if p.extended {
|
||||
if offsets, bonus, pos := p.extendedMatch(item, withPos, slab); len(offsets) == len(p.termSets) {
|
||||
result := buildResult(item, offsets, bonus)
|
||||
return &result, offsets, pos
|
||||
}
|
||||
return nil, nil, nil
|
||||
}
|
||||
offset, bonus, pos := p.basicMatch(item, withPos, slab)
|
||||
if sidx := offset[0]; sidx >= 0 {
|
||||
offsets := []Offset{offset}
|
||||
result := buildResult(item, offsets, bonus)
|
||||
return &result, offsets, pos
|
||||
}
|
||||
return nil, nil, nil
|
||||
}
|
||||
|
||||
func (p *Pattern) basicMatch(item *Item, withPos bool, slab *util.Slab) (Offset, int, *[]int) {
|
||||
var input []Token
|
||||
if len(p.nth) == 0 {
|
||||
input = []Token{{text: &item.text, prefixLength: 0}}
|
||||
} else {
|
||||
input = p.transformInput(item)
|
||||
}
|
||||
if p.fuzzy {
|
||||
return p.iter(p.fuzzyAlgo, input, p.caseSensitive, p.normalize, p.forward, p.text, withPos, slab)
|
||||
}
|
||||
return p.iter(algo.ExactMatchNaive, input, p.caseSensitive, p.normalize, p.forward, p.text, withPos, slab)
|
||||
}
|
||||
|
||||
func (p *Pattern) extendedMatch(item *Item, withPos bool, slab *util.Slab) ([]Offset, int, *[]int) {
|
||||
var input []Token
|
||||
if len(p.nth) == 0 {
|
||||
input = []Token{{text: &item.text, prefixLength: 0}}
|
||||
} else {
|
||||
input = p.transformInput(item)
|
||||
}
|
||||
offsets := []Offset{}
|
||||
var totalScore int
|
||||
var allPos *[]int
|
||||
if withPos {
|
||||
allPos = &[]int{}
|
||||
}
|
||||
for _, termSet := range p.termSets {
|
||||
var offset Offset
|
||||
var currentScore int
|
||||
matched := false
|
||||
for _, term := range termSet {
|
||||
pfun := p.procFun[term.typ]
|
||||
off, score, pos := p.iter(pfun, input, term.caseSensitive, term.normalize, p.forward, term.text, withPos, slab)
|
||||
if sidx := off[0]; sidx >= 0 {
|
||||
if term.inv {
|
||||
continue
|
||||
}
|
||||
offset, currentScore = off, score
|
||||
matched = true
|
||||
if withPos {
|
||||
if pos != nil {
|
||||
*allPos = append(*allPos, *pos...)
|
||||
} else {
|
||||
for idx := off[0]; idx < off[1]; idx++ {
|
||||
*allPos = append(*allPos, int(idx))
|
||||
}
|
||||
}
|
||||
}
|
||||
break
|
||||
} else if term.inv {
|
||||
offset, currentScore = Offset{0, 0}, 0
|
||||
matched = true
|
||||
continue
|
||||
}
|
||||
}
|
||||
if matched {
|
||||
offsets = append(offsets, offset)
|
||||
totalScore += currentScore
|
||||
}
|
||||
}
|
||||
return offsets, totalScore, allPos
|
||||
}
|
||||
|
||||
func (p *Pattern) transformInput(item *Item) []Token {
|
||||
if item.transformed != nil {
|
||||
return *item.transformed
|
||||
}
|
||||
|
||||
tokens := Tokenize(item.text.ToString(), p.delimiter)
|
||||
ret := Transform(tokens, p.nth)
|
||||
item.transformed = &ret
|
||||
return ret
|
||||
}
|
||||
|
||||
func (p *Pattern) iter(pfun algo.Algo, tokens []Token, caseSensitive bool, normalize bool, forward bool, pattern []rune, withPos bool, slab *util.Slab) (Offset, int, *[]int) {
|
||||
for _, part := range tokens {
|
||||
if res, pos := pfun(caseSensitive, normalize, forward, part.text, pattern, withPos, slab); res.Start >= 0 {
|
||||
sidx := int32(res.Start) + part.prefixLength
|
||||
eidx := int32(res.End) + part.prefixLength
|
||||
if pos != nil {
|
||||
for idx := range *pos {
|
||||
(*pos)[idx] += int(part.prefixLength)
|
||||
}
|
||||
}
|
||||
return Offset{sidx, eidx}, res.Score, pos
|
||||
}
|
||||
}
|
||||
return Offset{-1, -1}, 0, nil
|
||||
}
|
||||
@ -1,209 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"reflect"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/algo"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
var slab *util.Slab
|
||||
|
||||
func init() {
|
||||
slab = util.MakeSlab(slab16Size, slab32Size)
|
||||
}
|
||||
|
||||
func TestParseTermsExtended(t *testing.T) {
|
||||
terms := parseTerms(true, CaseSmart, false,
|
||||
"aaa 'bbb ^ccc ddd$ !eee !'fff !^ggg !hhh$ | ^iii$ ^xxx | 'yyy | zzz$ | !ZZZ |")
|
||||
if len(terms) != 9 ||
|
||||
terms[0][0].typ != termFuzzy || terms[0][0].inv ||
|
||||
terms[1][0].typ != termExact || terms[1][0].inv ||
|
||||
terms[2][0].typ != termPrefix || terms[2][0].inv ||
|
||||
terms[3][0].typ != termSuffix || terms[3][0].inv ||
|
||||
terms[4][0].typ != termExact || !terms[4][0].inv ||
|
||||
terms[5][0].typ != termFuzzy || !terms[5][0].inv ||
|
||||
terms[6][0].typ != termPrefix || !terms[6][0].inv ||
|
||||
terms[7][0].typ != termSuffix || !terms[7][0].inv ||
|
||||
terms[7][1].typ != termEqual || terms[7][1].inv ||
|
||||
terms[8][0].typ != termPrefix || terms[8][0].inv ||
|
||||
terms[8][1].typ != termExact || terms[8][1].inv ||
|
||||
terms[8][2].typ != termSuffix || terms[8][2].inv ||
|
||||
terms[8][3].typ != termExact || !terms[8][3].inv {
|
||||
t.Errorf("%v", terms)
|
||||
}
|
||||
for _, termSet := range terms[:8] {
|
||||
term := termSet[0]
|
||||
if len(term.text) != 3 {
|
||||
t.Errorf("%v", term)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestParseTermsExtendedExact(t *testing.T) {
|
||||
terms := parseTerms(false, CaseSmart, false,
|
||||
"aaa 'bbb ^ccc ddd$ !eee !'fff !^ggg !hhh$")
|
||||
if len(terms) != 8 ||
|
||||
terms[0][0].typ != termExact || terms[0][0].inv || len(terms[0][0].text) != 3 ||
|
||||
terms[1][0].typ != termFuzzy || terms[1][0].inv || len(terms[1][0].text) != 3 ||
|
||||
terms[2][0].typ != termPrefix || terms[2][0].inv || len(terms[2][0].text) != 3 ||
|
||||
terms[3][0].typ != termSuffix || terms[3][0].inv || len(terms[3][0].text) != 3 ||
|
||||
terms[4][0].typ != termExact || !terms[4][0].inv || len(terms[4][0].text) != 3 ||
|
||||
terms[5][0].typ != termFuzzy || !terms[5][0].inv || len(terms[5][0].text) != 3 ||
|
||||
terms[6][0].typ != termPrefix || !terms[6][0].inv || len(terms[6][0].text) != 3 ||
|
||||
terms[7][0].typ != termSuffix || !terms[7][0].inv || len(terms[7][0].text) != 3 {
|
||||
t.Errorf("%v", terms)
|
||||
}
|
||||
}
|
||||
|
||||
func TestParseTermsEmpty(t *testing.T) {
|
||||
terms := parseTerms(true, CaseSmart, false, "' ^ !' !^")
|
||||
if len(terms) != 0 {
|
||||
t.Errorf("%v", terms)
|
||||
}
|
||||
}
|
||||
|
||||
func TestExact(t *testing.T) {
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true,
|
||||
[]Range{}, Delimiter{}, []rune("'abc"))
|
||||
chars := util.ToChars([]byte("aabbcc abc"))
|
||||
res, pos := algo.ExactMatchNaive(
|
||||
pattern.caseSensitive, pattern.normalize, pattern.forward, &chars, pattern.termSets[0][0].text, true, nil)
|
||||
if res.Start != 7 || res.End != 10 {
|
||||
t.Errorf("%v / %d / %d", pattern.termSets, res.Start, res.End)
|
||||
}
|
||||
if pos != nil {
|
||||
t.Errorf("pos is expected to be nil")
|
||||
}
|
||||
}
|
||||
|
||||
func TestEqual(t *testing.T) {
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("^AbC$"))
|
||||
|
||||
match := func(str string, sidxExpected int, eidxExpected int) {
|
||||
chars := util.ToChars([]byte(str))
|
||||
res, pos := algo.EqualMatch(
|
||||
pattern.caseSensitive, pattern.normalize, pattern.forward, &chars, pattern.termSets[0][0].text, true, nil)
|
||||
if res.Start != sidxExpected || res.End != eidxExpected {
|
||||
t.Errorf("%v / %d / %d", pattern.termSets, res.Start, res.End)
|
||||
}
|
||||
if pos != nil {
|
||||
t.Errorf("pos is expected to be nil")
|
||||
}
|
||||
}
|
||||
match("ABC", -1, -1)
|
||||
match("AbC", 0, 3)
|
||||
match("AbC ", 0, 3)
|
||||
match(" AbC ", 1, 4)
|
||||
match(" AbC", 2, 5)
|
||||
}
|
||||
|
||||
func TestCaseSensitivity(t *testing.T) {
|
||||
defer clearPatternCache()
|
||||
clearPatternCache()
|
||||
pat1 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat2 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
clearPatternCache()
|
||||
pat3 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat4 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseIgnore, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
clearPatternCache()
|
||||
pat5 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, true, []Range{}, Delimiter{}, []rune("abc"))
|
||||
clearPatternCache()
|
||||
pat6 := BuildPattern(true, algo.FuzzyMatchV2, false, CaseRespect, false, true, true, []Range{}, Delimiter{}, []rune("Abc"))
|
||||
|
||||
if string(pat1.text) != "abc" || pat1.caseSensitive != false ||
|
||||
string(pat2.text) != "Abc" || pat2.caseSensitive != true ||
|
||||
string(pat3.text) != "abc" || pat3.caseSensitive != false ||
|
||||
string(pat4.text) != "abc" || pat4.caseSensitive != false ||
|
||||
string(pat5.text) != "abc" || pat5.caseSensitive != true ||
|
||||
string(pat6.text) != "Abc" || pat6.caseSensitive != true {
|
||||
t.Error("Invalid case conversion")
|
||||
}
|
||||
}
|
||||
|
||||
func TestOrigTextAndTransformed(t *testing.T) {
|
||||
pattern := BuildPattern(true, algo.FuzzyMatchV2, true, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune("jg"))
|
||||
tokens := Tokenize("junegunn", Delimiter{})
|
||||
trans := Transform(tokens, []Range{{1, 1}})
|
||||
|
||||
origBytes := []byte("junegunn.choi")
|
||||
for _, extended := range []bool{false, true} {
|
||||
chunk := Chunk{count: 1}
|
||||
chunk.items[0] = Item{
|
||||
text: util.ToChars([]byte("junegunn")),
|
||||
origText: &origBytes,
|
||||
transformed: &trans}
|
||||
pattern.extended = extended
|
||||
matches := pattern.matchChunk(&chunk, nil, slab) // No cache
|
||||
if !(matches[0].item.text.ToString() == "junegunn" &&
|
||||
string(*matches[0].item.origText) == "junegunn.choi" &&
|
||||
reflect.DeepEqual(*matches[0].item.transformed, trans)) {
|
||||
t.Error("Invalid match result", matches)
|
||||
}
|
||||
|
||||
match, offsets, pos := pattern.MatchItem(&chunk.items[0], true, slab)
|
||||
if !(match.item.text.ToString() == "junegunn" &&
|
||||
string(*match.item.origText) == "junegunn.choi" &&
|
||||
offsets[0][0] == 0 && offsets[0][1] == 5 &&
|
||||
reflect.DeepEqual(*match.item.transformed, trans)) {
|
||||
t.Error("Invalid match result", match, offsets, extended)
|
||||
}
|
||||
if !((*pos)[0] == 4 && (*pos)[1] == 0) {
|
||||
t.Error("Invalid pos array", *pos)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestCacheKey(t *testing.T) {
|
||||
test := func(extended bool, patStr string, expected string, cacheable bool) {
|
||||
clearPatternCache()
|
||||
pat := BuildPattern(true, algo.FuzzyMatchV2, extended, CaseSmart, false, true, true, []Range{}, Delimiter{}, []rune(patStr))
|
||||
if pat.CacheKey() != expected {
|
||||
t.Errorf("Expected: %s, actual: %s", expected, pat.CacheKey())
|
||||
}
|
||||
if pat.cacheable != cacheable {
|
||||
t.Errorf("Expected: %t, actual: %t (%s)", cacheable, pat.cacheable, patStr)
|
||||
}
|
||||
clearPatternCache()
|
||||
}
|
||||
test(false, "foo !bar", "foo !bar", true)
|
||||
test(false, "foo | bar !baz", "foo | bar !baz", true)
|
||||
test(true, "foo bar baz", "foo\tbar\tbaz", true)
|
||||
test(true, "foo !bar", "foo", false)
|
||||
test(true, "foo !bar baz", "foo\tbaz", false)
|
||||
test(true, "foo | bar baz", "baz", false)
|
||||
test(true, "foo | bar | baz", "", false)
|
||||
test(true, "foo | bar !baz", "", false)
|
||||
test(true, "| | foo", "", false)
|
||||
test(true, "| | | foo", "foo", false)
|
||||
}
|
||||
|
||||
func TestCacheable(t *testing.T) {
|
||||
test := func(fuzzy bool, str string, expected string, cacheable bool) {
|
||||
clearPatternCache()
|
||||
pat := BuildPattern(fuzzy, algo.FuzzyMatchV2, true, CaseSmart, true, true, true, []Range{}, Delimiter{}, []rune(str))
|
||||
if pat.CacheKey() != expected {
|
||||
t.Errorf("Expected: %s, actual: %s", expected, pat.CacheKey())
|
||||
}
|
||||
if cacheable != pat.cacheable {
|
||||
t.Errorf("Invalid Pattern.cacheable for \"%s\": %v (expected: %v)", str, pat.cacheable, cacheable)
|
||||
}
|
||||
clearPatternCache()
|
||||
}
|
||||
test(true, "foo bar", "foo\tbar", true)
|
||||
test(true, "foo 'bar", "foo\tbar", false)
|
||||
test(true, "foo !bar", "foo", false)
|
||||
|
||||
test(false, "foo bar", "foo\tbar", true)
|
||||
test(false, "foo 'bar", "foo", false)
|
||||
test(false, "foo '", "foo", true)
|
||||
test(false, "foo 'bar", "foo", false)
|
||||
test(false, "foo !bar", "foo", false)
|
||||
}
|
||||
@ -1,8 +0,0 @@
|
||||
// +build !openbsd
|
||||
|
||||
package protector
|
||||
|
||||
// Protect calls OS specific protections like pledge on OpenBSD
|
||||
func Protect() {
|
||||
return
|
||||
}
|
||||
@ -1,10 +0,0 @@
|
||||
// +build openbsd
|
||||
|
||||
package protector
|
||||
|
||||
import "golang.org/x/sys/unix"
|
||||
|
||||
// Protect calls OS specific protections like pledge on OpenBSD
|
||||
func Protect() {
|
||||
unix.PledgePromises("stdio rpath tty proc exec")
|
||||
}
|
||||
@ -1,201 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"context"
|
||||
"io"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
"github.com/saracen/walker"
|
||||
)
|
||||
|
||||
// Reader reads from command or standard input
|
||||
type Reader struct {
|
||||
pusher func([]byte) bool
|
||||
eventBox *util.EventBox
|
||||
delimNil bool
|
||||
event int32
|
||||
finChan chan bool
|
||||
mutex sync.Mutex
|
||||
exec *exec.Cmd
|
||||
command *string
|
||||
killed bool
|
||||
wait bool
|
||||
}
|
||||
|
||||
// NewReader returns new Reader object
|
||||
func NewReader(pusher func([]byte) bool, eventBox *util.EventBox, delimNil bool, wait bool) *Reader {
|
||||
return &Reader{pusher, eventBox, delimNil, int32(EvtReady), make(chan bool, 1), sync.Mutex{}, nil, nil, false, wait}
|
||||
}
|
||||
|
||||
func (r *Reader) startEventPoller() {
|
||||
go func() {
|
||||
ptr := &r.event
|
||||
pollInterval := readerPollIntervalMin
|
||||
for {
|
||||
if atomic.CompareAndSwapInt32(ptr, int32(EvtReadNew), int32(EvtReady)) {
|
||||
r.eventBox.Set(EvtReadNew, (*string)(nil))
|
||||
pollInterval = readerPollIntervalMin
|
||||
} else if atomic.LoadInt32(ptr) == int32(EvtReadFin) {
|
||||
if r.wait {
|
||||
r.finChan <- true
|
||||
}
|
||||
return
|
||||
} else {
|
||||
pollInterval += readerPollIntervalStep
|
||||
if pollInterval > readerPollIntervalMax {
|
||||
pollInterval = readerPollIntervalMax
|
||||
}
|
||||
}
|
||||
time.Sleep(pollInterval)
|
||||
}
|
||||
}()
|
||||
}
|
||||
|
||||
func (r *Reader) fin(success bool) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadFin))
|
||||
if r.wait {
|
||||
<-r.finChan
|
||||
}
|
||||
|
||||
r.mutex.Lock()
|
||||
ret := r.command
|
||||
if success || r.killed {
|
||||
ret = nil
|
||||
}
|
||||
r.mutex.Unlock()
|
||||
|
||||
r.eventBox.Set(EvtReadFin, ret)
|
||||
}
|
||||
|
||||
func (r *Reader) terminate() {
|
||||
r.mutex.Lock()
|
||||
defer func() { r.mutex.Unlock() }()
|
||||
|
||||
r.killed = true
|
||||
if r.exec != nil && r.exec.Process != nil {
|
||||
util.KillCommand(r.exec)
|
||||
} else if defaultCommand != "" {
|
||||
os.Stdin.Close()
|
||||
}
|
||||
}
|
||||
|
||||
func (r *Reader) restart(command string) {
|
||||
r.event = int32(EvtReady)
|
||||
r.startEventPoller()
|
||||
success := r.readFromCommand(nil, command)
|
||||
r.fin(success)
|
||||
}
|
||||
|
||||
// ReadSource reads data from the default command or from standard input
|
||||
func (r *Reader) ReadSource() {
|
||||
r.startEventPoller()
|
||||
var success bool
|
||||
if util.IsTty() {
|
||||
// The default command for *nix requires bash
|
||||
shell := "bash"
|
||||
cmd := os.Getenv("FZF_DEFAULT_COMMAND")
|
||||
if len(cmd) == 0 {
|
||||
if defaultCommand != "" {
|
||||
success = r.readFromCommand(&shell, defaultCommand)
|
||||
} else {
|
||||
success = r.readFiles()
|
||||
}
|
||||
} else {
|
||||
success = r.readFromCommand(nil, cmd)
|
||||
}
|
||||
} else {
|
||||
success = r.readFromStdin()
|
||||
}
|
||||
r.fin(success)
|
||||
}
|
||||
|
||||
func (r *Reader) feed(src io.Reader) {
|
||||
delim := byte('\n')
|
||||
if r.delimNil {
|
||||
delim = '\000'
|
||||
}
|
||||
reader := bufio.NewReaderSize(src, readerBufferSize)
|
||||
for {
|
||||
// ReadBytes returns err != nil if and only if the returned data does not
|
||||
// end in delim.
|
||||
bytea, err := reader.ReadBytes(delim)
|
||||
byteaLen := len(bytea)
|
||||
if byteaLen > 0 {
|
||||
if err == nil {
|
||||
// get rid of carriage return if under Windows:
|
||||
if util.IsWindows() && byteaLen >= 2 && bytea[byteaLen-2] == byte('\r') {
|
||||
bytea = bytea[:byteaLen-2]
|
||||
} else {
|
||||
bytea = bytea[:byteaLen-1]
|
||||
}
|
||||
}
|
||||
if r.pusher(bytea) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
if err != nil {
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (r *Reader) readFromStdin() bool {
|
||||
r.feed(os.Stdin)
|
||||
return true
|
||||
}
|
||||
|
||||
func (r *Reader) readFiles() bool {
|
||||
r.killed = false
|
||||
fn := func(path string, mode os.FileInfo) error {
|
||||
path = filepath.Clean(path)
|
||||
if path != "." {
|
||||
isDir := mode.Mode().IsDir()
|
||||
if isDir && filepath.Base(path)[0] == '.' {
|
||||
return filepath.SkipDir
|
||||
}
|
||||
if !isDir && r.pusher([]byte(path)) {
|
||||
atomic.StoreInt32(&r.event, int32(EvtReadNew))
|
||||
}
|
||||
}
|
||||
r.mutex.Lock()
|
||||
defer r.mutex.Unlock()
|
||||
if r.killed {
|
||||
return context.Canceled
|
||||
}
|
||||
return nil
|
||||
}
|
||||
cb := walker.WithErrorCallback(func(pathname string, err error) error {
|
||||
return nil
|
||||
})
|
||||
return walker.Walk(".", fn, cb) == nil
|
||||
}
|
||||
|
||||
func (r *Reader) readFromCommand(shell *string, command string) bool {
|
||||
r.mutex.Lock()
|
||||
r.killed = false
|
||||
r.command = &command
|
||||
if shell != nil {
|
||||
r.exec = util.ExecCommandWith(*shell, command, true)
|
||||
} else {
|
||||
r.exec = util.ExecCommand(command, true)
|
||||
}
|
||||
out, err := r.exec.StdoutPipe()
|
||||
if err != nil {
|
||||
r.mutex.Unlock()
|
||||
return false
|
||||
}
|
||||
err = r.exec.Start()
|
||||
r.mutex.Unlock()
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
r.feed(out)
|
||||
return r.exec.Wait() == nil
|
||||
}
|
||||
@ -1,63 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"testing"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func TestReadFromCommand(t *testing.T) {
|
||||
strs := []string{}
|
||||
eb := util.NewEventBox()
|
||||
reader := NewReader(
|
||||
func(s []byte) bool { strs = append(strs, string(s)); return true },
|
||||
eb, false, true)
|
||||
|
||||
reader.startEventPoller()
|
||||
|
||||
// Check EventBox
|
||||
if eb.Peek(EvtReadNew) {
|
||||
t.Error("EvtReadNew should not be set yet")
|
||||
}
|
||||
|
||||
// Normal command
|
||||
reader.fin(reader.readFromCommand(nil, `echo abc&&echo def`))
|
||||
if len(strs) != 2 || strs[0] != "abc" || strs[1] != "def" {
|
||||
t.Errorf("%s", strs)
|
||||
}
|
||||
|
||||
// Check EventBox again
|
||||
eb.WaitFor(EvtReadFin)
|
||||
|
||||
// Wait should return immediately
|
||||
eb.Wait(func(events *util.Events) {
|
||||
events.Clear()
|
||||
})
|
||||
|
||||
// EventBox is cleared
|
||||
if eb.Peek(EvtReadNew) {
|
||||
t.Error("EvtReadNew should not be set yet")
|
||||
}
|
||||
|
||||
// Make sure that event poller is finished
|
||||
time.Sleep(readerPollIntervalMax)
|
||||
|
||||
// Restart event poller
|
||||
reader.startEventPoller()
|
||||
|
||||
// Failing command
|
||||
reader.fin(reader.readFromCommand(nil, `no-such-command`))
|
||||
strs = []string{}
|
||||
if len(strs) > 0 {
|
||||
t.Errorf("%s", strs)
|
||||
}
|
||||
|
||||
// Check EventBox again
|
||||
if eb.Peek(EvtReadNew) {
|
||||
t.Error("Command failed. EvtReadNew should not be set")
|
||||
}
|
||||
if !eb.Peek(EvtReadFin) {
|
||||
t.Error("EvtReadFin should be set")
|
||||
}
|
||||
}
|
||||
@ -1,243 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"sort"
|
||||
"unicode"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
// Offset holds two 32-bit integers denoting the offsets of a matched substring
|
||||
type Offset [2]int32
|
||||
|
||||
type colorOffset struct {
|
||||
offset [2]int32
|
||||
color tui.ColorPair
|
||||
}
|
||||
|
||||
type Result struct {
|
||||
item *Item
|
||||
points [4]uint16
|
||||
}
|
||||
|
||||
func buildResult(item *Item, offsets []Offset, score int) Result {
|
||||
if len(offsets) > 1 {
|
||||
sort.Sort(ByOrder(offsets))
|
||||
}
|
||||
|
||||
result := Result{item: item}
|
||||
numChars := item.text.Length()
|
||||
minBegin := math.MaxUint16
|
||||
minEnd := math.MaxUint16
|
||||
maxEnd := 0
|
||||
validOffsetFound := false
|
||||
for _, offset := range offsets {
|
||||
b, e := int(offset[0]), int(offset[1])
|
||||
if b < e {
|
||||
minBegin = util.Min(b, minBegin)
|
||||
minEnd = util.Min(e, minEnd)
|
||||
maxEnd = util.Max(e, maxEnd)
|
||||
validOffsetFound = true
|
||||
}
|
||||
}
|
||||
|
||||
for idx, criterion := range sortCriteria {
|
||||
val := uint16(math.MaxUint16)
|
||||
switch criterion {
|
||||
case byScore:
|
||||
// Higher is better
|
||||
val = math.MaxUint16 - util.AsUint16(score)
|
||||
case byLength:
|
||||
val = item.TrimLength()
|
||||
case byBegin, byEnd:
|
||||
if validOffsetFound {
|
||||
whitePrefixLen := 0
|
||||
for idx := 0; idx < numChars; idx++ {
|
||||
r := item.text.Get(idx)
|
||||
whitePrefixLen = idx
|
||||
if idx == minBegin || !unicode.IsSpace(r) {
|
||||
break
|
||||
}
|
||||
}
|
||||
if criterion == byBegin {
|
||||
val = util.AsUint16(minEnd - whitePrefixLen)
|
||||
} else {
|
||||
val = util.AsUint16(math.MaxUint16 - math.MaxUint16*(maxEnd-whitePrefixLen)/int(item.TrimLength()))
|
||||
}
|
||||
}
|
||||
}
|
||||
result.points[3-idx] = val
|
||||
}
|
||||
|
||||
return result
|
||||
}
|
||||
|
||||
// Sort criteria to use. Never changes once fzf is started.
|
||||
var sortCriteria []criterion
|
||||
|
||||
// Index returns ordinal index of the Item
|
||||
func (result *Result) Index() int32 {
|
||||
return result.item.Index()
|
||||
}
|
||||
|
||||
func minRank() Result {
|
||||
return Result{item: &minItem, points: [4]uint16{math.MaxUint16, 0, 0, 0}}
|
||||
}
|
||||
|
||||
func (result *Result) colorOffsets(matchOffsets []Offset, theme *tui.ColorTheme, colBase tui.ColorPair, colMatch tui.ColorPair, current bool) []colorOffset {
|
||||
itemColors := result.item.Colors()
|
||||
|
||||
// No ANSI codes
|
||||
if len(itemColors) == 0 {
|
||||
var offsets []colorOffset
|
||||
for _, off := range matchOffsets {
|
||||
offsets = append(offsets, colorOffset{offset: [2]int32{off[0], off[1]}, color: colMatch})
|
||||
}
|
||||
return offsets
|
||||
}
|
||||
|
||||
// Find max column
|
||||
var maxCol int32
|
||||
for _, off := range matchOffsets {
|
||||
if off[1] > maxCol {
|
||||
maxCol = off[1]
|
||||
}
|
||||
}
|
||||
for _, ansi := range itemColors {
|
||||
if ansi.offset[1] > maxCol {
|
||||
maxCol = ansi.offset[1]
|
||||
}
|
||||
}
|
||||
|
||||
cols := make([]int, maxCol)
|
||||
for colorIndex, ansi := range itemColors {
|
||||
for i := ansi.offset[0]; i < ansi.offset[1]; i++ {
|
||||
cols[i] = colorIndex + 1 // 1-based index of itemColors
|
||||
}
|
||||
}
|
||||
|
||||
for _, off := range matchOffsets {
|
||||
for i := off[0]; i < off[1]; i++ {
|
||||
// Negative of 1-based index of itemColors
|
||||
// - The extra -1 means highlighted
|
||||
cols[i] = cols[i]*-1 - 1
|
||||
}
|
||||
}
|
||||
|
||||
// sort.Sort(ByOrder(offsets))
|
||||
|
||||
// Merge offsets
|
||||
// ------------ ---- -- ----
|
||||
// ++++++++ ++++++++++
|
||||
// --++++++++-- --++++++++++---
|
||||
curr := 0
|
||||
start := 0
|
||||
ansiToColorPair := func(ansi ansiOffset, base tui.ColorPair) tui.ColorPair {
|
||||
fg := ansi.color.fg
|
||||
bg := ansi.color.bg
|
||||
if fg == -1 {
|
||||
if current {
|
||||
fg = theme.Current.Color
|
||||
} else {
|
||||
fg = theme.Fg.Color
|
||||
}
|
||||
}
|
||||
if bg == -1 {
|
||||
if current {
|
||||
bg = theme.DarkBg.Color
|
||||
} else {
|
||||
bg = theme.Bg.Color
|
||||
}
|
||||
}
|
||||
return tui.NewColorPair(fg, bg, ansi.color.attr).MergeAttr(base)
|
||||
}
|
||||
var colors []colorOffset
|
||||
add := func(idx int) {
|
||||
if curr != 0 && idx > start {
|
||||
if curr < 0 {
|
||||
color := colMatch
|
||||
if curr < -1 && theme.Colored {
|
||||
origColor := ansiToColorPair(itemColors[-curr-2], colMatch)
|
||||
// hl or hl+ only sets the foreground color, so colMatch is the
|
||||
// combination of either [hl and bg] or [hl+ and bg+].
|
||||
//
|
||||
// If the original text already has background color, and the
|
||||
// foreground color of colMatch is -1, we shouldn't only apply the
|
||||
// background color of colMatch.
|
||||
// e.g. echo -e "\x1b[32;7mfoo\x1b[mbar" | fzf --ansi --color bg+:1,hl+:-1:underline
|
||||
// echo -e "\x1b[42mfoo\x1b[mbar" | fzf --ansi --color bg+:1,hl+:-1:underline
|
||||
if color.Fg().IsDefault() && origColor.HasBg() {
|
||||
color = origColor
|
||||
} else {
|
||||
color = origColor.MergeNonDefault(color)
|
||||
}
|
||||
}
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(idx)}, color: color})
|
||||
} else {
|
||||
ansi := itemColors[curr-1]
|
||||
colors = append(colors, colorOffset{
|
||||
offset: [2]int32{int32(start), int32(idx)},
|
||||
color: ansiToColorPair(ansi, colBase)})
|
||||
}
|
||||
}
|
||||
}
|
||||
for idx, col := range cols {
|
||||
if col != curr {
|
||||
add(idx)
|
||||
start = idx
|
||||
curr = col
|
||||
}
|
||||
}
|
||||
add(int(maxCol))
|
||||
return colors
|
||||
}
|
||||
|
||||
// ByOrder is for sorting substring offsets
|
||||
type ByOrder []Offset
|
||||
|
||||
func (a ByOrder) Len() int {
|
||||
return len(a)
|
||||
}
|
||||
|
||||
func (a ByOrder) Swap(i, j int) {
|
||||
a[i], a[j] = a[j], a[i]
|
||||
}
|
||||
|
||||
func (a ByOrder) Less(i, j int) bool {
|
||||
ioff := a[i]
|
||||
joff := a[j]
|
||||
return (ioff[0] < joff[0]) || (ioff[0] == joff[0]) && (ioff[1] <= joff[1])
|
||||
}
|
||||
|
||||
// ByRelevance is for sorting Items
|
||||
type ByRelevance []Result
|
||||
|
||||
func (a ByRelevance) Len() int {
|
||||
return len(a)
|
||||
}
|
||||
|
||||
func (a ByRelevance) Swap(i, j int) {
|
||||
a[i], a[j] = a[j], a[i]
|
||||
}
|
||||
|
||||
func (a ByRelevance) Less(i, j int) bool {
|
||||
return compareRanks(a[i], a[j], false)
|
||||
}
|
||||
|
||||
// ByRelevanceTac is for sorting Items
|
||||
type ByRelevanceTac []Result
|
||||
|
||||
func (a ByRelevanceTac) Len() int {
|
||||
return len(a)
|
||||
}
|
||||
|
||||
func (a ByRelevanceTac) Swap(i, j int) {
|
||||
a[i], a[j] = a[j], a[i]
|
||||
}
|
||||
|
||||
func (a ByRelevanceTac) Less(i, j int) bool {
|
||||
return compareRanks(a[i], a[j], true)
|
||||
}
|
||||
@ -1,16 +0,0 @@
|
||||
// +build !386,!amd64
|
||||
|
||||
package fzf
|
||||
|
||||
func compareRanks(irank Result, jrank Result, tac bool) bool {
|
||||
for idx := 3; idx >= 0; idx-- {
|
||||
left := irank.points[idx]
|
||||
right := jrank.points[idx]
|
||||
if left < right {
|
||||
return true
|
||||
} else if left > right {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||
}
|
||||
@ -1,159 +0,0 @@
|
||||
// +build !tcell
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"math"
|
||||
"sort"
|
||||
"testing"
|
||||
|
||||
"github.com/junegunn/fzf/src/tui"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func withIndex(i *Item, index int) *Item {
|
||||
(*i).text.Index = int32(index)
|
||||
return i
|
||||
}
|
||||
|
||||
func TestOffsetSort(t *testing.T) {
|
||||
offsets := []Offset{
|
||||
{3, 5}, {2, 7},
|
||||
{1, 3}, {2, 9}}
|
||||
sort.Sort(ByOrder(offsets))
|
||||
|
||||
if offsets[0][0] != 1 || offsets[0][1] != 3 ||
|
||||
offsets[1][0] != 2 || offsets[1][1] != 7 ||
|
||||
offsets[2][0] != 2 || offsets[2][1] != 9 ||
|
||||
offsets[3][0] != 3 || offsets[3][1] != 5 {
|
||||
t.Error("Invalid order:", offsets)
|
||||
}
|
||||
}
|
||||
|
||||
func TestRankComparison(t *testing.T) {
|
||||
rank := func(vals ...uint16) Result {
|
||||
return Result{
|
||||
points: [4]uint16{vals[0], vals[1], vals[2], vals[3]},
|
||||
item: &Item{text: util.Chars{Index: int32(vals[4])}}}
|
||||
}
|
||||
if compareRanks(rank(3, 0, 0, 0, 5), rank(2, 0, 0, 0, 7), false) ||
|
||||
!compareRanks(rank(3, 0, 0, 0, 5), rank(3, 0, 0, 0, 6), false) ||
|
||||
!compareRanks(rank(1, 2, 0, 0, 3), rank(1, 3, 0, 0, 2), false) ||
|
||||
!compareRanks(rank(0, 0, 0, 0, 0), rank(0, 0, 0, 0, 0), false) {
|
||||
t.Error("Invalid order")
|
||||
}
|
||||
|
||||
if compareRanks(rank(3, 0, 0, 0, 5), rank(2, 0, 0, 0, 7), true) ||
|
||||
!compareRanks(rank(3, 0, 0, 0, 5), rank(3, 0, 0, 0, 6), false) ||
|
||||
!compareRanks(rank(1, 2, 0, 0, 3), rank(1, 3, 0, 0, 2), true) ||
|
||||
!compareRanks(rank(0, 0, 0, 0, 0), rank(0, 0, 0, 0, 0), false) {
|
||||
t.Error("Invalid order (tac)")
|
||||
}
|
||||
}
|
||||
|
||||
// Match length, string length, index
|
||||
func TestResultRank(t *testing.T) {
|
||||
// FIXME global
|
||||
sortCriteria = []criterion{byScore, byLength}
|
||||
|
||||
strs := [][]rune{[]rune("foo"), []rune("foobar"), []rune("bar"), []rune("baz")}
|
||||
item1 := buildResult(
|
||||
withIndex(&Item{text: util.RunesToChars(strs[0])}, 1), []Offset{}, 2)
|
||||
if item1.points[3] != math.MaxUint16-2 || // Bonus
|
||||
item1.points[2] != 3 || // Length
|
||||
item1.points[1] != 0 || // Unused
|
||||
item1.points[0] != 0 || // Unused
|
||||
item1.item.Index() != 1 {
|
||||
t.Error(item1)
|
||||
}
|
||||
// Only differ in index
|
||||
item2 := buildResult(&Item{text: util.RunesToChars(strs[0])}, []Offset{}, 2)
|
||||
|
||||
items := []Result{item1, item2}
|
||||
sort.Sort(ByRelevance(items))
|
||||
if items[0] != item2 || items[1] != item1 {
|
||||
t.Error(items)
|
||||
}
|
||||
|
||||
items = []Result{item2, item1, item1, item2}
|
||||
sort.Sort(ByRelevance(items))
|
||||
if items[0] != item2 || items[1] != item2 ||
|
||||
items[2] != item1 || items[3] != item1 {
|
||||
t.Error(items, item1, item1.item.Index(), item2, item2.item.Index())
|
||||
}
|
||||
|
||||
// Sort by relevance
|
||||
item3 := buildResult(
|
||||
withIndex(&Item{}, 2), []Offset{{1, 3}, {5, 7}}, 3)
|
||||
item4 := buildResult(
|
||||
withIndex(&Item{}, 2), []Offset{{1, 2}, {6, 7}}, 4)
|
||||
item5 := buildResult(
|
||||
withIndex(&Item{}, 2), []Offset{{1, 3}, {5, 7}}, 5)
|
||||
item6 := buildResult(
|
||||
withIndex(&Item{}, 2), []Offset{{1, 2}, {6, 7}}, 6)
|
||||
items = []Result{item1, item2, item3, item4, item5, item6}
|
||||
sort.Sort(ByRelevance(items))
|
||||
if !(items[0] == item6 && items[1] == item5 &&
|
||||
items[2] == item4 && items[3] == item3 &&
|
||||
items[4] == item2 && items[5] == item1) {
|
||||
t.Error(items, item1, item2, item3, item4, item5, item6)
|
||||
}
|
||||
}
|
||||
|
||||
func TestColorOffset(t *testing.T) {
|
||||
// ------------ 20 ---- -- ----
|
||||
// ++++++++ ++++++++++
|
||||
// --++++++++-- --++++++++++---
|
||||
|
||||
offsets := []Offset{{5, 15}, {25, 35}}
|
||||
item := Result{
|
||||
item: &Item{
|
||||
colors: &[]ansiOffset{
|
||||
{[2]int32{0, 20}, ansiState{1, 5, 0, -1}},
|
||||
{[2]int32{22, 27}, ansiState{2, 6, tui.Bold, -1}},
|
||||
{[2]int32{30, 32}, ansiState{3, 7, 0, -1}},
|
||||
{[2]int32{33, 40}, ansiState{4, 8, tui.Bold, -1}}}}}
|
||||
|
||||
colBase := tui.NewColorPair(89, 189, tui.AttrUndefined)
|
||||
colMatch := tui.NewColorPair(99, 199, tui.AttrUndefined)
|
||||
colors := item.colorOffsets(offsets, tui.Dark256, colBase, colMatch, true)
|
||||
assert := func(idx int, b int32, e int32, c tui.ColorPair) {
|
||||
o := colors[idx]
|
||||
if o.offset[0] != b || o.offset[1] != e || o.color != c {
|
||||
t.Error(o, b, e, c)
|
||||
}
|
||||
}
|
||||
// [{[0 5] {1 5 0}} {[5 15] {99 199 0}} {[15 20] {1 5 0}}
|
||||
// {[22 25] {2 6 1}} {[25 27] {99 199 1}} {[27 30] {99 199 0}}
|
||||
// {[30 32] {99 199 0}} {[32 33] {99 199 0}} {[33 35] {99 199 1}}
|
||||
// {[35 40] {4 8 1}}]
|
||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(1, 5, 15, colMatch)
|
||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(3, 22, 25, tui.NewColorPair(2, 6, tui.Bold))
|
||||
assert(4, 25, 27, colMatch.WithAttr(tui.Bold))
|
||||
assert(5, 27, 30, colMatch)
|
||||
assert(6, 30, 32, colMatch)
|
||||
assert(7, 32, 33, colMatch) // TODO: Should we merge consecutive blocks?
|
||||
assert(8, 33, 35, colMatch.WithAttr(tui.Bold))
|
||||
assert(9, 35, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||
|
||||
colRegular := tui.NewColorPair(-1, -1, tui.AttrUndefined)
|
||||
colUnderline := tui.NewColorPair(-1, -1, tui.Underline)
|
||||
colors = item.colorOffsets(offsets, tui.Dark256, colRegular, colUnderline, true)
|
||||
|
||||
// [{[0 5] {1 5 0}} {[5 15] {1 5 8}} {[15 20] {1 5 0}}
|
||||
// {[22 25] {2 6 1}} {[25 27] {2 6 9}} {[27 30] {-1 -1 8}}
|
||||
// {[30 32] {3 7 8}} {[32 33] {-1 -1 8}} {[33 35] {4 8 9}}
|
||||
// {[35 40] {4 8 1}}]
|
||||
assert(0, 0, 5, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(1, 5, 15, tui.NewColorPair(1, 5, tui.Underline))
|
||||
assert(2, 15, 20, tui.NewColorPair(1, 5, tui.AttrUndefined))
|
||||
assert(3, 22, 25, tui.NewColorPair(2, 6, tui.Bold))
|
||||
assert(4, 25, 27, tui.NewColorPair(2, 6, tui.Bold|tui.Underline))
|
||||
assert(5, 27, 30, colUnderline)
|
||||
assert(6, 30, 32, tui.NewColorPair(3, 7, tui.Underline))
|
||||
assert(7, 32, 33, colUnderline)
|
||||
assert(8, 33, 35, tui.NewColorPair(4, 8, tui.Bold|tui.Underline))
|
||||
assert(9, 35, 40, tui.NewColorPair(4, 8, tui.Bold))
|
||||
}
|
||||
@ -1,16 +0,0 @@
|
||||
// +build 386 amd64
|
||||
|
||||
package fzf
|
||||
|
||||
import "unsafe"
|
||||
|
||||
func compareRanks(irank Result, jrank Result, tac bool) bool {
|
||||
left := *(*uint64)(unsafe.Pointer(&irank.points[0]))
|
||||
right := *(*uint64)(unsafe.Pointer(&jrank.points[0]))
|
||||
if left < right {
|
||||
return true
|
||||
} else if left > right {
|
||||
return false
|
||||
}
|
||||
return (irank.item.Index() <= jrank.item.Index()) != tac
|
||||
}
|
||||
2832
.fzf/src/terminal.go
2832
.fzf/src/terminal.go
File diff suppressed because it is too large
Load Diff
@ -1,638 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"io"
|
||||
"os"
|
||||
"regexp"
|
||||
"strings"
|
||||
"testing"
|
||||
"text/template"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func TestReplacePlaceholder(t *testing.T) {
|
||||
item1 := newItem(" foo'bar \x1b[31mbaz\x1b[m")
|
||||
items1 := []*Item{item1, item1}
|
||||
items2 := []*Item{
|
||||
newItem("foo'bar \x1b[31mbaz\x1b[m"),
|
||||
newItem("foo'bar \x1b[31mbaz\x1b[m"),
|
||||
newItem("FOO'BAR \x1b[31mBAZ\x1b[m")}
|
||||
|
||||
delim := "'"
|
||||
var regex *regexp.Regexp
|
||||
|
||||
var result string
|
||||
check := func(expected string) {
|
||||
if result != expected {
|
||||
t.Errorf("expected: %s, actual: %s", expected, result)
|
||||
}
|
||||
}
|
||||
// helper function that converts template format into string and carries out the check()
|
||||
checkFormat := func(format string) {
|
||||
type quotes struct{ O, I, S string } // outer, inner quotes, print separator
|
||||
unixStyle := quotes{`'`, `'\''`, "\n"}
|
||||
windowsStyle := quotes{`^"`, `'`, "\n"}
|
||||
var effectiveStyle quotes
|
||||
|
||||
if util.IsWindows() {
|
||||
effectiveStyle = windowsStyle
|
||||
} else {
|
||||
effectiveStyle = unixStyle
|
||||
}
|
||||
|
||||
expected := templateToString(format, effectiveStyle)
|
||||
check(expected)
|
||||
}
|
||||
printsep := "\n"
|
||||
|
||||
/*
|
||||
Test multiple placeholders and the function parameters.
|
||||
*/
|
||||
|
||||
// {}, preserve ansi
|
||||
result = replacePlaceholder("echo {}", false, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar \x1b[31mbaz\x1b[m{{.O}}")
|
||||
|
||||
// {}, strip ansi
|
||||
result = replacePlaceholder("echo {}", true, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
// {}, with multiple items
|
||||
result = replacePlaceholder("echo {}", true, Delimiter{}, printsep, false, "query", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
// {..}, strip leading whitespaces, preserve ansi
|
||||
result = replacePlaceholder("echo {..}", false, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar \x1b[31mbaz\x1b[m{{.O}}")
|
||||
|
||||
// {..}, strip leading whitespaces, strip ansi
|
||||
result = replacePlaceholder("echo {..}", true, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
// {q}
|
||||
result = replacePlaceholder("echo {} {q}", true, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}} {{.O}}query{{.O}}")
|
||||
|
||||
// {q}, multiple items
|
||||
result = replacePlaceholder("echo {+}{q}{+}", true, Delimiter{}, printsep, false, "query 'string'", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}} {{.O}}FOO{{.I}}BAR BAZ{{.O}}{{.O}}query {{.I}}string{{.I}}{{.O}}{{.O}}foo{{.I}}bar baz{{.O}} {{.O}}FOO{{.I}}BAR BAZ{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {}{q}{}", true, Delimiter{}, printsep, false, "query 'string'", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar baz{{.O}}{{.O}}query {{.I}}string{{.I}}{{.O}}{{.O}}foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {1}/{2}/{2,1}/{-1}/{-2}/{}/{..}/{n.t}/\\{}/\\{1}/\\{q}/{3}", true, Delimiter{}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar{{.O}}/{{.O}}baz{{.O}}/{{.O}}bazfoo{{.I}}bar{{.O}}/{{.O}}baz{{.O}}/{{.O}}foo{{.I}}bar{{.O}}/{{.O}} foo{{.I}}bar baz{{.O}}/{{.O}}foo{{.I}}bar baz{{.O}}/{n.t}/{}/{1}/{q}/{{.O}}{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {1}/{2}/{-1}/{-2}/{..}/{n.t}/\\{}/\\{1}/\\{q}/{3}", true, Delimiter{}, printsep, false, "query", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar{{.O}}/{{.O}}baz{{.O}}/{{.O}}baz{{.O}}/{{.O}}foo{{.I}}bar{{.O}}/{{.O}}foo{{.I}}bar baz{{.O}}/{n.t}/{}/{1}/{q}/{{.O}}{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {+1}/{+2}/{+-1}/{+-2}/{+..}/{n.t}/\\{}/\\{1}/\\{q}/{+3}", true, Delimiter{}, printsep, false, "query", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar{{.O}} {{.O}}FOO{{.I}}BAR{{.O}}/{{.O}}baz{{.O}} {{.O}}BAZ{{.O}}/{{.O}}baz{{.O}} {{.O}}BAZ{{.O}}/{{.O}}foo{{.I}}bar{{.O}} {{.O}}FOO{{.I}}BAR{{.O}}/{{.O}}foo{{.I}}bar baz{{.O}} {{.O}}FOO{{.I}}BAR BAZ{{.O}}/{n.t}/{}/{1}/{q}/{{.O}}{{.O}} {{.O}}{{.O}}")
|
||||
|
||||
// forcePlus
|
||||
result = replacePlaceholder("echo {1}/{2}/{-1}/{-2}/{..}/{n.t}/\\{}/\\{1}/\\{q}/{3}", true, Delimiter{}, printsep, true, "query", items2)
|
||||
checkFormat("echo {{.O}}foo{{.I}}bar{{.O}} {{.O}}FOO{{.I}}BAR{{.O}}/{{.O}}baz{{.O}} {{.O}}BAZ{{.O}}/{{.O}}baz{{.O}} {{.O}}BAZ{{.O}}/{{.O}}foo{{.I}}bar{{.O}} {{.O}}FOO{{.I}}BAR{{.O}}/{{.O}}foo{{.I}}bar baz{{.O}} {{.O}}FOO{{.I}}BAR BAZ{{.O}}/{n.t}/{}/{1}/{q}/{{.O}}{{.O}} {{.O}}{{.O}}")
|
||||
|
||||
// Whitespace preserving flag with "'" delimiter
|
||||
result = replacePlaceholder("echo {s1}", true, Delimiter{str: &delim}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {s2}", true, Delimiter{str: &delim}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}}bar baz{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {s}", true, Delimiter{str: &delim}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {s..}", true, Delimiter{str: &delim}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
// Whitespace preserving flag with regex delimiter
|
||||
regex = regexp.MustCompile(`\w+`)
|
||||
|
||||
result = replacePlaceholder("echo {s1}", true, Delimiter{regex: regex}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} {{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {s2}", true, Delimiter{regex: regex}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}}{{.I}}{{.O}}")
|
||||
|
||||
result = replacePlaceholder("echo {s3}", true, Delimiter{regex: regex}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} {{.O}}")
|
||||
|
||||
// No match
|
||||
result = replacePlaceholder("echo {}/{+}", true, Delimiter{}, printsep, false, "query", []*Item{nil, nil})
|
||||
check("echo /")
|
||||
|
||||
// No match, but with selections
|
||||
result = replacePlaceholder("echo {}/{+}", true, Delimiter{}, printsep, false, "query", []*Item{nil, item1})
|
||||
checkFormat("echo /{{.O}} foo{{.I}}bar baz{{.O}}")
|
||||
|
||||
// String delimiter
|
||||
result = replacePlaceholder("echo {}/{1}/{2}", true, Delimiter{str: &delim}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}/{{.O}}foo{{.O}}/{{.O}}bar baz{{.O}}")
|
||||
|
||||
// Regex delimiter
|
||||
regex = regexp.MustCompile("[oa]+")
|
||||
// foo'bar baz
|
||||
result = replacePlaceholder("echo {}/{1}/{3}/{2..3}", true, Delimiter{regex: regex}, printsep, false, "query", items1)
|
||||
checkFormat("echo {{.O}} foo{{.I}}bar baz{{.O}}/{{.O}}f{{.O}}/{{.O}}r b{{.O}}/{{.O}}{{.I}}bar b{{.O}}")
|
||||
|
||||
/*
|
||||
Test single placeholders, but focus on the placeholders' parameters (e.g. flags).
|
||||
see: TestParsePlaceholder
|
||||
*/
|
||||
items3 := []*Item{
|
||||
// single line
|
||||
newItem("1a 1b 1c 1d 1e 1f"),
|
||||
// multi line
|
||||
newItem("1a 1b 1c 1d 1e 1f"),
|
||||
newItem("2a 2b 2c 2d 2e 2f"),
|
||||
newItem("3a 3b 3c 3d 3e 3f"),
|
||||
newItem("4a 4b 4c 4d 4e 4f"),
|
||||
newItem("5a 5b 5c 5d 5e 5f"),
|
||||
newItem("6a 6b 6c 6d 6e 6f"),
|
||||
newItem("7a 7b 7c 7d 7e 7f"),
|
||||
}
|
||||
stripAnsi := false
|
||||
printsep = "\n"
|
||||
forcePlus := false
|
||||
query := "sample query"
|
||||
|
||||
templateToOutput := make(map[string]string)
|
||||
templateToFile := make(map[string]string) // same as above, but the file contents will be matched
|
||||
// I. item type placeholder
|
||||
templateToOutput[`{}`] = `{{.O}}1a 1b 1c 1d 1e 1f{{.O}}`
|
||||
templateToOutput[`{+}`] = `{{.O}}1a 1b 1c 1d 1e 1f{{.O}} {{.O}}2a 2b 2c 2d 2e 2f{{.O}} {{.O}}3a 3b 3c 3d 3e 3f{{.O}} {{.O}}4a 4b 4c 4d 4e 4f{{.O}} {{.O}}5a 5b 5c 5d 5e 5f{{.O}} {{.O}}6a 6b 6c 6d 6e 6f{{.O}} {{.O}}7a 7b 7c 7d 7e 7f{{.O}}`
|
||||
templateToOutput[`{n}`] = `0`
|
||||
templateToOutput[`{+n}`] = `0 0 0 0 0 0 0`
|
||||
templateToFile[`{f}`] = `1a 1b 1c 1d 1e 1f{{.S}}`
|
||||
templateToFile[`{+f}`] = `1a 1b 1c 1d 1e 1f{{.S}}2a 2b 2c 2d 2e 2f{{.S}}3a 3b 3c 3d 3e 3f{{.S}}4a 4b 4c 4d 4e 4f{{.S}}5a 5b 5c 5d 5e 5f{{.S}}6a 6b 6c 6d 6e 6f{{.S}}7a 7b 7c 7d 7e 7f{{.S}}`
|
||||
templateToFile[`{nf}`] = `0{{.S}}`
|
||||
templateToFile[`{+nf}`] = `0{{.S}}0{{.S}}0{{.S}}0{{.S}}0{{.S}}0{{.S}}0{{.S}}`
|
||||
|
||||
// II. token type placeholders
|
||||
templateToOutput[`{..}`] = templateToOutput[`{}`]
|
||||
templateToOutput[`{1..}`] = templateToOutput[`{}`]
|
||||
templateToOutput[`{..2}`] = `{{.O}}1a 1b{{.O}}`
|
||||
templateToOutput[`{1..2}`] = templateToOutput[`{..2}`]
|
||||
templateToOutput[`{-2..-1}`] = `{{.O}}1e 1f{{.O}}`
|
||||
// shorthand for x..x range
|
||||
templateToOutput[`{1}`] = `{{.O}}1a{{.O}}`
|
||||
templateToOutput[`{1..1}`] = templateToOutput[`{1}`]
|
||||
templateToOutput[`{-6}`] = templateToOutput[`{1}`]
|
||||
// multiple ranges
|
||||
templateToOutput[`{1,2}`] = templateToOutput[`{1..2}`]
|
||||
templateToOutput[`{1,2,4}`] = `{{.O}}1a 1b 1d{{.O}}`
|
||||
templateToOutput[`{1,2..4}`] = `{{.O}}1a 1b 1c 1d{{.O}}`
|
||||
templateToOutput[`{1..2,-4..-3}`] = `{{.O}}1a 1b 1c 1d{{.O}}`
|
||||
// flags
|
||||
templateToOutput[`{+1}`] = `{{.O}}1a{{.O}} {{.O}}2a{{.O}} {{.O}}3a{{.O}} {{.O}}4a{{.O}} {{.O}}5a{{.O}} {{.O}}6a{{.O}} {{.O}}7a{{.O}}`
|
||||
templateToOutput[`{+-1}`] = `{{.O}}1f{{.O}} {{.O}}2f{{.O}} {{.O}}3f{{.O}} {{.O}}4f{{.O}} {{.O}}5f{{.O}} {{.O}}6f{{.O}} {{.O}}7f{{.O}}`
|
||||
templateToOutput[`{s1}`] = `{{.O}}1a {{.O}}`
|
||||
templateToFile[`{f1}`] = `1a{{.S}}`
|
||||
templateToOutput[`{+s1..2}`] = `{{.O}}1a 1b {{.O}} {{.O}}2a 2b {{.O}} {{.O}}3a 3b {{.O}} {{.O}}4a 4b {{.O}} {{.O}}5a 5b {{.O}} {{.O}}6a 6b {{.O}} {{.O}}7a 7b {{.O}}`
|
||||
templateToFile[`{+sf1..2}`] = `1a 1b {{.S}}2a 2b {{.S}}3a 3b {{.S}}4a 4b {{.S}}5a 5b {{.S}}6a 6b {{.S}}7a 7b {{.S}}`
|
||||
|
||||
// III. query type placeholder
|
||||
// query flag is not removed after parsing, so it gets doubled
|
||||
// while the double q is invalid, it is useful here for testing purposes
|
||||
templateToOutput[`{q}`] = "{{.O}}" + query + "{{.O}}"
|
||||
|
||||
// IV. escaping placeholder
|
||||
templateToOutput[`\{}`] = `{}`
|
||||
templateToOutput[`\{++}`] = `{++}`
|
||||
templateToOutput[`{++}`] = templateToOutput[`{+}`]
|
||||
|
||||
for giveTemplate, wantOutput := range templateToOutput {
|
||||
result = replacePlaceholder(giveTemplate, stripAnsi, Delimiter{}, printsep, forcePlus, query, items3)
|
||||
checkFormat(wantOutput)
|
||||
}
|
||||
for giveTemplate, wantOutput := range templateToFile {
|
||||
path := replacePlaceholder(giveTemplate, stripAnsi, Delimiter{}, printsep, forcePlus, query, items3)
|
||||
|
||||
data, err := readFile(path)
|
||||
if err != nil {
|
||||
t.Errorf("Cannot read the content of the temp file %s.", path)
|
||||
}
|
||||
result = string(data)
|
||||
|
||||
checkFormat(wantOutput)
|
||||
}
|
||||
}
|
||||
|
||||
func TestQuoteEntry(t *testing.T) {
|
||||
type quotes struct{ E, O, SQ, DQ, BS string } // standalone escape, outer, single and double quotes, backslash
|
||||
unixStyle := quotes{``, `'`, `'\''`, `"`, `\`}
|
||||
windowsStyle := quotes{`^`, `^"`, `'`, `\^"`, `\\`}
|
||||
var effectiveStyle quotes
|
||||
|
||||
if util.IsWindows() {
|
||||
effectiveStyle = windowsStyle
|
||||
} else {
|
||||
effectiveStyle = unixStyle
|
||||
}
|
||||
|
||||
tests := map[string]string{
|
||||
`'`: `{{.O}}{{.SQ}}{{.O}}`,
|
||||
`"`: `{{.O}}{{.DQ}}{{.O}}`,
|
||||
`\`: `{{.O}}{{.BS}}{{.O}}`,
|
||||
`\"`: `{{.O}}{{.BS}}{{.DQ}}{{.O}}`,
|
||||
`"\\\"`: `{{.O}}{{.DQ}}{{.BS}}{{.BS}}{{.BS}}{{.DQ}}{{.O}}`,
|
||||
|
||||
`$`: `{{.O}}${{.O}}`,
|
||||
`$HOME`: `{{.O}}$HOME{{.O}}`,
|
||||
`'$HOME'`: `{{.O}}{{.SQ}}$HOME{{.SQ}}{{.O}}`,
|
||||
|
||||
`&`: `{{.O}}{{.E}}&{{.O}}`,
|
||||
`|`: `{{.O}}{{.E}}|{{.O}}`,
|
||||
`<`: `{{.O}}{{.E}}<{{.O}}`,
|
||||
`>`: `{{.O}}{{.E}}>{{.O}}`,
|
||||
`(`: `{{.O}}{{.E}}({{.O}}`,
|
||||
`)`: `{{.O}}{{.E}}){{.O}}`,
|
||||
`@`: `{{.O}}{{.E}}@{{.O}}`,
|
||||
`^`: `{{.O}}{{.E}}^{{.O}}`,
|
||||
`%`: `{{.O}}{{.E}}%{{.O}}`,
|
||||
`!`: `{{.O}}{{.E}}!{{.O}}`,
|
||||
`%USERPROFILE%`: `{{.O}}{{.E}}%USERPROFILE{{.E}}%{{.O}}`,
|
||||
`C:\Program Files (x86)\`: `{{.O}}C:{{.BS}}Program Files {{.E}}(x86{{.E}}){{.BS}}{{.O}}`,
|
||||
`"C:\Program Files"`: `{{.O}}{{.DQ}}C:{{.BS}}Program Files{{.DQ}}{{.O}}`,
|
||||
}
|
||||
|
||||
for input, expected := range tests {
|
||||
escaped := quoteEntry(input)
|
||||
expected = templateToString(expected, effectiveStyle)
|
||||
if escaped != expected {
|
||||
t.Errorf("Input: %s, expected: %s, actual %s", input, expected, escaped)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// purpose of this test is to demonstrate some shortcomings of fzf's templating system on Unix
|
||||
func TestUnixCommands(t *testing.T) {
|
||||
if util.IsWindows() {
|
||||
t.SkipNow()
|
||||
}
|
||||
tests := []testCase{
|
||||
// reference: give{template, query, items}, want{output OR match}
|
||||
|
||||
// 1) working examples
|
||||
|
||||
// paths that does not have to evaluated will work fine, when quoted
|
||||
{give{`grep foo {}`, ``, newItems(`test`)}, want{output: `grep foo 'test'`}},
|
||||
{give{`grep foo {}`, ``, newItems(`/home/user/test`)}, want{output: `grep foo '/home/user/test'`}},
|
||||
{give{`grep foo {}`, ``, newItems(`./test`)}, want{output: `grep foo './test'`}},
|
||||
|
||||
// only placeholders are escaped as data, this will lookup tilde character in a test file in your home directory
|
||||
// quoting the tilde is required (to be treated as string)
|
||||
{give{`grep {} ~/test`, ``, newItems(`~`)}, want{output: `grep '~' ~/test`}},
|
||||
|
||||
// 2) problematic examples
|
||||
// (not necessarily unexpected)
|
||||
|
||||
// paths that need to expand some part of it won't work (special characters and variables)
|
||||
{give{`cat {}`, ``, newItems(`~/test`)}, want{output: `cat '~/test'`}},
|
||||
{give{`cat {}`, ``, newItems(`$HOME/test`)}, want{output: `cat '$HOME/test'`}},
|
||||
}
|
||||
testCommands(t, tests)
|
||||
}
|
||||
|
||||
// purpose of this test is to demonstrate some shortcomings of fzf's templating system on Windows
|
||||
func TestWindowsCommands(t *testing.T) {
|
||||
if !util.IsWindows() {
|
||||
t.SkipNow()
|
||||
}
|
||||
tests := []testCase{
|
||||
// reference: give{template, query, items}, want{output OR match}
|
||||
|
||||
// 1) working examples
|
||||
|
||||
// example of redundantly escaped backslash in the output, besides looking bit ugly, it won't cause any issue
|
||||
{give{`type {}`, ``, newItems(`C:\test.txt`)}, want{output: `type ^"C:\\test.txt^"`}},
|
||||
{give{`rg -- "package" {}`, ``, newItems(`.\test.go`)}, want{output: `rg -- "package" ^".\\test.go^"`}},
|
||||
// example of mandatorily escaped backslash in the output, otherwise `rg -- "C:\test.txt"` is matching for tabulator
|
||||
{give{`rg -- {}`, ``, newItems(`C:\test.txt`)}, want{output: `rg -- ^"C:\\test.txt^"`}},
|
||||
// example of mandatorily escaped double quote in the output, otherwise `rg -- ""C:\\test.txt""` is not matching for the double quotes around the path
|
||||
{give{`rg -- {}`, ``, newItems(`"C:\test.txt"`)}, want{output: `rg -- ^"\^"C:\\test.txt\^"^"`}},
|
||||
|
||||
// 2) problematic examples
|
||||
// (not necessarily unexpected)
|
||||
|
||||
// notepad++'s parser can't handle `-n"12"` generate by fzf, expects `-n12`
|
||||
{give{`notepad++ -n{1} {2}`, ``, newItems(`12 C:\Work\Test Folder\File.txt`)}, want{output: `notepad++ -n^"12^" ^"C:\\Work\\Test Folder\\File.txt^"`}},
|
||||
|
||||
// cat is parsing `\"` as a part of the file path, double quote is illegal character for paths on Windows
|
||||
// cat: "C:\\test.txt: Invalid argument
|
||||
{give{`cat {}`, ``, newItems(`"C:\test.txt"`)}, want{output: `cat ^"\^"C:\\test.txt\^"^"`}},
|
||||
// cat: "C:\\test.txt": Invalid argument
|
||||
{give{`cmd /c {}`, ``, newItems(`cat "C:\test.txt"`)}, want{output: `cmd /c ^"cat \^"C:\\test.txt\^"^"`}},
|
||||
|
||||
// the "file" flag in the pattern won't create *.bat or *.cmd file so the command in the output tries to edit the file, instead of executing it
|
||||
// the temp file contains: `cat "C:\test.txt"`
|
||||
// TODO this should actually work
|
||||
{give{`cmd /c {f}`, ``, newItems(`cat "C:\test.txt"`)}, want{match: `^cmd /c .*\fzf-preview-[0-9]{9}$`}},
|
||||
}
|
||||
testCommands(t, tests)
|
||||
}
|
||||
|
||||
// purpose of this test is to demonstrate some shortcomings of fzf's templating system on Windows in Powershell
|
||||
func TestPowershellCommands(t *testing.T) {
|
||||
if !util.IsWindows() {
|
||||
t.SkipNow()
|
||||
}
|
||||
|
||||
tests := []testCase{
|
||||
// reference: give{template, query, items}, want{output OR match}
|
||||
|
||||
/*
|
||||
You can read each line in the following table as a pipeline that
|
||||
consist of series of parsers that act upon your input (col. 1) and
|
||||
each cell represents the output value.
|
||||
|
||||
For example:
|
||||
- exec.Command("program.exe", `\''`)
|
||||
- goes to win32 api which will process it transparently as it contains no special characters, see [CommandLineToArgvW][].
|
||||
- powershell command will receive it as is, that is two arguments: a literal backslash and empty string in single quotes
|
||||
- native command run via/from powershell will receive only one argument: a literal backslash. Because extra parsing rules apply, see [NativeCallsFromPowershell][].
|
||||
- some¹ apps have internal parser, that requires one more level of escaping (yes, this is completely application-specific, but see terminal_test.go#TestWindowsCommands)
|
||||
|
||||
Character⁰ CommandLineToArgvW Powershell commands Native commands from Powershell Apps requiring escapes¹ | Being tested below
|
||||
---------- ------------------ ------------------------------ ------------------------------- -------------------------- | ------------------
|
||||
" empty string² missing argument error ... ... |
|
||||
\" literal " unbalanced quote error ... ... |
|
||||
'\"' literal '"' literal " empty string empty string (match all) | yes
|
||||
'\\\"' literal '\"' literal \" literal " literal " |
|
||||
---------- ------------------ ------------------------------ ------------------------------- -------------------------- | ------------------
|
||||
\ transparent transparent transparent regex error |
|
||||
'\' transparent literal \ literal \ regex error | yes
|
||||
\\ transparent transparent transparent literal \ |
|
||||
'\\' transparent literal \\ literal \\ literal \ |
|
||||
---------- ------------------ ------------------------------ ------------------------------- -------------------------- | ------------------
|
||||
' transparent unbalanced quote error ... ... |
|
||||
\' transparent literal \ and unb. quote error ... ... |
|
||||
\'' transparent literal \ and empty string literal \ regex error | no, but given as example above
|
||||
''' transparent unbalanced quote error ... ... |
|
||||
'''' transparent literal ' literal ' literal ' | yes
|
||||
---------- ------------------ ------------------------------ ------------------------------- -------------------------- | ------------------
|
||||
|
||||
⁰: charatecter or characters 'x' as an argument to a program in go's call: exec.Command("program.exe", `x`)
|
||||
¹: native commands like grep, git grep, ripgrep
|
||||
²: interpreted as a grouping quote, affects argument parser and gets removed from the result
|
||||
|
||||
[CommandLineToArgvW]: https://docs.microsoft.com/en-gb/windows/win32/api/shellapi/nf-shellapi-commandlinetoargvw#remarks
|
||||
[NativeCallsFromPowershell]: https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_parsing?view=powershell-7.1#passing-arguments-that-contain-quote-characters
|
||||
*/
|
||||
|
||||
// 1) working examples
|
||||
|
||||
{give{`Get-Content {}`, ``, newItems(`C:\test.txt`)}, want{output: `Get-Content 'C:\test.txt'`}},
|
||||
{give{`rg -- "package" {}`, ``, newItems(`.\test.go`)}, want{output: `rg -- "package" '.\test.go'`}},
|
||||
|
||||
// example of escaping single quotes
|
||||
{give{`rg -- {}`, ``, newItems(`'foobar'`)}, want{output: `rg -- '''foobar'''`}},
|
||||
|
||||
// chaining powershells
|
||||
{give{`powershell -NoProfile -Command {}`, ``, newItems(`cat "C:\test.txt"`)}, want{output: `powershell -NoProfile -Command 'cat \"C:\test.txt\"'`}},
|
||||
|
||||
// 2) problematic examples
|
||||
// (not necessarily unexpected)
|
||||
|
||||
// looking for a path string will only work with escaped backslashes
|
||||
{give{`rg -- {}`, ``, newItems(`C:\test.txt`)}, want{output: `rg -- 'C:\test.txt'`}},
|
||||
// looking for a literal double quote will only work with triple escaped double quotes
|
||||
{give{`rg -- {}`, ``, newItems(`"C:\test.txt"`)}, want{output: `rg -- '\"C:\test.txt\"'`}},
|
||||
|
||||
// Get-Content (i.e. cat alias) is parsing `"` as a part of the file path, returns an error:
|
||||
// Get-Content : Cannot find drive. A drive with the name '"C:' does not exist.
|
||||
{give{`cat {}`, ``, newItems(`"C:\test.txt"`)}, want{output: `cat '\"C:\test.txt\"'`}},
|
||||
|
||||
// the "file" flag in the pattern won't create *.ps1 file so the powershell will offload this "unknown" filetype
|
||||
// to explorer, which will prompt user to pick editing program for the fzf-preview file
|
||||
// the temp file contains: `cat "C:\test.txt"`
|
||||
// TODO this should actually work
|
||||
{give{`powershell -NoProfile -Command {f}`, ``, newItems(`cat "C:\test.txt"`)}, want{match: `^powershell -NoProfile -Command .*\fzf-preview-[0-9]{9}$`}},
|
||||
}
|
||||
|
||||
// to force powershell-style escaping we temporarily set environment variable that fzf honors
|
||||
shellBackup := os.Getenv("SHELL")
|
||||
os.Setenv("SHELL", "powershell")
|
||||
testCommands(t, tests)
|
||||
os.Setenv("SHELL", shellBackup)
|
||||
}
|
||||
|
||||
/*
|
||||
Test typical valid placeholders and parsing of them.
|
||||
|
||||
Also since the parser assumes the input is matched with `placeholder` regex,
|
||||
the regex is tested here as well.
|
||||
*/
|
||||
func TestParsePlaceholder(t *testing.T) {
|
||||
// give, want pairs
|
||||
templates := map[string]string{
|
||||
// I. item type placeholder
|
||||
`{}`: `{}`,
|
||||
`{+}`: `{+}`,
|
||||
`{n}`: `{n}`,
|
||||
`{+n}`: `{+n}`,
|
||||
`{f}`: `{f}`,
|
||||
`{+nf}`: `{+nf}`,
|
||||
|
||||
// II. token type placeholders
|
||||
`{..}`: `{..}`,
|
||||
`{1..}`: `{1..}`,
|
||||
`{..2}`: `{..2}`,
|
||||
`{1..2}`: `{1..2}`,
|
||||
`{-2..-1}`: `{-2..-1}`,
|
||||
// shorthand for x..x range
|
||||
`{1}`: `{1}`,
|
||||
`{1..1}`: `{1..1}`,
|
||||
`{-6}`: `{-6}`,
|
||||
// multiple ranges
|
||||
`{1,2}`: `{1,2}`,
|
||||
`{1,2,4}`: `{1,2,4}`,
|
||||
`{1,2..4}`: `{1,2..4}`,
|
||||
`{1..2,-4..-3}`: `{1..2,-4..-3}`,
|
||||
// flags
|
||||
`{+1}`: `{+1}`,
|
||||
`{+-1}`: `{+-1}`,
|
||||
`{s1}`: `{s1}`,
|
||||
`{f1}`: `{f1}`,
|
||||
`{+s1..2}`: `{+s1..2}`,
|
||||
`{+sf1..2}`: `{+sf1..2}`,
|
||||
|
||||
// III. query type placeholder
|
||||
// query flag is not removed after parsing, so it gets doubled
|
||||
// while the double q is invalid, it is useful here for testing purposes
|
||||
`{q}`: `{qq}`,
|
||||
|
||||
// IV. escaping placeholder
|
||||
`\{}`: `{}`,
|
||||
`\{++}`: `{++}`,
|
||||
`{++}`: `{+}`,
|
||||
}
|
||||
|
||||
for giveTemplate, wantTemplate := range templates {
|
||||
if !placeholder.MatchString(giveTemplate) {
|
||||
t.Errorf(`given placeholder %s does not match placeholder regex, so attempt to parse it is unexpected`, giveTemplate)
|
||||
continue
|
||||
}
|
||||
|
||||
_, placeholderWithoutFlags, flags := parsePlaceholder(giveTemplate)
|
||||
gotTemplate := placeholderWithoutFlags[:1] + flags.encodePlaceholder() + placeholderWithoutFlags[1:]
|
||||
|
||||
if gotTemplate != wantTemplate {
|
||||
t.Errorf(`parsed placeholder "%s" into "%s", but want "%s"`, giveTemplate, gotTemplate, wantTemplate)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/* utilities section */
|
||||
|
||||
// Item represents one line in fzf UI. Usually it is relative path to files and folders.
|
||||
func newItem(str string) *Item {
|
||||
bytes := []byte(str)
|
||||
trimmed, _, _ := extractColor(str, nil, nil)
|
||||
return &Item{origText: &bytes, text: util.ToChars([]byte(trimmed))}
|
||||
}
|
||||
|
||||
// Functions tested in this file require array of items (allItems). The array needs
|
||||
// to consist of at least two nils. This is helper function.
|
||||
func newItems(str ...string) []*Item {
|
||||
result := make([]*Item, util.Max(len(str), 2))
|
||||
for i, s := range str {
|
||||
result[i] = newItem(s)
|
||||
}
|
||||
return result
|
||||
}
|
||||
|
||||
// (for logging purposes)
|
||||
func (item *Item) String() string {
|
||||
return item.AsString(true)
|
||||
}
|
||||
|
||||
// Helper function to parse, execute and convert "text/template" to string. Panics on error.
|
||||
func templateToString(format string, data interface{}) string {
|
||||
bb := &bytes.Buffer{}
|
||||
|
||||
err := template.Must(template.New("").Parse(format)).Execute(bb, data)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
return bb.String()
|
||||
}
|
||||
|
||||
// ad hoc types for test cases
|
||||
type give struct {
|
||||
template string
|
||||
query string
|
||||
allItems []*Item
|
||||
}
|
||||
type want struct {
|
||||
/*
|
||||
Unix:
|
||||
The `want.output` string is supposed to be formatted for evaluation by
|
||||
`sh -c command` system call.
|
||||
|
||||
Windows:
|
||||
The `want.output` string is supposed to be formatted for evaluation by
|
||||
`cmd.exe /s /c "command"` system call. The `/s` switch enables so called old
|
||||
behaviour, which is more favourable for nesting (possibly escaped)
|
||||
special characters. This is the relevant section of `help cmd`:
|
||||
|
||||
...old behavior is to see if the first character is
|
||||
a quote character and if so, strip the leading character and
|
||||
remove the last quote character on the command line, preserving
|
||||
any text after the last quote character.
|
||||
*/
|
||||
output string // literal output
|
||||
match string // output is matched against this regex (when output is empty string)
|
||||
}
|
||||
type testCase struct {
|
||||
give
|
||||
want
|
||||
}
|
||||
|
||||
func testCommands(t *testing.T, tests []testCase) {
|
||||
// common test parameters
|
||||
delim := "\t"
|
||||
delimiter := Delimiter{str: &delim}
|
||||
printsep := ""
|
||||
stripAnsi := false
|
||||
forcePlus := false
|
||||
|
||||
// evaluate the test cases
|
||||
for idx, test := range tests {
|
||||
gotOutput := replacePlaceholder(
|
||||
test.give.template, stripAnsi, delimiter, printsep, forcePlus,
|
||||
test.give.query,
|
||||
test.give.allItems)
|
||||
switch {
|
||||
case test.want.output != "":
|
||||
if gotOutput != test.want.output {
|
||||
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
||||
idx,
|
||||
test.give.template, test.give.query, test.give.allItems,
|
||||
gotOutput, test.want.output)
|
||||
}
|
||||
case test.want.match != "":
|
||||
wantMatch := strings.ReplaceAll(test.want.match, `\`, `\\`)
|
||||
wantRegex := regexp.MustCompile(wantMatch)
|
||||
if !wantRegex.MatchString(gotOutput) {
|
||||
t.Errorf("tests[%v]:\ngave{\n\ttemplate: '%s',\n\tquery: '%s',\n\tallItems: %s}\nand got '%s',\nbut want '%s'",
|
||||
idx,
|
||||
test.give.template, test.give.query, test.give.allItems,
|
||||
gotOutput, test.want.match)
|
||||
}
|
||||
default:
|
||||
t.Errorf("tests[%v]: test case does not describe 'want' property", idx)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// naive encoder of placeholder flags
|
||||
func (flags placeholderFlags) encodePlaceholder() string {
|
||||
encoded := ""
|
||||
if flags.plus {
|
||||
encoded += "+"
|
||||
}
|
||||
if flags.preserveSpace {
|
||||
encoded += "s"
|
||||
}
|
||||
if flags.number {
|
||||
encoded += "n"
|
||||
}
|
||||
if flags.file {
|
||||
encoded += "f"
|
||||
}
|
||||
if flags.query {
|
||||
encoded += "q"
|
||||
}
|
||||
return encoded
|
||||
}
|
||||
|
||||
// can be replaced with os.ReadFile() in go 1.16+
|
||||
func readFile(path string) ([]byte, error) {
|
||||
file, err := os.Open(path)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
defer file.Close()
|
||||
|
||||
data := make([]byte, 0, 128)
|
||||
for {
|
||||
if len(data) >= cap(data) {
|
||||
d := append(data[:cap(data)], 0)
|
||||
data = d[:len(data)]
|
||||
}
|
||||
|
||||
n, err := file.Read(data[len(data):cap(data)])
|
||||
data = data[:len(data)+n]
|
||||
if err != nil {
|
||||
if err == io.EOF {
|
||||
err = nil
|
||||
}
|
||||
return data, err
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -1,26 +0,0 @@
|
||||
// +build !windows
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"os"
|
||||
"os/signal"
|
||||
"strings"
|
||||
"syscall"
|
||||
)
|
||||
|
||||
func notifyOnResize(resizeChan chan<- os.Signal) {
|
||||
signal.Notify(resizeChan, syscall.SIGWINCH)
|
||||
}
|
||||
|
||||
func notifyStop(p *os.Process) {
|
||||
p.Signal(syscall.SIGSTOP)
|
||||
}
|
||||
|
||||
func notifyOnCont(resizeChan chan<- os.Signal) {
|
||||
signal.Notify(resizeChan, syscall.SIGCONT)
|
||||
}
|
||||
|
||||
func quoteEntry(entry string) string {
|
||||
return "'" + strings.Replace(entry, "'", "'\\''", -1) + "'"
|
||||
}
|
||||
@ -1,45 +0,0 @@
|
||||
// +build windows
|
||||
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"os"
|
||||
"regexp"
|
||||
"strings"
|
||||
)
|
||||
|
||||
func notifyOnResize(resizeChan chan<- os.Signal) {
|
||||
// TODO
|
||||
}
|
||||
|
||||
func notifyStop(p *os.Process) {
|
||||
// NOOP
|
||||
}
|
||||
|
||||
func notifyOnCont(resizeChan chan<- os.Signal) {
|
||||
// NOOP
|
||||
}
|
||||
|
||||
func quoteEntry(entry string) string {
|
||||
shell := os.Getenv("SHELL")
|
||||
if len(shell) == 0 {
|
||||
shell = "cmd"
|
||||
}
|
||||
|
||||
if strings.Contains(shell, "cmd") {
|
||||
// backslash escaping is done here for applications
|
||||
// (see ripgrep test case in terminal_test.go#TestWindowsCommands)
|
||||
escaped := strings.Replace(entry, `\`, `\\`, -1)
|
||||
escaped = `"` + strings.Replace(escaped, `"`, `\"`, -1) + `"`
|
||||
// caret is the escape character for cmd shell
|
||||
r, _ := regexp.Compile(`[&|<>()@^%!"]`)
|
||||
return r.ReplaceAllStringFunc(escaped, func(match string) string {
|
||||
return "^" + match
|
||||
})
|
||||
} else if strings.Contains(shell, "pwsh") || strings.Contains(shell, "powershell") {
|
||||
escaped := strings.Replace(entry, `"`, `\"`, -1)
|
||||
return "'" + strings.Replace(escaped, "'", "''", -1) + "'"
|
||||
} else {
|
||||
return "'" + strings.Replace(entry, "'", "'\\''", -1) + "'"
|
||||
}
|
||||
}
|
||||
@ -1,253 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"strings"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
const rangeEllipsis = 0
|
||||
|
||||
// Range represents nth-expression
|
||||
type Range struct {
|
||||
begin int
|
||||
end int
|
||||
}
|
||||
|
||||
// Token contains the tokenized part of the strings and its prefix length
|
||||
type Token struct {
|
||||
text *util.Chars
|
||||
prefixLength int32
|
||||
}
|
||||
|
||||
// String returns the string representation of a Token.
|
||||
func (t Token) String() string {
|
||||
return fmt.Sprintf("Token{text: %s, prefixLength: %d}", t.text, t.prefixLength)
|
||||
}
|
||||
|
||||
// Delimiter for tokenizing the input
|
||||
type Delimiter struct {
|
||||
regex *regexp.Regexp
|
||||
str *string
|
||||
}
|
||||
|
||||
// String returns the string representation of a Delimiter.
|
||||
func (d Delimiter) String() string {
|
||||
return fmt.Sprintf("Delimiter{regex: %v, str: &%q}", d.regex, *d.str)
|
||||
}
|
||||
|
||||
func newRange(begin int, end int) Range {
|
||||
if begin == 1 {
|
||||
begin = rangeEllipsis
|
||||
}
|
||||
if end == -1 {
|
||||
end = rangeEllipsis
|
||||
}
|
||||
return Range{begin, end}
|
||||
}
|
||||
|
||||
// ParseRange parses nth-expression and returns the corresponding Range object
|
||||
func ParseRange(str *string) (Range, bool) {
|
||||
if (*str) == ".." {
|
||||
return newRange(rangeEllipsis, rangeEllipsis), true
|
||||
} else if strings.HasPrefix(*str, "..") {
|
||||
end, err := strconv.Atoi((*str)[2:])
|
||||
if err != nil || end == 0 {
|
||||
return Range{}, false
|
||||
}
|
||||
return newRange(rangeEllipsis, end), true
|
||||
} else if strings.HasSuffix(*str, "..") {
|
||||
begin, err := strconv.Atoi((*str)[:len(*str)-2])
|
||||
if err != nil || begin == 0 {
|
||||
return Range{}, false
|
||||
}
|
||||
return newRange(begin, rangeEllipsis), true
|
||||
} else if strings.Contains(*str, "..") {
|
||||
ns := strings.Split(*str, "..")
|
||||
if len(ns) != 2 {
|
||||
return Range{}, false
|
||||
}
|
||||
begin, err1 := strconv.Atoi(ns[0])
|
||||
end, err2 := strconv.Atoi(ns[1])
|
||||
if err1 != nil || err2 != nil || begin == 0 || end == 0 {
|
||||
return Range{}, false
|
||||
}
|
||||
return newRange(begin, end), true
|
||||
}
|
||||
|
||||
n, err := strconv.Atoi(*str)
|
||||
if err != nil || n == 0 {
|
||||
return Range{}, false
|
||||
}
|
||||
return newRange(n, n), true
|
||||
}
|
||||
|
||||
func withPrefixLengths(tokens []string, begin int) []Token {
|
||||
ret := make([]Token, len(tokens))
|
||||
|
||||
prefixLength := begin
|
||||
for idx := range tokens {
|
||||
chars := util.ToChars([]byte(tokens[idx]))
|
||||
ret[idx] = Token{&chars, int32(prefixLength)}
|
||||
prefixLength += chars.Length()
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
const (
|
||||
awkNil = iota
|
||||
awkBlack
|
||||
awkWhite
|
||||
)
|
||||
|
||||
func awkTokenizer(input string) ([]string, int) {
|
||||
// 9, 32
|
||||
ret := []string{}
|
||||
prefixLength := 0
|
||||
state := awkNil
|
||||
begin := 0
|
||||
end := 0
|
||||
for idx := 0; idx < len(input); idx++ {
|
||||
r := input[idx]
|
||||
white := r == 9 || r == 32
|
||||
switch state {
|
||||
case awkNil:
|
||||
if white {
|
||||
prefixLength++
|
||||
} else {
|
||||
state, begin, end = awkBlack, idx, idx+1
|
||||
}
|
||||
case awkBlack:
|
||||
end = idx + 1
|
||||
if white {
|
||||
state = awkWhite
|
||||
}
|
||||
case awkWhite:
|
||||
if white {
|
||||
end = idx + 1
|
||||
} else {
|
||||
ret = append(ret, input[begin:end])
|
||||
state, begin, end = awkBlack, idx, idx+1
|
||||
}
|
||||
}
|
||||
}
|
||||
if begin < end {
|
||||
ret = append(ret, input[begin:end])
|
||||
}
|
||||
return ret, prefixLength
|
||||
}
|
||||
|
||||
// Tokenize tokenizes the given string with the delimiter
|
||||
func Tokenize(text string, delimiter Delimiter) []Token {
|
||||
if delimiter.str == nil && delimiter.regex == nil {
|
||||
// AWK-style (\S+\s*)
|
||||
tokens, prefixLength := awkTokenizer(text)
|
||||
return withPrefixLengths(tokens, prefixLength)
|
||||
}
|
||||
|
||||
if delimiter.str != nil {
|
||||
return withPrefixLengths(strings.SplitAfter(text, *delimiter.str), 0)
|
||||
}
|
||||
|
||||
// FIXME performance
|
||||
var tokens []string
|
||||
if delimiter.regex != nil {
|
||||
for len(text) > 0 {
|
||||
loc := delimiter.regex.FindStringIndex(text)
|
||||
if len(loc) < 2 {
|
||||
loc = []int{0, len(text)}
|
||||
}
|
||||
last := util.Max(loc[1], 1)
|
||||
tokens = append(tokens, text[:last])
|
||||
text = text[last:]
|
||||
}
|
||||
}
|
||||
return withPrefixLengths(tokens, 0)
|
||||
}
|
||||
|
||||
func joinTokens(tokens []Token) string {
|
||||
var output bytes.Buffer
|
||||
for _, token := range tokens {
|
||||
output.WriteString(token.text.ToString())
|
||||
}
|
||||
return output.String()
|
||||
}
|
||||
|
||||
// Transform is used to transform the input when --with-nth option is given
|
||||
func Transform(tokens []Token, withNth []Range) []Token {
|
||||
transTokens := make([]Token, len(withNth))
|
||||
numTokens := len(tokens)
|
||||
for idx, r := range withNth {
|
||||
parts := []*util.Chars{}
|
||||
minIdx := 0
|
||||
if r.begin == r.end {
|
||||
idx := r.begin
|
||||
if idx == rangeEllipsis {
|
||||
chars := util.ToChars([]byte(joinTokens(tokens)))
|
||||
parts = append(parts, &chars)
|
||||
} else {
|
||||
if idx < 0 {
|
||||
idx += numTokens + 1
|
||||
}
|
||||
if idx >= 1 && idx <= numTokens {
|
||||
minIdx = idx - 1
|
||||
parts = append(parts, tokens[idx-1].text)
|
||||
}
|
||||
}
|
||||
} else {
|
||||
var begin, end int
|
||||
if r.begin == rangeEllipsis { // ..N
|
||||
begin, end = 1, r.end
|
||||
if end < 0 {
|
||||
end += numTokens + 1
|
||||
}
|
||||
} else if r.end == rangeEllipsis { // N..
|
||||
begin, end = r.begin, numTokens
|
||||
if begin < 0 {
|
||||
begin += numTokens + 1
|
||||
}
|
||||
} else {
|
||||
begin, end = r.begin, r.end
|
||||
if begin < 0 {
|
||||
begin += numTokens + 1
|
||||
}
|
||||
if end < 0 {
|
||||
end += numTokens + 1
|
||||
}
|
||||
}
|
||||
minIdx = util.Max(0, begin-1)
|
||||
for idx := begin; idx <= end; idx++ {
|
||||
if idx >= 1 && idx <= numTokens {
|
||||
parts = append(parts, tokens[idx-1].text)
|
||||
}
|
||||
}
|
||||
}
|
||||
// Merge multiple parts
|
||||
var merged util.Chars
|
||||
switch len(parts) {
|
||||
case 0:
|
||||
merged = util.ToChars([]byte{})
|
||||
case 1:
|
||||
merged = *parts[0]
|
||||
default:
|
||||
var output bytes.Buffer
|
||||
for _, part := range parts {
|
||||
output.WriteString(part.ToString())
|
||||
}
|
||||
merged = util.ToChars(output.Bytes())
|
||||
}
|
||||
|
||||
var prefixLength int32
|
||||
if minIdx < numTokens {
|
||||
prefixLength = tokens[minIdx].prefixLength
|
||||
} else {
|
||||
prefixLength = 0
|
||||
}
|
||||
transTokens[idx] = Token{&merged, prefixLength}
|
||||
}
|
||||
return transTokens
|
||||
}
|
||||
@ -1,112 +0,0 @@
|
||||
package fzf
|
||||
|
||||
import (
|
||||
"testing"
|
||||
)
|
||||
|
||||
func TestParseRange(t *testing.T) {
|
||||
{
|
||||
i := ".."
|
||||
r, _ := ParseRange(&i)
|
||||
if r.begin != rangeEllipsis || r.end != rangeEllipsis {
|
||||
t.Errorf("%v", r)
|
||||
}
|
||||
}
|
||||
{
|
||||
i := "3.."
|
||||
r, _ := ParseRange(&i)
|
||||
if r.begin != 3 || r.end != rangeEllipsis {
|
||||
t.Errorf("%v", r)
|
||||
}
|
||||
}
|
||||
{
|
||||
i := "3..5"
|
||||
r, _ := ParseRange(&i)
|
||||
if r.begin != 3 || r.end != 5 {
|
||||
t.Errorf("%v", r)
|
||||
}
|
||||
}
|
||||
{
|
||||
i := "-3..-5"
|
||||
r, _ := ParseRange(&i)
|
||||
if r.begin != -3 || r.end != -5 {
|
||||
t.Errorf("%v", r)
|
||||
}
|
||||
}
|
||||
{
|
||||
i := "3"
|
||||
r, _ := ParseRange(&i)
|
||||
if r.begin != 3 || r.end != 3 {
|
||||
t.Errorf("%v", r)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestTokenize(t *testing.T) {
|
||||
// AWK-style
|
||||
input := " abc: def: ghi "
|
||||
tokens := Tokenize(input, Delimiter{})
|
||||
if tokens[0].text.ToString() != "abc: " || tokens[0].prefixLength != 2 {
|
||||
t.Errorf("%s", tokens)
|
||||
}
|
||||
|
||||
// With delimiter
|
||||
tokens = Tokenize(input, delimiterRegexp(":"))
|
||||
if tokens[0].text.ToString() != " abc:" || tokens[0].prefixLength != 0 {
|
||||
t.Error(tokens[0].text.ToString(), tokens[0].prefixLength)
|
||||
}
|
||||
|
||||
// With delimiter regex
|
||||
tokens = Tokenize(input, delimiterRegexp("\\s+"))
|
||||
if tokens[0].text.ToString() != " " || tokens[0].prefixLength != 0 ||
|
||||
tokens[1].text.ToString() != "abc: " || tokens[1].prefixLength != 2 ||
|
||||
tokens[2].text.ToString() != "def: " || tokens[2].prefixLength != 8 ||
|
||||
tokens[3].text.ToString() != "ghi " || tokens[3].prefixLength != 14 {
|
||||
t.Errorf("%s", tokens)
|
||||
}
|
||||
}
|
||||
|
||||
func TestTransform(t *testing.T) {
|
||||
input := " abc: def: ghi: jkl"
|
||||
{
|
||||
tokens := Tokenize(input, Delimiter{})
|
||||
{
|
||||
ranges := splitNth("1,2,3")
|
||||
tx := Transform(tokens, ranges)
|
||||
if joinTokens(tx) != "abc: def: ghi: " {
|
||||
t.Errorf("%s", tx)
|
||||
}
|
||||
}
|
||||
{
|
||||
ranges := splitNth("1..2,3,2..,1")
|
||||
tx := Transform(tokens, ranges)
|
||||
if string(joinTokens(tx)) != "abc: def: ghi: def: ghi: jklabc: " ||
|
||||
len(tx) != 4 ||
|
||||
tx[0].text.ToString() != "abc: def: " || tx[0].prefixLength != 2 ||
|
||||
tx[1].text.ToString() != "ghi: " || tx[1].prefixLength != 14 ||
|
||||
tx[2].text.ToString() != "def: ghi: jkl" || tx[2].prefixLength != 8 ||
|
||||
tx[3].text.ToString() != "abc: " || tx[3].prefixLength != 2 {
|
||||
t.Errorf("%s", tx)
|
||||
}
|
||||
}
|
||||
}
|
||||
{
|
||||
tokens := Tokenize(input, delimiterRegexp(":"))
|
||||
{
|
||||
ranges := splitNth("1..2,3,2..,1")
|
||||
tx := Transform(tokens, ranges)
|
||||
if joinTokens(tx) != " abc: def: ghi: def: ghi: jkl abc:" ||
|
||||
len(tx) != 4 ||
|
||||
tx[0].text.ToString() != " abc: def:" || tx[0].prefixLength != 0 ||
|
||||
tx[1].text.ToString() != " ghi:" || tx[1].prefixLength != 12 ||
|
||||
tx[2].text.ToString() != " def: ghi: jkl" || tx[2].prefixLength != 6 ||
|
||||
tx[3].text.ToString() != " abc:" || tx[3].prefixLength != 0 {
|
||||
t.Errorf("%s", tx)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func TestTransformIndexOutOfBounds(t *testing.T) {
|
||||
Transform([]Token{}, splitNth("1"))
|
||||
}
|
||||
@ -1,46 +0,0 @@
|
||||
// +build !ncurses
|
||||
// +build !tcell
|
||||
// +build !windows
|
||||
|
||||
package tui
|
||||
|
||||
type Attr int32
|
||||
|
||||
func HasFullscreenRenderer() bool {
|
||||
return false
|
||||
}
|
||||
|
||||
func (a Attr) Merge(b Attr) Attr {
|
||||
return a | b
|
||||
}
|
||||
|
||||
const (
|
||||
AttrUndefined = Attr(0)
|
||||
AttrRegular = Attr(1 << 7)
|
||||
AttrClear = Attr(1 << 8)
|
||||
|
||||
Bold = Attr(1)
|
||||
Dim = Attr(1 << 1)
|
||||
Italic = Attr(1 << 2)
|
||||
Underline = Attr(1 << 3)
|
||||
Blink = Attr(1 << 4)
|
||||
Blink2 = Attr(1 << 5)
|
||||
Reverse = Attr(1 << 6)
|
||||
)
|
||||
|
||||
func (r *FullscreenRenderer) Init() {}
|
||||
func (r *FullscreenRenderer) Pause(bool) {}
|
||||
func (r *FullscreenRenderer) Resume(bool, bool) {}
|
||||
func (r *FullscreenRenderer) Clear() {}
|
||||
func (r *FullscreenRenderer) Refresh() {}
|
||||
func (r *FullscreenRenderer) Close() {}
|
||||
|
||||
func (r *FullscreenRenderer) GetChar() Event { return Event{} }
|
||||
func (r *FullscreenRenderer) MaxX() int { return 0 }
|
||||
func (r *FullscreenRenderer) MaxY() int { return 0 }
|
||||
|
||||
func (r *FullscreenRenderer) RefreshWindows(windows []Window) {}
|
||||
|
||||
func (r *FullscreenRenderer) NewWindow(top int, left int, width int, height int, preview bool, borderStyle BorderStyle) Window {
|
||||
return nil
|
||||
}
|
||||
@ -1,987 +0,0 @@
|
||||
package tui
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"os"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"strings"
|
||||
"time"
|
||||
"unicode/utf8"
|
||||
|
||||
"github.com/mattn/go-runewidth"
|
||||
"github.com/rivo/uniseg"
|
||||
|
||||
"golang.org/x/term"
|
||||
)
|
||||
|
||||
const (
|
||||
defaultWidth = 80
|
||||
defaultHeight = 24
|
||||
|
||||
defaultEscDelay = 100
|
||||
escPollInterval = 5
|
||||
offsetPollTries = 10
|
||||
maxInputBuffer = 10 * 1024
|
||||
)
|
||||
|
||||
const consoleDevice string = "/dev/tty"
|
||||
|
||||
var offsetRegexp *regexp.Regexp = regexp.MustCompile("(.*)\x1b\\[([0-9]+);([0-9]+)R")
|
||||
var offsetRegexpBegin *regexp.Regexp = regexp.MustCompile("^\x1b\\[[0-9]+;[0-9]+R")
|
||||
|
||||
func (r *LightRenderer) stderr(str string) {
|
||||
r.stderrInternal(str, true)
|
||||
}
|
||||
|
||||
// FIXME: Need better handling of non-displayable characters
|
||||
func (r *LightRenderer) stderrInternal(str string, allowNLCR bool) {
|
||||
bytes := []byte(str)
|
||||
runes := []rune{}
|
||||
for len(bytes) > 0 {
|
||||
r, sz := utf8.DecodeRune(bytes)
|
||||
nlcr := r == '\n' || r == '\r'
|
||||
if r >= 32 || r == '\x1b' || nlcr {
|
||||
if r == utf8.RuneError || nlcr && !allowNLCR {
|
||||
runes = append(runes, ' ')
|
||||
} else {
|
||||
runes = append(runes, r)
|
||||
}
|
||||
}
|
||||
bytes = bytes[sz:]
|
||||
}
|
||||
r.queued.WriteString(string(runes))
|
||||
}
|
||||
|
||||
func (r *LightRenderer) csi(code string) {
|
||||
r.stderr("\x1b[" + code)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) flush() {
|
||||
if r.queued.Len() > 0 {
|
||||
fmt.Fprint(os.Stderr, r.queued.String())
|
||||
r.queued.Reset()
|
||||
}
|
||||
}
|
||||
|
||||
// Light renderer
|
||||
type LightRenderer struct {
|
||||
theme *ColorTheme
|
||||
mouse bool
|
||||
forceBlack bool
|
||||
clearOnExit bool
|
||||
prevDownTime time.Time
|
||||
clickY []int
|
||||
ttyin *os.File
|
||||
buffer []byte
|
||||
origState *term.State
|
||||
width int
|
||||
height int
|
||||
yoffset int
|
||||
tabstop int
|
||||
escDelay int
|
||||
fullscreen bool
|
||||
upOneLine bool
|
||||
queued strings.Builder
|
||||
y int
|
||||
x int
|
||||
maxHeightFunc func(int) int
|
||||
|
||||
// Windows only
|
||||
ttyinChannel chan byte
|
||||
inHandle uintptr
|
||||
outHandle uintptr
|
||||
origStateInput uint32
|
||||
origStateOutput uint32
|
||||
}
|
||||
|
||||
type LightWindow struct {
|
||||
renderer *LightRenderer
|
||||
colored bool
|
||||
preview bool
|
||||
border BorderStyle
|
||||
top int
|
||||
left int
|
||||
width int
|
||||
height int
|
||||
posx int
|
||||
posy int
|
||||
tabstop int
|
||||
fg Color
|
||||
bg Color
|
||||
}
|
||||
|
||||
func NewLightRenderer(theme *ColorTheme, forceBlack bool, mouse bool, tabstop int, clearOnExit bool, fullscreen bool, maxHeightFunc func(int) int) Renderer {
|
||||
r := LightRenderer{
|
||||
theme: theme,
|
||||
forceBlack: forceBlack,
|
||||
mouse: mouse,
|
||||
clearOnExit: clearOnExit,
|
||||
ttyin: openTtyIn(),
|
||||
yoffset: 0,
|
||||
tabstop: tabstop,
|
||||
fullscreen: fullscreen,
|
||||
upOneLine: false,
|
||||
maxHeightFunc: maxHeightFunc}
|
||||
return &r
|
||||
}
|
||||
|
||||
func repeat(r rune, times int) string {
|
||||
if times > 0 {
|
||||
return strings.Repeat(string(r), times)
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
func atoi(s string, defaultValue int) int {
|
||||
value, err := strconv.Atoi(s)
|
||||
if err != nil {
|
||||
return defaultValue
|
||||
}
|
||||
return value
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Init() {
|
||||
r.escDelay = atoi(os.Getenv("ESCDELAY"), defaultEscDelay)
|
||||
|
||||
if err := r.initPlatform(); err != nil {
|
||||
errorExit(err.Error())
|
||||
}
|
||||
r.updateTerminalSize()
|
||||
initTheme(r.theme, r.defaultTheme(), r.forceBlack)
|
||||
|
||||
if r.fullscreen {
|
||||
r.smcup()
|
||||
} else {
|
||||
// We assume that --no-clear is used for repetitive relaunching of fzf.
|
||||
// So we do not clear the lower bottom of the screen.
|
||||
if r.clearOnExit {
|
||||
r.csi("J")
|
||||
}
|
||||
y, x := r.findOffset()
|
||||
r.mouse = r.mouse && y >= 0
|
||||
// When --no-clear is used for repetitive relaunching, there is a small
|
||||
// time frame between fzf processes where the user keystrokes are not
|
||||
// captured by either of fzf process which can cause x offset to be
|
||||
// increased and we're left with unwanted extra new line.
|
||||
if x > 0 && r.clearOnExit {
|
||||
r.upOneLine = true
|
||||
r.makeSpace()
|
||||
}
|
||||
for i := 1; i < r.MaxY(); i++ {
|
||||
r.makeSpace()
|
||||
}
|
||||
}
|
||||
|
||||
if r.mouse {
|
||||
r.csi("?1000h")
|
||||
}
|
||||
r.csi(fmt.Sprintf("%dA", r.MaxY()-1))
|
||||
r.csi("G")
|
||||
r.csi("K")
|
||||
if !r.clearOnExit && !r.fullscreen {
|
||||
r.csi("s")
|
||||
}
|
||||
if !r.fullscreen && r.mouse {
|
||||
r.yoffset, _ = r.findOffset()
|
||||
}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) makeSpace() {
|
||||
r.stderr("\n")
|
||||
r.csi("G")
|
||||
}
|
||||
|
||||
func (r *LightRenderer) move(y int, x int) {
|
||||
// w.csi("u")
|
||||
if r.y < y {
|
||||
r.csi(fmt.Sprintf("%dB", y-r.y))
|
||||
} else if r.y > y {
|
||||
r.csi(fmt.Sprintf("%dA", r.y-y))
|
||||
}
|
||||
r.stderr("\r")
|
||||
if x > 0 {
|
||||
r.csi(fmt.Sprintf("%dC", x))
|
||||
}
|
||||
r.y = y
|
||||
r.x = x
|
||||
}
|
||||
|
||||
func (r *LightRenderer) origin() {
|
||||
r.move(0, 0)
|
||||
}
|
||||
|
||||
func getEnv(name string, defaultValue int) int {
|
||||
env := os.Getenv(name)
|
||||
if len(env) == 0 {
|
||||
return defaultValue
|
||||
}
|
||||
return atoi(env, defaultValue)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) getBytes() []byte {
|
||||
return r.getBytesInternal(r.buffer, false)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) getBytesInternal(buffer []byte, nonblock bool) []byte {
|
||||
c, ok := r.getch(nonblock)
|
||||
if !nonblock && !ok {
|
||||
r.Close()
|
||||
errorExit("Failed to read " + consoleDevice)
|
||||
}
|
||||
|
||||
retries := 0
|
||||
if c == ESC.Int() || nonblock {
|
||||
retries = r.escDelay / escPollInterval
|
||||
}
|
||||
buffer = append(buffer, byte(c))
|
||||
|
||||
pc := c
|
||||
for {
|
||||
c, ok = r.getch(true)
|
||||
if !ok {
|
||||
if retries > 0 {
|
||||
retries--
|
||||
time.Sleep(escPollInterval * time.Millisecond)
|
||||
continue
|
||||
}
|
||||
break
|
||||
} else if c == ESC.Int() && pc != c {
|
||||
retries = r.escDelay / escPollInterval
|
||||
} else {
|
||||
retries = 0
|
||||
}
|
||||
buffer = append(buffer, byte(c))
|
||||
pc = c
|
||||
|
||||
// This should never happen under normal conditions,
|
||||
// so terminate fzf immediately.
|
||||
if len(buffer) > maxInputBuffer {
|
||||
r.Close()
|
||||
panic(fmt.Sprintf("Input buffer overflow (%d): %v", len(buffer), buffer))
|
||||
}
|
||||
}
|
||||
|
||||
return buffer
|
||||
}
|
||||
|
||||
func (r *LightRenderer) GetChar() Event {
|
||||
if len(r.buffer) == 0 {
|
||||
r.buffer = r.getBytes()
|
||||
}
|
||||
if len(r.buffer) == 0 {
|
||||
panic("Empty buffer")
|
||||
}
|
||||
|
||||
sz := 1
|
||||
defer func() {
|
||||
r.buffer = r.buffer[sz:]
|
||||
}()
|
||||
|
||||
switch r.buffer[0] {
|
||||
case CtrlC.Byte():
|
||||
return Event{CtrlC, 0, nil}
|
||||
case CtrlG.Byte():
|
||||
return Event{CtrlG, 0, nil}
|
||||
case CtrlQ.Byte():
|
||||
return Event{CtrlQ, 0, nil}
|
||||
case 127:
|
||||
return Event{BSpace, 0, nil}
|
||||
case 0:
|
||||
return Event{CtrlSpace, 0, nil}
|
||||
case 28:
|
||||
return Event{CtrlBackSlash, 0, nil}
|
||||
case 29:
|
||||
return Event{CtrlRightBracket, 0, nil}
|
||||
case 30:
|
||||
return Event{CtrlCaret, 0, nil}
|
||||
case 31:
|
||||
return Event{CtrlSlash, 0, nil}
|
||||
case ESC.Byte():
|
||||
ev := r.escSequence(&sz)
|
||||
// Second chance
|
||||
if ev.Type == Invalid {
|
||||
r.buffer = r.getBytes()
|
||||
ev = r.escSequence(&sz)
|
||||
}
|
||||
return ev
|
||||
}
|
||||
|
||||
// CTRL-A ~ CTRL-Z
|
||||
if r.buffer[0] <= CtrlZ.Byte() {
|
||||
return Event{EventType(r.buffer[0]), 0, nil}
|
||||
}
|
||||
char, rsz := utf8.DecodeRune(r.buffer)
|
||||
if char == utf8.RuneError {
|
||||
return Event{ESC, 0, nil}
|
||||
}
|
||||
sz = rsz
|
||||
return Event{Rune, char, nil}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) escSequence(sz *int) Event {
|
||||
if len(r.buffer) < 2 {
|
||||
return Event{ESC, 0, nil}
|
||||
}
|
||||
|
||||
loc := offsetRegexpBegin.FindIndex(r.buffer)
|
||||
if loc != nil && loc[0] == 0 {
|
||||
*sz = loc[1]
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
|
||||
*sz = 2
|
||||
if r.buffer[1] >= 1 && r.buffer[1] <= 'z'-'a'+1 {
|
||||
return CtrlAltKey(rune(r.buffer[1] + 'a' - 1))
|
||||
}
|
||||
alt := false
|
||||
if len(r.buffer) > 2 && r.buffer[1] == ESC.Byte() {
|
||||
r.buffer = r.buffer[1:]
|
||||
alt = true
|
||||
}
|
||||
switch r.buffer[1] {
|
||||
case ESC.Byte():
|
||||
return Event{ESC, 0, nil}
|
||||
case 127:
|
||||
return Event{AltBS, 0, nil}
|
||||
case '[', 'O':
|
||||
if len(r.buffer) < 3 {
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
*sz = 3
|
||||
switch r.buffer[2] {
|
||||
case 'D':
|
||||
if alt {
|
||||
return Event{AltLeft, 0, nil}
|
||||
}
|
||||
return Event{Left, 0, nil}
|
||||
case 'C':
|
||||
if alt {
|
||||
// Ugh..
|
||||
return Event{AltRight, 0, nil}
|
||||
}
|
||||
return Event{Right, 0, nil}
|
||||
case 'B':
|
||||
if alt {
|
||||
return Event{AltDown, 0, nil}
|
||||
}
|
||||
return Event{Down, 0, nil}
|
||||
case 'A':
|
||||
if alt {
|
||||
return Event{AltUp, 0, nil}
|
||||
}
|
||||
return Event{Up, 0, nil}
|
||||
case 'Z':
|
||||
return Event{BTab, 0, nil}
|
||||
case 'H':
|
||||
return Event{Home, 0, nil}
|
||||
case 'F':
|
||||
return Event{End, 0, nil}
|
||||
case 'M':
|
||||
return r.mouseSequence(sz)
|
||||
case 'P':
|
||||
return Event{F1, 0, nil}
|
||||
case 'Q':
|
||||
return Event{F2, 0, nil}
|
||||
case 'R':
|
||||
return Event{F3, 0, nil}
|
||||
case 'S':
|
||||
return Event{F4, 0, nil}
|
||||
case '1', '2', '3', '4', '5', '6':
|
||||
if len(r.buffer) < 4 {
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
*sz = 4
|
||||
switch r.buffer[2] {
|
||||
case '2':
|
||||
if r.buffer[3] == '~' {
|
||||
return Event{Insert, 0, nil}
|
||||
}
|
||||
if len(r.buffer) > 4 && r.buffer[4] == '~' {
|
||||
*sz = 5
|
||||
switch r.buffer[3] {
|
||||
case '0':
|
||||
return Event{F9, 0, nil}
|
||||
case '1':
|
||||
return Event{F10, 0, nil}
|
||||
case '3':
|
||||
return Event{F11, 0, nil}
|
||||
case '4':
|
||||
return Event{F12, 0, nil}
|
||||
}
|
||||
}
|
||||
// Bracketed paste mode: \e[200~ ... \e[201~
|
||||
if len(r.buffer) > 5 && r.buffer[3] == '0' && (r.buffer[4] == '0' || r.buffer[4] == '1') && r.buffer[5] == '~' {
|
||||
// Immediately discard the sequence from the buffer and reread input
|
||||
r.buffer = r.buffer[6:]
|
||||
*sz = 0
|
||||
return r.GetChar()
|
||||
}
|
||||
return Event{Invalid, 0, nil} // INS
|
||||
case '3':
|
||||
return Event{Del, 0, nil}
|
||||
case '4':
|
||||
return Event{End, 0, nil}
|
||||
case '5':
|
||||
return Event{PgUp, 0, nil}
|
||||
case '6':
|
||||
return Event{PgDn, 0, nil}
|
||||
case '1':
|
||||
switch r.buffer[3] {
|
||||
case '~':
|
||||
return Event{Home, 0, nil}
|
||||
case '1', '2', '3', '4', '5', '7', '8', '9':
|
||||
if len(r.buffer) == 5 && r.buffer[4] == '~' {
|
||||
*sz = 5
|
||||
switch r.buffer[3] {
|
||||
case '1':
|
||||
return Event{F1, 0, nil}
|
||||
case '2':
|
||||
return Event{F2, 0, nil}
|
||||
case '3':
|
||||
return Event{F3, 0, nil}
|
||||
case '4':
|
||||
return Event{F4, 0, nil}
|
||||
case '5':
|
||||
return Event{F5, 0, nil}
|
||||
case '7':
|
||||
return Event{F6, 0, nil}
|
||||
case '8':
|
||||
return Event{F7, 0, nil}
|
||||
case '9':
|
||||
return Event{F8, 0, nil}
|
||||
}
|
||||
}
|
||||
return Event{Invalid, 0, nil}
|
||||
case ';':
|
||||
if len(r.buffer) < 6 {
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
*sz = 6
|
||||
switch r.buffer[4] {
|
||||
case '1', '2', '3', '5':
|
||||
alt := r.buffer[4] == '3'
|
||||
altShift := r.buffer[4] == '1' && r.buffer[5] == '0'
|
||||
char := r.buffer[5]
|
||||
if altShift {
|
||||
if len(r.buffer) < 7 {
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
*sz = 7
|
||||
char = r.buffer[6]
|
||||
}
|
||||
switch char {
|
||||
case 'A':
|
||||
if alt {
|
||||
return Event{AltUp, 0, nil}
|
||||
}
|
||||
if altShift {
|
||||
return Event{AltSUp, 0, nil}
|
||||
}
|
||||
return Event{SUp, 0, nil}
|
||||
case 'B':
|
||||
if alt {
|
||||
return Event{AltDown, 0, nil}
|
||||
}
|
||||
if altShift {
|
||||
return Event{AltSDown, 0, nil}
|
||||
}
|
||||
return Event{SDown, 0, nil}
|
||||
case 'C':
|
||||
if alt {
|
||||
return Event{AltRight, 0, nil}
|
||||
}
|
||||
if altShift {
|
||||
return Event{AltSRight, 0, nil}
|
||||
}
|
||||
return Event{SRight, 0, nil}
|
||||
case 'D':
|
||||
if alt {
|
||||
return Event{AltLeft, 0, nil}
|
||||
}
|
||||
if altShift {
|
||||
return Event{AltSLeft, 0, nil}
|
||||
}
|
||||
return Event{SLeft, 0, nil}
|
||||
}
|
||||
} // r.buffer[4]
|
||||
} // r.buffer[3]
|
||||
} // r.buffer[2]
|
||||
} // r.buffer[2]
|
||||
} // r.buffer[1]
|
||||
rest := bytes.NewBuffer(r.buffer[1:])
|
||||
c, size, err := rest.ReadRune()
|
||||
if err == nil {
|
||||
*sz = 1 + size
|
||||
return AltKey(c)
|
||||
}
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) mouseSequence(sz *int) Event {
|
||||
if len(r.buffer) < 6 || !r.mouse {
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
*sz = 6
|
||||
switch r.buffer[3] {
|
||||
case 32, 34, 36, 40, 48, // mouse-down / shift / cmd / ctrl
|
||||
35, 39, 43, 51: // mouse-up / shift / cmd / ctrl
|
||||
mod := r.buffer[3] >= 36
|
||||
left := r.buffer[3] == 32
|
||||
down := r.buffer[3]%2 == 0
|
||||
x := int(r.buffer[4] - 33)
|
||||
y := int(r.buffer[5]-33) - r.yoffset
|
||||
double := false
|
||||
if down {
|
||||
now := time.Now()
|
||||
if !left { // Right double click is not allowed
|
||||
r.clickY = []int{}
|
||||
} else if now.Sub(r.prevDownTime) < doubleClickDuration {
|
||||
r.clickY = append(r.clickY, y)
|
||||
} else {
|
||||
r.clickY = []int{y}
|
||||
}
|
||||
r.prevDownTime = now
|
||||
} else {
|
||||
if len(r.clickY) > 1 && r.clickY[0] == r.clickY[1] &&
|
||||
time.Since(r.prevDownTime) < doubleClickDuration {
|
||||
double = true
|
||||
}
|
||||
}
|
||||
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, 0, left, down, double, mod}}
|
||||
case 96, 100, 104, 112, // scroll-up / shift / cmd / ctrl
|
||||
97, 101, 105, 113: // scroll-down / shift / cmd / ctrl
|
||||
mod := r.buffer[3] >= 100
|
||||
s := 1 - int(r.buffer[3]%2)*2
|
||||
x := int(r.buffer[4] - 33)
|
||||
y := int(r.buffer[5]-33) - r.yoffset
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, s, false, false, false, mod}}
|
||||
}
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) smcup() {
|
||||
r.csi("?1049h")
|
||||
}
|
||||
|
||||
func (r *LightRenderer) rmcup() {
|
||||
r.csi("?1049l")
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Pause(clear bool) {
|
||||
r.restoreTerminal()
|
||||
if clear {
|
||||
if r.fullscreen {
|
||||
r.rmcup()
|
||||
} else {
|
||||
r.smcup()
|
||||
r.csi("H")
|
||||
}
|
||||
r.flush()
|
||||
}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Resume(clear bool, sigcont bool) {
|
||||
r.setupTerminal()
|
||||
if clear {
|
||||
if r.fullscreen {
|
||||
r.smcup()
|
||||
} else {
|
||||
r.rmcup()
|
||||
}
|
||||
r.flush()
|
||||
} else if sigcont && !r.fullscreen && r.mouse {
|
||||
// NOTE: SIGCONT (Coming back from CTRL-Z):
|
||||
// It's highly likely that the offset we obtained at the beginning is
|
||||
// no longer correct, so we simply disable mouse input.
|
||||
r.csi("?1000l")
|
||||
r.mouse = false
|
||||
}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Clear() {
|
||||
if r.fullscreen {
|
||||
r.csi("H")
|
||||
}
|
||||
// r.csi("u")
|
||||
r.origin()
|
||||
r.csi("J")
|
||||
r.flush()
|
||||
}
|
||||
|
||||
func (r *LightRenderer) RefreshWindows(windows []Window) {
|
||||
r.flush()
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Refresh() {
|
||||
r.updateTerminalSize()
|
||||
}
|
||||
|
||||
func (r *LightRenderer) Close() {
|
||||
// r.csi("u")
|
||||
if r.clearOnExit {
|
||||
if r.fullscreen {
|
||||
r.rmcup()
|
||||
} else {
|
||||
r.origin()
|
||||
if r.upOneLine {
|
||||
r.csi("A")
|
||||
}
|
||||
r.csi("J")
|
||||
}
|
||||
} else if !r.fullscreen {
|
||||
r.csi("u")
|
||||
}
|
||||
if r.mouse {
|
||||
r.csi("?1000l")
|
||||
}
|
||||
r.flush()
|
||||
r.closePlatform()
|
||||
r.restoreTerminal()
|
||||
}
|
||||
|
||||
func (r *LightRenderer) MaxX() int {
|
||||
return r.width
|
||||
}
|
||||
|
||||
func (r *LightRenderer) MaxY() int {
|
||||
return r.height
|
||||
}
|
||||
|
||||
func (r *LightRenderer) NewWindow(top int, left int, width int, height int, preview bool, borderStyle BorderStyle) Window {
|
||||
w := &LightWindow{
|
||||
renderer: r,
|
||||
colored: r.theme.Colored,
|
||||
preview: preview,
|
||||
border: borderStyle,
|
||||
top: top,
|
||||
left: left,
|
||||
width: width,
|
||||
height: height,
|
||||
tabstop: r.tabstop,
|
||||
fg: colDefault,
|
||||
bg: colDefault}
|
||||
if preview {
|
||||
w.fg = r.theme.PreviewFg.Color
|
||||
w.bg = r.theme.PreviewBg.Color
|
||||
} else {
|
||||
w.fg = r.theme.Fg.Color
|
||||
w.bg = r.theme.Bg.Color
|
||||
}
|
||||
w.drawBorder()
|
||||
return w
|
||||
}
|
||||
|
||||
func (w *LightWindow) drawBorder() {
|
||||
switch w.border.shape {
|
||||
case BorderRounded, BorderSharp:
|
||||
w.drawBorderAround()
|
||||
case BorderHorizontal:
|
||||
w.drawBorderHorizontal(true, true)
|
||||
case BorderVertical:
|
||||
w.drawBorderVertical(true, true)
|
||||
case BorderTop:
|
||||
w.drawBorderHorizontal(true, false)
|
||||
case BorderBottom:
|
||||
w.drawBorderHorizontal(false, true)
|
||||
case BorderLeft:
|
||||
w.drawBorderVertical(true, false)
|
||||
case BorderRight:
|
||||
w.drawBorderVertical(false, true)
|
||||
}
|
||||
}
|
||||
|
||||
func (w *LightWindow) drawBorderHorizontal(top, bottom bool) {
|
||||
color := ColBorder
|
||||
if w.preview {
|
||||
color = ColPreviewBorder
|
||||
}
|
||||
if top {
|
||||
w.Move(0, 0)
|
||||
w.CPrint(color, repeat(w.border.horizontal, w.width))
|
||||
}
|
||||
if bottom {
|
||||
w.Move(w.height-1, 0)
|
||||
w.CPrint(color, repeat(w.border.horizontal, w.width))
|
||||
}
|
||||
}
|
||||
|
||||
func (w *LightWindow) drawBorderVertical(left, right bool) {
|
||||
width := w.width - 2
|
||||
if !left || !right {
|
||||
width++
|
||||
}
|
||||
color := ColBorder
|
||||
if w.preview {
|
||||
color = ColPreviewBorder
|
||||
}
|
||||
for y := 0; y < w.height; y++ {
|
||||
w.Move(y, 0)
|
||||
if left {
|
||||
w.CPrint(color, string(w.border.vertical))
|
||||
}
|
||||
w.CPrint(color, repeat(' ', width))
|
||||
if right {
|
||||
w.CPrint(color, string(w.border.vertical))
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (w *LightWindow) drawBorderAround() {
|
||||
w.Move(0, 0)
|
||||
color := ColBorder
|
||||
if w.preview {
|
||||
color = ColPreviewBorder
|
||||
}
|
||||
w.CPrint(color, string(w.border.topLeft)+repeat(w.border.horizontal, w.width-2)+string(w.border.topRight))
|
||||
for y := 1; y < w.height-1; y++ {
|
||||
w.Move(y, 0)
|
||||
w.CPrint(color, string(w.border.vertical))
|
||||
w.CPrint(color, repeat(' ', w.width-2))
|
||||
w.CPrint(color, string(w.border.vertical))
|
||||
}
|
||||
w.Move(w.height-1, 0)
|
||||
w.CPrint(color, string(w.border.bottomLeft)+repeat(w.border.horizontal, w.width-2)+string(w.border.bottomRight))
|
||||
}
|
||||
|
||||
func (w *LightWindow) csi(code string) {
|
||||
w.renderer.csi(code)
|
||||
}
|
||||
|
||||
func (w *LightWindow) stderrInternal(str string, allowNLCR bool) {
|
||||
w.renderer.stderrInternal(str, allowNLCR)
|
||||
}
|
||||
|
||||
func (w *LightWindow) Top() int {
|
||||
return w.top
|
||||
}
|
||||
|
||||
func (w *LightWindow) Left() int {
|
||||
return w.left
|
||||
}
|
||||
|
||||
func (w *LightWindow) Width() int {
|
||||
return w.width
|
||||
}
|
||||
|
||||
func (w *LightWindow) Height() int {
|
||||
return w.height
|
||||
}
|
||||
|
||||
func (w *LightWindow) Refresh() {
|
||||
}
|
||||
|
||||
func (w *LightWindow) Close() {
|
||||
}
|
||||
|
||||
func (w *LightWindow) X() int {
|
||||
return w.posx
|
||||
}
|
||||
|
||||
func (w *LightWindow) Y() int {
|
||||
return w.posy
|
||||
}
|
||||
|
||||
func (w *LightWindow) Enclose(y int, x int) bool {
|
||||
return x >= w.left && x < (w.left+w.width) &&
|
||||
y >= w.top && y < (w.top+w.height)
|
||||
}
|
||||
|
||||
func (w *LightWindow) Move(y int, x int) {
|
||||
w.posx = x
|
||||
w.posy = y
|
||||
|
||||
w.renderer.move(w.Top()+y, w.Left()+x)
|
||||
}
|
||||
|
||||
func (w *LightWindow) MoveAndClear(y int, x int) {
|
||||
w.Move(y, x)
|
||||
// We should not delete preview window on the right
|
||||
// csi("K")
|
||||
w.Print(repeat(' ', w.width-x))
|
||||
w.Move(y, x)
|
||||
}
|
||||
|
||||
func attrCodes(attr Attr) []string {
|
||||
codes := []string{}
|
||||
if (attr & AttrClear) > 0 {
|
||||
return codes
|
||||
}
|
||||
if (attr & Bold) > 0 {
|
||||
codes = append(codes, "1")
|
||||
}
|
||||
if (attr & Dim) > 0 {
|
||||
codes = append(codes, "2")
|
||||
}
|
||||
if (attr & Italic) > 0 {
|
||||
codes = append(codes, "3")
|
||||
}
|
||||
if (attr & Underline) > 0 {
|
||||
codes = append(codes, "4")
|
||||
}
|
||||
if (attr & Blink) > 0 {
|
||||
codes = append(codes, "5")
|
||||
}
|
||||
if (attr & Reverse) > 0 {
|
||||
codes = append(codes, "7")
|
||||
}
|
||||
return codes
|
||||
}
|
||||
|
||||
func colorCodes(fg Color, bg Color) []string {
|
||||
codes := []string{}
|
||||
appendCode := func(c Color, offset int) {
|
||||
if c == colDefault {
|
||||
return
|
||||
}
|
||||
if c.is24() {
|
||||
r := (c >> 16) & 0xff
|
||||
g := (c >> 8) & 0xff
|
||||
b := (c) & 0xff
|
||||
codes = append(codes, fmt.Sprintf("%d;2;%d;%d;%d", 38+offset, r, g, b))
|
||||
} else if c >= colBlack && c <= colWhite {
|
||||
codes = append(codes, fmt.Sprintf("%d", int(c)+30+offset))
|
||||
} else if c > colWhite && c < 16 {
|
||||
codes = append(codes, fmt.Sprintf("%d", int(c)+90+offset-8))
|
||||
} else if c >= 16 && c < 256 {
|
||||
codes = append(codes, fmt.Sprintf("%d;5;%d", 38+offset, c))
|
||||
}
|
||||
}
|
||||
appendCode(fg, 0)
|
||||
appendCode(bg, 10)
|
||||
return codes
|
||||
}
|
||||
|
||||
func (w *LightWindow) csiColor(fg Color, bg Color, attr Attr) bool {
|
||||
codes := append(attrCodes(attr), colorCodes(fg, bg)...)
|
||||
w.csi(";" + strings.Join(codes, ";") + "m")
|
||||
return len(codes) > 0
|
||||
}
|
||||
|
||||
func (w *LightWindow) Print(text string) {
|
||||
w.cprint2(colDefault, w.bg, AttrRegular, text)
|
||||
}
|
||||
|
||||
func cleanse(str string) string {
|
||||
return strings.Replace(str, "\x1b", "", -1)
|
||||
}
|
||||
|
||||
func (w *LightWindow) CPrint(pair ColorPair, text string) {
|
||||
w.csiColor(pair.Fg(), pair.Bg(), pair.Attr())
|
||||
w.stderrInternal(cleanse(text), false)
|
||||
w.csi("m")
|
||||
}
|
||||
|
||||
func (w *LightWindow) cprint2(fg Color, bg Color, attr Attr, text string) {
|
||||
if w.csiColor(fg, bg, attr) {
|
||||
defer w.csi("m")
|
||||
}
|
||||
w.stderrInternal(cleanse(text), false)
|
||||
}
|
||||
|
||||
type wrappedLine struct {
|
||||
text string
|
||||
displayWidth int
|
||||
}
|
||||
|
||||
func wrapLine(input string, prefixLength int, max int, tabstop int) []wrappedLine {
|
||||
lines := []wrappedLine{}
|
||||
width := 0
|
||||
line := ""
|
||||
gr := uniseg.NewGraphemes(input)
|
||||
for gr.Next() {
|
||||
rs := gr.Runes()
|
||||
str := string(rs)
|
||||
var w int
|
||||
if len(rs) == 1 && rs[0] == '\t' {
|
||||
w = tabstop - (prefixLength+width)%tabstop
|
||||
str = repeat(' ', w)
|
||||
} else {
|
||||
w = runewidth.StringWidth(str)
|
||||
}
|
||||
width += w
|
||||
|
||||
if prefixLength+width <= max {
|
||||
line += str
|
||||
} else {
|
||||
lines = append(lines, wrappedLine{string(line), width - w})
|
||||
line = str
|
||||
prefixLength = 0
|
||||
width = w
|
||||
}
|
||||
}
|
||||
lines = append(lines, wrappedLine{string(line), width})
|
||||
return lines
|
||||
}
|
||||
|
||||
func (w *LightWindow) fill(str string, onMove func()) FillReturn {
|
||||
allLines := strings.Split(str, "\n")
|
||||
for i, line := range allLines {
|
||||
lines := wrapLine(line, w.posx, w.width, w.tabstop)
|
||||
for j, wl := range lines {
|
||||
w.stderrInternal(wl.text, false)
|
||||
w.posx += wl.displayWidth
|
||||
|
||||
// Wrap line
|
||||
if j < len(lines)-1 || i < len(allLines)-1 {
|
||||
if w.posy+1 >= w.height {
|
||||
return FillSuspend
|
||||
}
|
||||
w.MoveAndClear(w.posy, w.posx)
|
||||
w.Move(w.posy+1, 0)
|
||||
onMove()
|
||||
}
|
||||
}
|
||||
}
|
||||
if w.posx+1 >= w.Width() {
|
||||
if w.posy+1 >= w.height {
|
||||
return FillSuspend
|
||||
}
|
||||
w.Move(w.posy+1, 0)
|
||||
onMove()
|
||||
return FillNextLine
|
||||
}
|
||||
return FillContinue
|
||||
}
|
||||
|
||||
func (w *LightWindow) setBg() {
|
||||
if w.bg != colDefault {
|
||||
w.csiColor(colDefault, w.bg, AttrRegular)
|
||||
}
|
||||
}
|
||||
|
||||
func (w *LightWindow) Fill(text string) FillReturn {
|
||||
w.Move(w.posy, w.posx)
|
||||
w.setBg()
|
||||
return w.fill(text, w.setBg)
|
||||
}
|
||||
|
||||
func (w *LightWindow) CFill(fg Color, bg Color, attr Attr, text string) FillReturn {
|
||||
w.Move(w.posy, w.posx)
|
||||
if fg == colDefault {
|
||||
fg = w.fg
|
||||
}
|
||||
if bg == colDefault {
|
||||
bg = w.bg
|
||||
}
|
||||
if w.csiColor(fg, bg, attr) {
|
||||
defer w.csi("m")
|
||||
return w.fill(text, func() { w.csiColor(fg, bg, attr) })
|
||||
}
|
||||
return w.fill(text, w.setBg)
|
||||
}
|
||||
|
||||
func (w *LightWindow) FinishFill() {
|
||||
w.MoveAndClear(w.posy, w.posx)
|
||||
for y := w.posy + 1; y < w.height; y++ {
|
||||
w.MoveAndClear(y, 0)
|
||||
}
|
||||
}
|
||||
|
||||
func (w *LightWindow) Erase() {
|
||||
w.drawBorder()
|
||||
// We don't erase the window here to avoid flickering during scroll
|
||||
w.Move(0, 0)
|
||||
}
|
||||
@ -1,110 +0,0 @@
|
||||
// +build !windows
|
||||
|
||||
package tui
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"os/exec"
|
||||
"strings"
|
||||
"syscall"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
"golang.org/x/term"
|
||||
)
|
||||
|
||||
func IsLightRendererSupported() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
func (r *LightRenderer) defaultTheme() *ColorTheme {
|
||||
if strings.Contains(os.Getenv("TERM"), "256") {
|
||||
return Dark256
|
||||
}
|
||||
colors, err := exec.Command("tput", "colors").Output()
|
||||
if err == nil && atoi(strings.TrimSpace(string(colors)), 16) > 16 {
|
||||
return Dark256
|
||||
}
|
||||
return Default16
|
||||
}
|
||||
|
||||
func (r *LightRenderer) fd() int {
|
||||
return int(r.ttyin.Fd())
|
||||
}
|
||||
|
||||
func (r *LightRenderer) initPlatform() error {
|
||||
fd := r.fd()
|
||||
origState, err := term.GetState(fd)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
r.origState = origState
|
||||
term.MakeRaw(fd)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (r *LightRenderer) closePlatform() {
|
||||
// NOOP
|
||||
}
|
||||
|
||||
func openTtyIn() *os.File {
|
||||
in, err := os.OpenFile(consoleDevice, syscall.O_RDONLY, 0)
|
||||
if err != nil {
|
||||
tty := ttyname()
|
||||
if len(tty) > 0 {
|
||||
if in, err := os.OpenFile(tty, syscall.O_RDONLY, 0); err == nil {
|
||||
return in
|
||||
}
|
||||
}
|
||||
fmt.Fprintln(os.Stderr, "Failed to open "+consoleDevice)
|
||||
os.Exit(2)
|
||||
}
|
||||
return in
|
||||
}
|
||||
|
||||
func (r *LightRenderer) setupTerminal() {
|
||||
term.MakeRaw(r.fd())
|
||||
}
|
||||
|
||||
func (r *LightRenderer) restoreTerminal() {
|
||||
term.Restore(r.fd(), r.origState)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) updateTerminalSize() {
|
||||
width, height, err := term.GetSize(r.fd())
|
||||
|
||||
if err == nil {
|
||||
r.width = width
|
||||
r.height = r.maxHeightFunc(height)
|
||||
} else {
|
||||
r.width = getEnv("COLUMNS", defaultWidth)
|
||||
r.height = r.maxHeightFunc(getEnv("LINES", defaultHeight))
|
||||
}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) findOffset() (row int, col int) {
|
||||
r.csi("6n")
|
||||
r.flush()
|
||||
bytes := []byte{}
|
||||
for tries := 0; tries < offsetPollTries; tries++ {
|
||||
bytes = r.getBytesInternal(bytes, tries > 0)
|
||||
offsets := offsetRegexp.FindSubmatch(bytes)
|
||||
if len(offsets) > 3 {
|
||||
// Add anything we skipped over to the input buffer
|
||||
r.buffer = append(r.buffer, offsets[1]...)
|
||||
return atoi(string(offsets[2]), 0) - 1, atoi(string(offsets[3]), 0) - 1
|
||||
}
|
||||
}
|
||||
return -1, -1
|
||||
}
|
||||
|
||||
func (r *LightRenderer) getch(nonblock bool) (int, bool) {
|
||||
b := make([]byte, 1)
|
||||
fd := r.fd()
|
||||
util.SetNonblock(r.ttyin, nonblock)
|
||||
_, err := util.Read(fd, b)
|
||||
if err != nil {
|
||||
return 0, false
|
||||
}
|
||||
return int(b[0]), true
|
||||
}
|
||||
@ -1,145 +0,0 @@
|
||||
//+build windows
|
||||
|
||||
package tui
|
||||
|
||||
import (
|
||||
"os"
|
||||
"syscall"
|
||||
"time"
|
||||
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
"golang.org/x/sys/windows"
|
||||
)
|
||||
|
||||
const (
|
||||
timeoutInterval = 10
|
||||
)
|
||||
|
||||
var (
|
||||
consoleFlagsInput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_INPUT | windows.ENABLE_PROCESSED_INPUT | windows.ENABLE_EXTENDED_FLAGS)
|
||||
consoleFlagsOutput = uint32(windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING | windows.ENABLE_PROCESSED_OUTPUT | windows.DISABLE_NEWLINE_AUTO_RETURN)
|
||||
)
|
||||
|
||||
// IsLightRendererSupported checks to see if the Light renderer is supported
|
||||
func IsLightRendererSupported() bool {
|
||||
var oldState uint32
|
||||
// enable vt100 emulation (https://docs.microsoft.com/en-us/windows/console/console-virtual-terminal-sequences)
|
||||
if windows.GetConsoleMode(windows.Stderr, &oldState) != nil {
|
||||
return false
|
||||
}
|
||||
// attempt to set mode to determine if we support VT 100 codes. This will work on newer Windows 10
|
||||
// version:
|
||||
canSetVt100 := windows.SetConsoleMode(windows.Stderr, oldState|windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING) == nil
|
||||
var checkState uint32
|
||||
if windows.GetConsoleMode(windows.Stderr, &checkState) != nil ||
|
||||
(checkState&windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING) != windows.ENABLE_VIRTUAL_TERMINAL_PROCESSING {
|
||||
return false
|
||||
}
|
||||
windows.SetConsoleMode(windows.Stderr, oldState)
|
||||
return canSetVt100
|
||||
}
|
||||
|
||||
func (r *LightRenderer) defaultTheme() *ColorTheme {
|
||||
// the getenv check is borrowed from here: https://github.com/gdamore/tcell/commit/0c473b86d82f68226a142e96cc5a34c5a29b3690#diff-b008fcd5e6934bf31bc3d33bf49f47d8R178:
|
||||
if !IsLightRendererSupported() || os.Getenv("ConEmuPID") != "" || os.Getenv("TCELL_TRUECOLOR") == "disable" {
|
||||
return Default16
|
||||
}
|
||||
return Dark256
|
||||
}
|
||||
|
||||
func (r *LightRenderer) initPlatform() error {
|
||||
//outHandle := windows.Stdout
|
||||
outHandle, _ := syscall.Open("CONOUT$", syscall.O_RDWR, 0)
|
||||
// enable vt100 emulation (https://docs.microsoft.com/en-us/windows/console/console-virtual-terminal-sequences)
|
||||
if err := windows.GetConsoleMode(windows.Handle(outHandle), &r.origStateOutput); err != nil {
|
||||
return err
|
||||
}
|
||||
r.outHandle = uintptr(outHandle)
|
||||
inHandle, _ := syscall.Open("CONIN$", syscall.O_RDWR, 0)
|
||||
if err := windows.GetConsoleMode(windows.Handle(inHandle), &r.origStateInput); err != nil {
|
||||
return err
|
||||
}
|
||||
r.inHandle = uintptr(inHandle)
|
||||
|
||||
r.setupTerminal()
|
||||
|
||||
// channel for non-blocking reads. Buffer to make sure
|
||||
// we get the ESC sets:
|
||||
r.ttyinChannel = make(chan byte, 1024)
|
||||
|
||||
// the following allows for non-blocking IO.
|
||||
// syscall.SetNonblock() is a NOOP under Windows.
|
||||
go func() {
|
||||
fd := int(r.inHandle)
|
||||
b := make([]byte, 1)
|
||||
for {
|
||||
// HACK: if run from PSReadline, something resets ConsoleMode to remove ENABLE_VIRTUAL_TERMINAL_INPUT.
|
||||
_ = windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
||||
|
||||
_, err := util.Read(fd, b)
|
||||
if err == nil {
|
||||
r.ttyinChannel <- b[0]
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (r *LightRenderer) closePlatform() {
|
||||
windows.SetConsoleMode(windows.Handle(r.outHandle), r.origStateOutput)
|
||||
windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput)
|
||||
}
|
||||
|
||||
func openTtyIn() *os.File {
|
||||
// not used
|
||||
return nil
|
||||
}
|
||||
|
||||
func (r *LightRenderer) setupTerminal() error {
|
||||
if err := windows.SetConsoleMode(windows.Handle(r.outHandle), consoleFlagsOutput); err != nil {
|
||||
return err
|
||||
}
|
||||
return windows.SetConsoleMode(windows.Handle(r.inHandle), consoleFlagsInput)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) restoreTerminal() error {
|
||||
if err := windows.SetConsoleMode(windows.Handle(r.inHandle), r.origStateInput); err != nil {
|
||||
return err
|
||||
}
|
||||
return windows.SetConsoleMode(windows.Handle(r.outHandle), r.origStateOutput)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) updateTerminalSize() {
|
||||
var bufferInfo windows.ConsoleScreenBufferInfo
|
||||
if err := windows.GetConsoleScreenBufferInfo(windows.Handle(r.outHandle), &bufferInfo); err != nil {
|
||||
r.width = getEnv("COLUMNS", defaultWidth)
|
||||
r.height = r.maxHeightFunc(getEnv("LINES", defaultHeight))
|
||||
|
||||
} else {
|
||||
r.width = int(bufferInfo.Window.Right - bufferInfo.Window.Left)
|
||||
r.height = r.maxHeightFunc(int(bufferInfo.Window.Bottom - bufferInfo.Window.Top))
|
||||
}
|
||||
}
|
||||
|
||||
func (r *LightRenderer) findOffset() (row int, col int) {
|
||||
var bufferInfo windows.ConsoleScreenBufferInfo
|
||||
if err := windows.GetConsoleScreenBufferInfo(windows.Handle(r.outHandle), &bufferInfo); err != nil {
|
||||
return -1, -1
|
||||
}
|
||||
return int(bufferInfo.CursorPosition.X), int(bufferInfo.CursorPosition.Y)
|
||||
}
|
||||
|
||||
func (r *LightRenderer) getch(nonblock bool) (int, bool) {
|
||||
if nonblock {
|
||||
select {
|
||||
case bc := <-r.ttyinChannel:
|
||||
return int(bc), true
|
||||
case <-time.After(timeoutInterval * time.Millisecond):
|
||||
return 0, false
|
||||
}
|
||||
} else {
|
||||
bc := <-r.ttyinChannel
|
||||
return int(bc), true
|
||||
}
|
||||
}
|
||||
@ -1,721 +0,0 @@
|
||||
// +build tcell windows
|
||||
|
||||
package tui
|
||||
|
||||
import (
|
||||
"os"
|
||||
"time"
|
||||
|
||||
"runtime"
|
||||
|
||||
"github.com/gdamore/tcell"
|
||||
"github.com/gdamore/tcell/encoding"
|
||||
|
||||
"github.com/mattn/go-runewidth"
|
||||
"github.com/rivo/uniseg"
|
||||
)
|
||||
|
||||
func HasFullscreenRenderer() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
func (p ColorPair) style() tcell.Style {
|
||||
style := tcell.StyleDefault
|
||||
return style.Foreground(tcell.Color(p.Fg())).Background(tcell.Color(p.Bg()))
|
||||
}
|
||||
|
||||
type Attr tcell.Style
|
||||
|
||||
type TcellWindow struct {
|
||||
color bool
|
||||
preview bool
|
||||
top int
|
||||
left int
|
||||
width int
|
||||
height int
|
||||
normal ColorPair
|
||||
lastX int
|
||||
lastY int
|
||||
moveCursor bool
|
||||
borderStyle BorderStyle
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Top() int {
|
||||
return w.top
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Left() int {
|
||||
return w.left
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Width() int {
|
||||
return w.width
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Height() int {
|
||||
return w.height
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Refresh() {
|
||||
if w.moveCursor {
|
||||
_screen.ShowCursor(w.left+w.lastX, w.top+w.lastY)
|
||||
w.moveCursor = false
|
||||
}
|
||||
w.lastX = 0
|
||||
w.lastY = 0
|
||||
|
||||
w.drawBorder()
|
||||
}
|
||||
|
||||
func (w *TcellWindow) FinishFill() {
|
||||
// NO-OP
|
||||
}
|
||||
|
||||
const (
|
||||
Bold Attr = Attr(tcell.AttrBold)
|
||||
Dim = Attr(tcell.AttrDim)
|
||||
Blink = Attr(tcell.AttrBlink)
|
||||
Reverse = Attr(tcell.AttrReverse)
|
||||
Underline = Attr(tcell.AttrUnderline)
|
||||
Italic = Attr(tcell.AttrItalic)
|
||||
)
|
||||
|
||||
const (
|
||||
AttrUndefined = Attr(0)
|
||||
AttrRegular = Attr(1 << 7)
|
||||
AttrClear = Attr(1 << 8)
|
||||
)
|
||||
|
||||
func (r *FullscreenRenderer) defaultTheme() *ColorTheme {
|
||||
if _screen.Colors() >= 256 {
|
||||
return Dark256
|
||||
}
|
||||
return Default16
|
||||
}
|
||||
|
||||
var (
|
||||
_colorToAttribute = []tcell.Color{
|
||||
tcell.ColorBlack,
|
||||
tcell.ColorRed,
|
||||
tcell.ColorGreen,
|
||||
tcell.ColorYellow,
|
||||
tcell.ColorBlue,
|
||||
tcell.ColorDarkMagenta,
|
||||
tcell.ColorLightCyan,
|
||||
tcell.ColorWhite,
|
||||
}
|
||||
)
|
||||
|
||||
func (c Color) Style() tcell.Color {
|
||||
if c <= colDefault {
|
||||
return tcell.ColorDefault
|
||||
} else if c >= colBlack && c <= colWhite {
|
||||
return _colorToAttribute[int(c)]
|
||||
} else {
|
||||
return tcell.Color(c)
|
||||
}
|
||||
}
|
||||
|
||||
func (a Attr) Merge(b Attr) Attr {
|
||||
return a | b
|
||||
}
|
||||
|
||||
// handle the following as private members of FullscreenRenderer instance
|
||||
// they are declared here to prevent introducing tcell library in non-windows builds
|
||||
var (
|
||||
_screen tcell.Screen
|
||||
_prevMouseButton tcell.ButtonMask
|
||||
)
|
||||
|
||||
func (r *FullscreenRenderer) initScreen() {
|
||||
s, e := tcell.NewScreen()
|
||||
if e != nil {
|
||||
errorExit(e.Error())
|
||||
}
|
||||
if e = s.Init(); e != nil {
|
||||
errorExit(e.Error())
|
||||
}
|
||||
if r.mouse {
|
||||
s.EnableMouse()
|
||||
} else {
|
||||
s.DisableMouse()
|
||||
}
|
||||
_screen = s
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Init() {
|
||||
if os.Getenv("TERM") == "cygwin" {
|
||||
os.Setenv("TERM", "")
|
||||
}
|
||||
encoding.Register()
|
||||
|
||||
r.initScreen()
|
||||
initTheme(r.theme, r.defaultTheme(), r.forceBlack)
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) MaxX() int {
|
||||
ncols, _ := _screen.Size()
|
||||
return int(ncols)
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) MaxY() int {
|
||||
_, nlines := _screen.Size()
|
||||
return int(nlines)
|
||||
}
|
||||
|
||||
func (w *TcellWindow) X() int {
|
||||
return w.lastX
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Y() int {
|
||||
return w.lastY
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Clear() {
|
||||
_screen.Sync()
|
||||
_screen.Clear()
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Refresh() {
|
||||
// noop
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) GetChar() Event {
|
||||
ev := _screen.PollEvent()
|
||||
switch ev := ev.(type) {
|
||||
case *tcell.EventResize:
|
||||
return Event{Resize, 0, nil}
|
||||
|
||||
// process mouse events:
|
||||
case *tcell.EventMouse:
|
||||
// mouse down events have zeroed buttons, so we can't use them
|
||||
// mouse up event consists of two events, 1. (main) event with modifier and other metadata, 2. event with zeroed buttons
|
||||
// so mouse click is three consecutive events, but the first and last are indistinguishable from movement events (with released buttons)
|
||||
// dragging has same structure, it only repeats the middle (main) event appropriately
|
||||
x, y := ev.Position()
|
||||
mod := ev.Modifiers() != 0
|
||||
|
||||
// since we dont have mouse down events (unlike LightRenderer), we need to track state in prevButton
|
||||
prevButton, button := _prevMouseButton, ev.Buttons()
|
||||
_prevMouseButton = button
|
||||
drag := prevButton == button
|
||||
|
||||
switch {
|
||||
case button&tcell.WheelDown != 0:
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, -1, false, false, false, mod}}
|
||||
case button&tcell.WheelUp != 0:
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, +1, false, false, false, mod}}
|
||||
case button&tcell.Button1 != 0 && !drag:
|
||||
// all potential double click events put their 'line' coordinate in the clickY array
|
||||
// double click event has two conditions, temporal and spatial, the first is checked here
|
||||
now := time.Now()
|
||||
if now.Sub(r.prevDownTime) < doubleClickDuration {
|
||||
r.clickY = append(r.clickY, y)
|
||||
} else {
|
||||
r.clickY = []int{y}
|
||||
}
|
||||
r.prevDownTime = now
|
||||
|
||||
// detect double clicks (also check for spatial condition)
|
||||
n := len(r.clickY)
|
||||
double := n > 1 && r.clickY[n-2] == r.clickY[n-1]
|
||||
if double {
|
||||
// make sure two consecutive double clicks require four clicks
|
||||
r.clickY = []int{}
|
||||
}
|
||||
|
||||
// fire single or double click event
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, 0, true, !double, double, mod}}
|
||||
case button&tcell.Button2 != 0 && !drag:
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, 0, false, true, false, mod}}
|
||||
case runtime.GOOS != "windows":
|
||||
|
||||
// double and single taps on Windows don't quite work due to
|
||||
// the console acting on the events and not allowing us
|
||||
// to consume them.
|
||||
|
||||
left := button&tcell.Button1 != 0
|
||||
down := left || button&tcell.Button3 != 0
|
||||
double := false
|
||||
if down {
|
||||
now := time.Now()
|
||||
if !left {
|
||||
r.clickY = []int{}
|
||||
} else if now.Sub(r.prevDownTime) < doubleClickDuration {
|
||||
r.clickY = append(r.clickY, x)
|
||||
} else {
|
||||
r.clickY = []int{x}
|
||||
r.prevDownTime = now
|
||||
}
|
||||
} else {
|
||||
if len(r.clickY) > 1 && r.clickY[0] == r.clickY[1] &&
|
||||
time.Now().Sub(r.prevDownTime) < doubleClickDuration {
|
||||
double = true
|
||||
}
|
||||
}
|
||||
|
||||
return Event{Mouse, 0, &MouseEvent{y, x, 0, left, down, double, mod}}
|
||||
}
|
||||
|
||||
// process keyboard:
|
||||
case *tcell.EventKey:
|
||||
mods := ev.Modifiers()
|
||||
none := mods == tcell.ModNone
|
||||
alt := (mods & tcell.ModAlt) > 0
|
||||
ctrl := (mods & tcell.ModCtrl) > 0
|
||||
shift := (mods & tcell.ModShift) > 0
|
||||
ctrlAlt := ctrl && alt
|
||||
altShift := alt && shift
|
||||
|
||||
keyfn := func(r rune) Event {
|
||||
if alt {
|
||||
return CtrlAltKey(r)
|
||||
}
|
||||
return EventType(CtrlA.Int() - 'a' + int(r)).AsEvent()
|
||||
}
|
||||
switch ev.Key() {
|
||||
// section 1: Ctrl+(Alt)+[a-z]
|
||||
case tcell.KeyCtrlA:
|
||||
return keyfn('a')
|
||||
case tcell.KeyCtrlB:
|
||||
return keyfn('b')
|
||||
case tcell.KeyCtrlC:
|
||||
return keyfn('c')
|
||||
case tcell.KeyCtrlD:
|
||||
return keyfn('d')
|
||||
case tcell.KeyCtrlE:
|
||||
return keyfn('e')
|
||||
case tcell.KeyCtrlF:
|
||||
return keyfn('f')
|
||||
case tcell.KeyCtrlG:
|
||||
return keyfn('g')
|
||||
case tcell.KeyCtrlH:
|
||||
switch ev.Rune() {
|
||||
case 0:
|
||||
if ctrl {
|
||||
return Event{BSpace, 0, nil}
|
||||
}
|
||||
case rune(tcell.KeyCtrlH):
|
||||
switch {
|
||||
case ctrl:
|
||||
return keyfn('h')
|
||||
case alt:
|
||||
return Event{AltBS, 0, nil}
|
||||
case none, shift:
|
||||
return Event{BSpace, 0, nil}
|
||||
}
|
||||
}
|
||||
case tcell.KeyCtrlI:
|
||||
return keyfn('i')
|
||||
case tcell.KeyCtrlJ:
|
||||
return keyfn('j')
|
||||
case tcell.KeyCtrlK:
|
||||
return keyfn('k')
|
||||
case tcell.KeyCtrlL:
|
||||
return keyfn('l')
|
||||
case tcell.KeyCtrlM:
|
||||
return keyfn('m')
|
||||
case tcell.KeyCtrlN:
|
||||
return keyfn('n')
|
||||
case tcell.KeyCtrlO:
|
||||
return keyfn('o')
|
||||
case tcell.KeyCtrlP:
|
||||
return keyfn('p')
|
||||
case tcell.KeyCtrlQ:
|
||||
return keyfn('q')
|
||||
case tcell.KeyCtrlR:
|
||||
return keyfn('r')
|
||||
case tcell.KeyCtrlS:
|
||||
return keyfn('s')
|
||||
case tcell.KeyCtrlT:
|
||||
return keyfn('t')
|
||||
case tcell.KeyCtrlU:
|
||||
return keyfn('u')
|
||||
case tcell.KeyCtrlV:
|
||||
return keyfn('v')
|
||||
case tcell.KeyCtrlW:
|
||||
return keyfn('w')
|
||||
case tcell.KeyCtrlX:
|
||||
return keyfn('x')
|
||||
case tcell.KeyCtrlY:
|
||||
return keyfn('y')
|
||||
case tcell.KeyCtrlZ:
|
||||
return keyfn('z')
|
||||
// section 2: Ctrl+[ \]_]
|
||||
case tcell.KeyCtrlSpace:
|
||||
return Event{CtrlSpace, 0, nil}
|
||||
case tcell.KeyCtrlBackslash:
|
||||
return Event{CtrlBackSlash, 0, nil}
|
||||
case tcell.KeyCtrlRightSq:
|
||||
return Event{CtrlRightBracket, 0, nil}
|
||||
case tcell.KeyCtrlCarat:
|
||||
return Event{CtrlCaret, 0, nil}
|
||||
case tcell.KeyCtrlUnderscore:
|
||||
return Event{CtrlSlash, 0, nil}
|
||||
// section 3: (Alt)+Backspace2
|
||||
case tcell.KeyBackspace2:
|
||||
if alt {
|
||||
return Event{AltBS, 0, nil}
|
||||
}
|
||||
return Event{BSpace, 0, nil}
|
||||
|
||||
// section 4: (Alt+Shift)+Key(Up|Down|Left|Right)
|
||||
case tcell.KeyUp:
|
||||
if altShift {
|
||||
return Event{AltSUp, 0, nil}
|
||||
}
|
||||
if shift {
|
||||
return Event{SUp, 0, nil}
|
||||
}
|
||||
if alt {
|
||||
return Event{AltUp, 0, nil}
|
||||
}
|
||||
return Event{Up, 0, nil}
|
||||
case tcell.KeyDown:
|
||||
if altShift {
|
||||
return Event{AltSDown, 0, nil}
|
||||
}
|
||||
if shift {
|
||||
return Event{SDown, 0, nil}
|
||||
}
|
||||
if alt {
|
||||
return Event{AltDown, 0, nil}
|
||||
}
|
||||
return Event{Down, 0, nil}
|
||||
case tcell.KeyLeft:
|
||||
if altShift {
|
||||
return Event{AltSLeft, 0, nil}
|
||||
}
|
||||
if shift {
|
||||
return Event{SLeft, 0, nil}
|
||||
}
|
||||
if alt {
|
||||
return Event{AltLeft, 0, nil}
|
||||
}
|
||||
return Event{Left, 0, nil}
|
||||
case tcell.KeyRight:
|
||||
if altShift {
|
||||
return Event{AltSRight, 0, nil}
|
||||
}
|
||||
if shift {
|
||||
return Event{SRight, 0, nil}
|
||||
}
|
||||
if alt {
|
||||
return Event{AltRight, 0, nil}
|
||||
}
|
||||
return Event{Right, 0, nil}
|
||||
|
||||
// section 5: (Insert|Home|Delete|End|PgUp|PgDn|BackTab|F1-F12)
|
||||
case tcell.KeyInsert:
|
||||
return Event{Insert, 0, nil}
|
||||
case tcell.KeyHome:
|
||||
return Event{Home, 0, nil}
|
||||
case tcell.KeyDelete:
|
||||
return Event{Del, 0, nil}
|
||||
case tcell.KeyEnd:
|
||||
return Event{End, 0, nil}
|
||||
case tcell.KeyPgUp:
|
||||
return Event{PgUp, 0, nil}
|
||||
case tcell.KeyPgDn:
|
||||
return Event{PgDn, 0, nil}
|
||||
case tcell.KeyBacktab:
|
||||
return Event{BTab, 0, nil}
|
||||
case tcell.KeyF1:
|
||||
return Event{F1, 0, nil}
|
||||
case tcell.KeyF2:
|
||||
return Event{F2, 0, nil}
|
||||
case tcell.KeyF3:
|
||||
return Event{F3, 0, nil}
|
||||
case tcell.KeyF4:
|
||||
return Event{F4, 0, nil}
|
||||
case tcell.KeyF5:
|
||||
return Event{F5, 0, nil}
|
||||
case tcell.KeyF6:
|
||||
return Event{F6, 0, nil}
|
||||
case tcell.KeyF7:
|
||||
return Event{F7, 0, nil}
|
||||
case tcell.KeyF8:
|
||||
return Event{F8, 0, nil}
|
||||
case tcell.KeyF9:
|
||||
return Event{F9, 0, nil}
|
||||
case tcell.KeyF10:
|
||||
return Event{F10, 0, nil}
|
||||
case tcell.KeyF11:
|
||||
return Event{F11, 0, nil}
|
||||
case tcell.KeyF12:
|
||||
return Event{F12, 0, nil}
|
||||
|
||||
// section 6: (Ctrl+Alt)+'rune'
|
||||
case tcell.KeyRune:
|
||||
r := ev.Rune()
|
||||
|
||||
switch {
|
||||
// translate native key events to ascii control characters
|
||||
case r == ' ' && ctrl:
|
||||
return Event{CtrlSpace, 0, nil}
|
||||
// handle AltGr characters
|
||||
case ctrlAlt:
|
||||
return Event{Rune, r, nil} // dropping modifiers
|
||||
// simple characters (possibly with modifier)
|
||||
case alt:
|
||||
return AltKey(r)
|
||||
default:
|
||||
return Event{Rune, r, nil}
|
||||
}
|
||||
|
||||
// section 7: Esc
|
||||
case tcell.KeyEsc:
|
||||
return Event{ESC, 0, nil}
|
||||
}
|
||||
}
|
||||
|
||||
// section 8: Invalid
|
||||
return Event{Invalid, 0, nil}
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Pause(clear bool) {
|
||||
if clear {
|
||||
_screen.Fini()
|
||||
}
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Resume(clear bool, sigcont bool) {
|
||||
if clear {
|
||||
r.initScreen()
|
||||
}
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) Close() {
|
||||
_screen.Fini()
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) RefreshWindows(windows []Window) {
|
||||
// TODO
|
||||
for _, w := range windows {
|
||||
w.Refresh()
|
||||
}
|
||||
_screen.Show()
|
||||
}
|
||||
|
||||
func (r *FullscreenRenderer) NewWindow(top int, left int, width int, height int, preview bool, borderStyle BorderStyle) Window {
|
||||
normal := ColNormal
|
||||
if preview {
|
||||
normal = ColPreview
|
||||
}
|
||||
return &TcellWindow{
|
||||
color: r.theme.Colored,
|
||||
preview: preview,
|
||||
top: top,
|
||||
left: left,
|
||||
width: width,
|
||||
height: height,
|
||||
normal: normal,
|
||||
borderStyle: borderStyle}
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Close() {
|
||||
// TODO
|
||||
}
|
||||
|
||||
func fill(x, y, w, h int, n ColorPair, r rune) {
|
||||
for ly := 0; ly <= h; ly++ {
|
||||
for lx := 0; lx <= w; lx++ {
|
||||
_screen.SetContent(x+lx, y+ly, r, nil, n.style())
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Erase() {
|
||||
fill(w.left-1, w.top, w.width+1, w.height, w.normal, ' ')
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Enclose(y int, x int) bool {
|
||||
return x >= w.left && x < (w.left+w.width) &&
|
||||
y >= w.top && y < (w.top+w.height)
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Move(y int, x int) {
|
||||
w.lastX = x
|
||||
w.lastY = y
|
||||
w.moveCursor = true
|
||||
}
|
||||
|
||||
func (w *TcellWindow) MoveAndClear(y int, x int) {
|
||||
w.Move(y, x)
|
||||
for i := w.lastX; i < w.width; i++ {
|
||||
_screen.SetContent(i+w.left, w.lastY+w.top, rune(' '), nil, w.normal.style())
|
||||
}
|
||||
w.lastX = x
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Print(text string) {
|
||||
w.printString(text, w.normal)
|
||||
}
|
||||
|
||||
func (w *TcellWindow) printString(text string, pair ColorPair) {
|
||||
lx := 0
|
||||
a := pair.Attr()
|
||||
|
||||
style := pair.style()
|
||||
if a&AttrClear == 0 {
|
||||
style = style.
|
||||
Reverse(a&Attr(tcell.AttrReverse) != 0).
|
||||
Underline(a&Attr(tcell.AttrUnderline) != 0).
|
||||
Italic(a&Attr(tcell.AttrItalic) != 0).
|
||||
Blink(a&Attr(tcell.AttrBlink) != 0).
|
||||
Dim(a&Attr(tcell.AttrDim) != 0)
|
||||
}
|
||||
|
||||
gr := uniseg.NewGraphemes(text)
|
||||
for gr.Next() {
|
||||
rs := gr.Runes()
|
||||
|
||||
if len(rs) == 1 {
|
||||
r := rs[0]
|
||||
if r < rune(' ') { // ignore control characters
|
||||
continue
|
||||
} else if r == '\n' {
|
||||
w.lastY++
|
||||
lx = 0
|
||||
continue
|
||||
} else if r == '\u000D' { // skip carriage return
|
||||
continue
|
||||
}
|
||||
}
|
||||
var xPos = w.left + w.lastX + lx
|
||||
var yPos = w.top + w.lastY
|
||||
if xPos < (w.left+w.width) && yPos < (w.top+w.height) {
|
||||
_screen.SetContent(xPos, yPos, rs[0], rs[1:], style)
|
||||
}
|
||||
lx += runewidth.StringWidth(string(rs))
|
||||
}
|
||||
w.lastX += lx
|
||||
}
|
||||
|
||||
func (w *TcellWindow) CPrint(pair ColorPair, text string) {
|
||||
w.printString(text, pair)
|
||||
}
|
||||
|
||||
func (w *TcellWindow) fillString(text string, pair ColorPair) FillReturn {
|
||||
lx := 0
|
||||
a := pair.Attr()
|
||||
|
||||
var style tcell.Style
|
||||
if w.color {
|
||||
style = pair.style()
|
||||
} else {
|
||||
style = w.normal.style()
|
||||
}
|
||||
style = style.
|
||||
Blink(a&Attr(tcell.AttrBlink) != 0).
|
||||
Bold(a&Attr(tcell.AttrBold) != 0).
|
||||
Dim(a&Attr(tcell.AttrDim) != 0).
|
||||
Reverse(a&Attr(tcell.AttrReverse) != 0).
|
||||
Underline(a&Attr(tcell.AttrUnderline) != 0).
|
||||
Italic(a&Attr(tcell.AttrItalic) != 0)
|
||||
|
||||
gr := uniseg.NewGraphemes(text)
|
||||
for gr.Next() {
|
||||
rs := gr.Runes()
|
||||
if len(rs) == 1 && rs[0] == '\n' {
|
||||
w.lastY++
|
||||
w.lastX = 0
|
||||
lx = 0
|
||||
continue
|
||||
}
|
||||
|
||||
// word wrap:
|
||||
xPos := w.left + w.lastX + lx
|
||||
if xPos >= (w.left + w.width) {
|
||||
w.lastY++
|
||||
w.lastX = 0
|
||||
lx = 0
|
||||
xPos = w.left
|
||||
}
|
||||
|
||||
yPos := w.top + w.lastY
|
||||
if yPos >= (w.top + w.height) {
|
||||
return FillSuspend
|
||||
}
|
||||
|
||||
_screen.SetContent(xPos, yPos, rs[0], rs[1:], style)
|
||||
lx += runewidth.StringWidth(string(rs))
|
||||
}
|
||||
w.lastX += lx
|
||||
if w.lastX == w.width {
|
||||
w.lastY++
|
||||
w.lastX = 0
|
||||
return FillNextLine
|
||||
}
|
||||
|
||||
return FillContinue
|
||||
}
|
||||
|
||||
func (w *TcellWindow) Fill(str string) FillReturn {
|
||||
return w.fillString(str, w.normal)
|
||||
}
|
||||
|
||||
func (w *TcellWindow) CFill(fg Color, bg Color, a Attr, str string) FillReturn {
|
||||
if fg == colDefault {
|
||||
fg = w.normal.Fg()
|
||||
}
|
||||
if bg == colDefault {
|
||||
bg = w.normal.Bg()
|
||||
}
|
||||
return w.fillString(str, NewColorPair(fg, bg, a))
|
||||
}
|
||||
|
||||
func (w *TcellWindow) drawBorder() {
|
||||
shape := w.borderStyle.shape
|
||||
if shape == BorderNone {
|
||||
return
|
||||
}
|
||||
|
||||
left := w.left
|
||||
right := left + w.width
|
||||
top := w.top
|
||||
bot := top + w.height
|
||||
|
||||
var style tcell.Style
|
||||
if w.color {
|
||||
if w.preview {
|
||||
style = ColPreviewBorder.style()
|
||||
} else {
|
||||
style = ColBorder.style()
|
||||
}
|
||||
} else {
|
||||
style = w.normal.style()
|
||||
}
|
||||
|
||||
switch shape {
|
||||
case BorderRounded, BorderSharp, BorderHorizontal, BorderTop:
|
||||
for x := left; x < right; x++ {
|
||||
_screen.SetContent(x, top, w.borderStyle.horizontal, nil, style)
|
||||
}
|
||||
}
|
||||
switch shape {
|
||||
case BorderRounded, BorderSharp, BorderHorizontal, BorderBottom:
|
||||
for x := left; x < right; x++ {
|
||||
_screen.SetContent(x, bot-1, w.borderStyle.horizontal, nil, style)
|
||||
}
|
||||
}
|
||||
switch shape {
|
||||
case BorderRounded, BorderSharp, BorderVertical, BorderLeft:
|
||||
for y := top; y < bot; y++ {
|
||||
_screen.SetContent(left, y, w.borderStyle.vertical, nil, style)
|
||||
}
|
||||
}
|
||||
switch shape {
|
||||
case BorderRounded, BorderSharp, BorderVertical, BorderRight:
|
||||
for y := top; y < bot; y++ {
|
||||
_screen.SetContent(right-1, y, w.borderStyle.vertical, nil, style)
|
||||
}
|
||||
}
|
||||
switch shape {
|
||||
case BorderRounded, BorderSharp:
|
||||
_screen.SetContent(left, top, w.borderStyle.topLeft, nil, style)
|
||||
_screen.SetContent(right-1, top, w.borderStyle.topRight, nil, style)
|
||||
_screen.SetContent(left, bot-1, w.borderStyle.bottomLeft, nil, style)
|
||||
_screen.SetContent(right-1, bot-1, w.borderStyle.bottomRight, nil, style)
|
||||
}
|
||||
}
|
||||
@ -1,392 +0,0 @@
|
||||
// +build tcell windows
|
||||
|
||||
package tui
|
||||
|
||||
import (
|
||||
"testing"
|
||||
|
||||
"github.com/gdamore/tcell"
|
||||
"github.com/junegunn/fzf/src/util"
|
||||
)
|
||||
|
||||
func assert(t *testing.T, context string, got interface{}, want interface{}) bool {
|
||||
if got == want {
|
||||
return true
|
||||
} else {
|
||||
t.Errorf("%s = (%T)%v, want (%T)%v", context, got, got, want, want)
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
// Test the handling of the tcell keyboard events.
|
||||
func TestGetCharEventKey(t *testing.T) {
|
||||
if util.ToTty() {
|
||||
// This test is skipped when output goes to terminal, because it causes
|
||||
// some glitches:
|
||||
// - output lines may not start at the beginning of a row which makes
|
||||
// the output unreadable
|
||||
// - terminal may get cleared which prevents you from seeing results of
|
||||
// previous tests
|
||||
// Good ways to prevent the glitches are piping the output to a pager
|
||||
// or redirecting to a file. I've found `less +G` to be trouble-free.
|
||||
t.Skip("Skipped because this test misbehaves in terminal, pipe to a pager or redirect output to a file to run it safely.")
|
||||
} else if testing.Verbose() {
|
||||
// I have observed a behaviour when this test outputted more than 8192
|
||||
// bytes (32*256) into the 'less' pager, both the go's test executable
|
||||
// and the pager hanged. The go's executable was blocking on printing.
|
||||
// I was able to create minimal working example of that behaviour, but
|
||||
// that example hanged after 12256 bytes (32*(256+127)).
|
||||
t.Log("If you are piping this test to a pager and it hangs, make the pager greedy for input, e.g. 'less +G'.")
|
||||
}
|
||||
|
||||
if !HasFullscreenRenderer() {
|
||||
t.Skip("Can't test FullscreenRenderer.")
|
||||
}
|
||||
|
||||
// construct test cases
|
||||
type giveKey struct {
|
||||
Type tcell.Key
|
||||
Char rune
|
||||
Mods tcell.ModMask
|
||||
}
|
||||
type wantKey = Event
|
||||
type testCase struct {
|
||||
giveKey
|
||||
wantKey
|
||||
}
|
||||
/*
|
||||
Some test cases are marked "fabricated". It means that giveKey value
|
||||
is valid, but it is not what you get when you press the keys. For
|
||||
example Ctrl+C will NOT give you tcell.KeyCtrlC, but tcell.KeyETX
|
||||
(End-Of-Text character, causing SIGINT).
|
||||
I was trying to accompany the fabricated test cases with real ones.
|
||||
|
||||
Some test cases are marked "unhandled". It means that giveKey.Type
|
||||
is not present in tcell.go source code. It can still be handled via
|
||||
implicit or explicit alias.
|
||||
|
||||
If not said otherwise, test cases are for US keyboard.
|
||||
|
||||
(tabstop=44)
|
||||
*/
|
||||
tests := []testCase{
|
||||
|
||||
// section 1: Ctrl+(Alt)+[a-z]
|
||||
{giveKey{tcell.KeyCtrlA, rune(tcell.KeyCtrlA), tcell.ModCtrl}, wantKey{CtrlA, 0, nil}},
|
||||
{giveKey{tcell.KeyCtrlC, rune(tcell.KeyCtrlC), tcell.ModCtrl}, wantKey{CtrlC, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyETX, rune(tcell.KeyETX), tcell.ModCtrl}, wantKey{CtrlC, 0, nil}}, // this is SIGINT (Ctrl+C)
|
||||
{giveKey{tcell.KeyCtrlZ, rune(tcell.KeyCtrlZ), tcell.ModCtrl}, wantKey{CtrlZ, 0, nil}}, // fabricated
|
||||
// KeyTab is alias for KeyTAB
|
||||
{giveKey{tcell.KeyCtrlI, rune(tcell.KeyCtrlI), tcell.ModCtrl}, wantKey{Tab, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyTab, rune(tcell.KeyTab), tcell.ModNone}, wantKey{Tab, 0, nil}}, // unhandled, actual "Tab" keystroke
|
||||
{giveKey{tcell.KeyTAB, rune(tcell.KeyTAB), tcell.ModNone}, wantKey{Tab, 0, nil}}, // fabricated, unhandled
|
||||
// KeyEnter is alias for KeyCR
|
||||
{giveKey{tcell.KeyCtrlM, rune(tcell.KeyCtrlM), tcell.ModNone}, wantKey{CtrlM, 0, nil}}, // actual "Enter" keystroke
|
||||
{giveKey{tcell.KeyCR, rune(tcell.KeyCR), tcell.ModNone}, wantKey{CtrlM, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyEnter, rune(tcell.KeyEnter), tcell.ModNone}, wantKey{CtrlM, 0, nil}}, // fabricated, unhandled
|
||||
// Ctrl+Alt keys
|
||||
{giveKey{tcell.KeyCtrlA, rune(tcell.KeyCtrlA), tcell.ModCtrl | tcell.ModAlt}, wantKey{CtrlAlt, 'a', nil}}, // fabricated
|
||||
{giveKey{tcell.KeyCtrlA, rune(tcell.KeyCtrlA), tcell.ModCtrl | tcell.ModAlt | tcell.ModShift}, wantKey{CtrlAlt, 'a', nil}}, // fabricated
|
||||
|
||||
// section 2: Ctrl+[ \]_]
|
||||
{giveKey{tcell.KeyCtrlSpace, rune(tcell.KeyCtrlSpace), tcell.ModCtrl}, wantKey{CtrlSpace, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyNUL, rune(tcell.KeyNUL), tcell.ModNone}, wantKey{CtrlSpace, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyRune, ' ', tcell.ModCtrl}, wantKey{CtrlSpace, 0, nil}}, // actual Ctrl+' '
|
||||
{giveKey{tcell.KeyCtrlBackslash, rune(tcell.KeyCtrlBackslash), tcell.ModCtrl}, wantKey{CtrlBackSlash, 0, nil}},
|
||||
{giveKey{tcell.KeyCtrlRightSq, rune(tcell.KeyCtrlRightSq), tcell.ModCtrl}, wantKey{CtrlRightBracket, 0, nil}},
|
||||
{giveKey{tcell.KeyCtrlCarat, rune(tcell.KeyCtrlCarat), tcell.ModShift | tcell.ModCtrl}, wantKey{CtrlCaret, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyRS, rune(tcell.KeyRS), tcell.ModShift | tcell.ModCtrl}, wantKey{CtrlCaret, 0, nil}}, // actual Ctrl+Shift+6 (i.e. Ctrl+^) keystroke
|
||||
{giveKey{tcell.KeyCtrlUnderscore, rune(tcell.KeyCtrlUnderscore), tcell.ModShift | tcell.ModCtrl}, wantKey{CtrlSlash, 0, nil}},
|
||||
|
||||
// section 3: (Alt)+Backspace2
|
||||
// KeyBackspace2 is alias for KeyDEL = 0x7F (ASCII) (allegedly unused by Windows)
|
||||
// KeyDelete = 0x2E (VK_DELETE constant in Windows)
|
||||
// KeyBackspace is alias for KeyBS = 0x08 (ASCII) (implicit alias with KeyCtrlH)
|
||||
{giveKey{tcell.KeyBackspace2, 0, tcell.ModNone}, wantKey{BSpace, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyBackspace2, 0, tcell.ModAlt}, wantKey{AltBS, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyDEL, 0, tcell.ModNone}, wantKey{BSpace, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyDelete, 0, tcell.ModNone}, wantKey{Del, 0, nil}},
|
||||
{giveKey{tcell.KeyDelete, 0, tcell.ModAlt}, wantKey{Del, 0, nil}},
|
||||
{giveKey{tcell.KeyBackspace, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyBS, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyCtrlH, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModNone}, wantKey{BSpace, 0, nil}}, // actual "Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModAlt}, wantKey{AltBS, 0, nil}}, // actual "Alt+Backspace" keystroke
|
||||
{giveKey{tcell.KeyDEL, rune(tcell.KeyDEL), tcell.ModCtrl}, wantKey{BSpace, 0, nil}}, // actual "Ctrl+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModShift}, wantKey{BSpace, 0, nil}}, // actual "Shift+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, 0, tcell.ModCtrl | tcell.ModAlt}, wantKey{BSpace, 0, nil}}, // actual "Ctrl+Alt+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, 0, tcell.ModCtrl | tcell.ModShift}, wantKey{BSpace, 0, nil}}, // actual "Ctrl+Shift+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModShift | tcell.ModAlt}, wantKey{AltBS, 0, nil}}, // actual "Shift+Alt+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, 0, tcell.ModCtrl | tcell.ModAlt | tcell.ModShift}, wantKey{BSpace, 0, nil}}, // actual "Ctrl+Shift+Alt+Backspace" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModCtrl}, wantKey{CtrlH, 0, nil}}, // actual "Ctrl+H" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModCtrl | tcell.ModAlt}, wantKey{CtrlAlt, 'h', nil}}, // fabricated "Ctrl+Alt+H" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModCtrl | tcell.ModShift}, wantKey{CtrlH, 0, nil}}, // actual "Ctrl+Shift+H" keystroke
|
||||
{giveKey{tcell.KeyCtrlH, rune(tcell.KeyCtrlH), tcell.ModCtrl | tcell.ModAlt | tcell.ModShift}, wantKey{CtrlAlt, 'h', nil}}, // fabricated "Ctrl+Shift+Alt+H" keystroke
|
||||
|
||||
// section 4: (Alt+Shift)+Key(Up|Down|Left|Right)
|
||||
{giveKey{tcell.KeyUp, 0, tcell.ModNone}, wantKey{Up, 0, nil}},
|
||||
{giveKey{tcell.KeyDown, 0, tcell.ModAlt}, wantKey{AltDown, 0, nil}},
|
||||
{giveKey{tcell.KeyLeft, 0, tcell.ModShift}, wantKey{SLeft, 0, nil}},
|
||||
{giveKey{tcell.KeyRight, 0, tcell.ModShift | tcell.ModAlt}, wantKey{AltSRight, 0, nil}},
|
||||
{giveKey{tcell.KeyUpLeft, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyUpRight, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyDownLeft, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyDownRight, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyCenter, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
// section 5: (Insert|Home|Delete|End|PgUp|PgDn|BackTab|F1-F12)
|
||||
{giveKey{tcell.KeyInsert, 0, tcell.ModNone}, wantKey{Insert, 0, nil}},
|
||||
{giveKey{tcell.KeyF1, 0, tcell.ModNone}, wantKey{F1, 0, nil}},
|
||||
// section 6: (Ctrl+Alt)+'rune'
|
||||
{giveKey{tcell.KeyRune, 'a', tcell.ModNone}, wantKey{Rune, 'a', nil}},
|
||||
{giveKey{tcell.KeyRune, 'a', tcell.ModCtrl}, wantKey{Rune, 'a', nil}}, // fabricated
|
||||
{giveKey{tcell.KeyRune, 'a', tcell.ModAlt}, wantKey{Alt, 'a', nil}},
|
||||
{giveKey{tcell.KeyRune, 'A', tcell.ModAlt}, wantKey{Alt, 'A', nil}},
|
||||
{giveKey{tcell.KeyRune, '`', tcell.ModAlt}, wantKey{Alt, '`', nil}},
|
||||
/*
|
||||
"Input method" in Windows Language options:
|
||||
US: "US Keyboard" does not generate any characters (and thus any events) in Ctrl+Alt+[a-z] range
|
||||
CS: "Czech keyboard"
|
||||
DE: "German keyboard"
|
||||
|
||||
Note that right Alt is not just `tcell.ModAlt` on foreign language keyboards, but it is the AltGr `tcell.ModCtrl|tcell.ModAlt`.
|
||||
*/
|
||||
{giveKey{tcell.KeyRune, '{', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '{', nil}}, // CS: Ctrl+Alt+b = "{" // Note that this does not interfere with CtrlB, since the "b" is replaced with "{" on OS level
|
||||
{giveKey{tcell.KeyRune, '$', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '$', nil}}, // CS: Ctrl+Alt+ů = "$"
|
||||
{giveKey{tcell.KeyRune, '~', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '~', nil}}, // CS: Ctrl+Alt++ = "~"
|
||||
{giveKey{tcell.KeyRune, '`', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '`', nil}}, // CS: Ctrl+Alt+ý,Space = "`" // this is dead key, space is required to emit the char
|
||||
|
||||
{giveKey{tcell.KeyRune, '{', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '{', nil}}, // DE: Ctrl+Alt+7 = "{"
|
||||
{giveKey{tcell.KeyRune, '@', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, '@', nil}}, // DE: Ctrl+Alt+q = "@"
|
||||
{giveKey{tcell.KeyRune, 'µ', tcell.ModCtrl | tcell.ModAlt}, wantKey{Rune, 'µ', nil}}, // DE: Ctrl+Alt+m = "µ"
|
||||
|
||||
// section 7: Esc
|
||||
// KeyEsc and KeyEscape are aliases for KeyESC
|
||||
{giveKey{tcell.KeyEsc, rune(tcell.KeyEsc), tcell.ModNone}, wantKey{ESC, 0, nil}}, // fabricated
|
||||
{giveKey{tcell.KeyESC, rune(tcell.KeyESC), tcell.ModNone}, wantKey{ESC, 0, nil}}, // unhandled
|
||||
{giveKey{tcell.KeyEscape, rune(tcell.KeyEscape), tcell.ModNone}, wantKey{ESC, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyESC, rune(tcell.KeyESC), tcell.ModCtrl}, wantKey{ESC, 0, nil}}, // actual Ctrl+[ keystroke
|
||||
{giveKey{tcell.KeyCtrlLeftSq, rune(tcell.KeyCtrlLeftSq), tcell.ModCtrl}, wantKey{ESC, 0, nil}}, // fabricated, unhandled
|
||||
|
||||
// section 8: Invalid
|
||||
{giveKey{tcell.KeyRune, 'a', tcell.ModMeta}, wantKey{Rune, 'a', nil}}, // fabricated
|
||||
{giveKey{tcell.KeyF24, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}},
|
||||
{giveKey{tcell.KeyHelp, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyExit, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyClear, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // unhandled, actual keystroke Numpad_5 with Numlock OFF
|
||||
{giveKey{tcell.KeyCancel, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyPrint, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // fabricated, unhandled
|
||||
{giveKey{tcell.KeyPause, 0, tcell.ModNone}, wantKey{Invalid, 0, nil}}, // unhandled
|
||||
|
||||
}
|
||||
r := NewFullscreenRenderer(&ColorTheme{}, false, false)
|
||||
r.Init()
|
||||
|
||||
// run and evaluate the tests
|
||||
for _, test := range tests {
|
||||
// generate key event
|
||||
giveEvent := tcell.NewEventKey(test.giveKey.Type, test.giveKey.Char, test.giveKey.Mods)
|
||||
_screen.PostEventWait(giveEvent)
|
||||
t.Logf("giveEvent = %T{key: %v, ch: %q (%[3]v), mod: %#04b}\n", giveEvent, giveEvent.Key(), giveEvent.Rune(), giveEvent.Modifiers())
|
||||
|
||||
// process the event in fzf and evaluate the test
|
||||
gotEvent := r.GetChar()
|
||||
// skip Resize events, those are sometimes put in the buffer outside of this test
|
||||
for gotEvent.Type == Resize {
|
||||
t.Logf("Resize swallowed")
|
||||
gotEvent = r.GetChar()
|
||||
}
|
||||
t.Logf("wantEvent = %T{Type: %v, Char: %q (%[3]v)}\n", test.wantKey, test.wantKey.Type, test.wantKey.Char)
|
||||
t.Logf("gotEvent = %T{Type: %v, Char: %q (%[3]v)}\n", gotEvent, gotEvent.Type, gotEvent.Char)
|
||||
|
||||
assert(t, "r.GetChar().Type", gotEvent.Type, test.wantKey.Type)
|
||||
assert(t, "r.GetChar().Char", gotEvent.Char, test.wantKey.Char)
|
||||
}
|
||||
|
||||
r.Close()
|
||||
}
|
||||
|
||||
/*
|
||||
Quick reference
|
||||
---------------
|
||||
|
||||
(tabstop=18)
|
||||
(this is not mapping table, it merely puts multiple constants ranges in one table)
|
||||
|
||||
¹) the two columns are each other implicit alias
|
||||
²) explicit aliases here
|
||||
|
||||
%v section # tcell ctrl key¹ tcell ctrl char¹ tcell alias² tui constants tcell named keys tcell mods
|
||||
-- --------- -------------- --------------- ----------- ------------- ---------------- ----------
|
||||
0 2 KeyCtrlSpace KeyNUL = ^@ Rune ModNone
|
||||
1 1 KeyCtrlA KeySOH = ^A CtrlA ModShift
|
||||
2 1 KeyCtrlB KeySTX = ^B CtrlB ModCtrl
|
||||
3 1 KeyCtrlC KeyETX = ^C CtrlC
|
||||
4 1 KeyCtrlD KeyEOT = ^D CtrlD ModAlt
|
||||
5 1 KeyCtrlE KeyENQ = ^E CtrlE
|
||||
6 1 KeyCtrlF KeyACK = ^F CtrlF
|
||||
7 1 KeyCtrlG KeyBEL = ^G CtrlG
|
||||
8 1 KeyCtrlH KeyBS = ^H KeyBackspace CtrlH ModMeta
|
||||
9 1 KeyCtrlI KeyTAB = ^I KeyTab Tab
|
||||
10 1 KeyCtrlJ KeyLF = ^J CtrlJ
|
||||
11 1 KeyCtrlK KeyVT = ^K CtrlK
|
||||
12 1 KeyCtrlL KeyFF = ^L CtrlL
|
||||
13 1 KeyCtrlM KeyCR = ^M KeyEnter CtrlM
|
||||
14 1 KeyCtrlN KeySO = ^N CtrlN
|
||||
15 1 KeyCtrlO KeySI = ^O CtrlO
|
||||
16 1 KeyCtrlP KeyDLE = ^P CtrlP
|
||||
17 1 KeyCtrlQ KeyDC1 = ^Q CtrlQ
|
||||
18 1 KeyCtrlR KeyDC2 = ^R CtrlR
|
||||
19 1 KeyCtrlS KeyDC3 = ^S CtrlS
|
||||
20 1 KeyCtrlT KeyDC4 = ^T CtrlT
|
||||
21 1 KeyCtrlU KeyNAK = ^U CtrlU
|
||||
22 1 KeyCtrlV KeySYN = ^V CtrlV
|
||||
23 1 KeyCtrlW KeyETB = ^W CtrlW
|
||||
24 1 KeyCtrlX KeyCAN = ^X CtrlX
|
||||
25 1 KeyCtrlY KeyEM = ^Y CtrlY
|
||||
26 1 KeyCtrlZ KeySUB = ^Z CtrlZ
|
||||
27 7 KeyCtrlLeftSq KeyESC = ^[ KeyEsc, KeyEscape ESC
|
||||
28 2 KeyCtrlBackslash KeyFS = ^\ CtrlSpace
|
||||
29 2 KeyCtrlRightSq KeyGS = ^] CtrlBackSlash
|
||||
30 2 KeyCtrlCarat KeyRS = ^^ CtrlRightBracket
|
||||
31 2 KeyCtrlUnderscore KeyUS = ^_ CtrlCaret
|
||||
32 CtrlSlash
|
||||
33 Invalid
|
||||
34 Resize
|
||||
35 Mouse
|
||||
36 DoubleClick
|
||||
37 LeftClick
|
||||
38 RightClick
|
||||
39 BTab
|
||||
40 BSpace
|
||||
41 Del
|
||||
42 PgUp
|
||||
43 PgDn
|
||||
44 Up
|
||||
45 Down
|
||||
46 Left
|
||||
47 Right
|
||||
48 Home
|
||||
49 End
|
||||
50 Insert
|
||||
51 SUp
|
||||
52 SDown
|
||||
53 SLeft
|
||||
54 SRight
|
||||
55 F1
|
||||
56 F2
|
||||
57 F3
|
||||
58 F4
|
||||
59 F5
|
||||
60 F6
|
||||
61 F7
|
||||
62 F8
|
||||
63 F9
|
||||
64 F10
|
||||
65 F11
|
||||
66 F12
|
||||
67 Change
|
||||
68 BackwardEOF
|
||||
69 AltBS
|
||||
70 AltUp
|
||||
71 AltDown
|
||||
72 AltLeft
|
||||
73 AltRight
|
||||
74 AltSUp
|
||||
75 AltSDown
|
||||
76 AltSLeft
|
||||
77 AltSRight
|
||||
78 Alt
|
||||
79 CtrlAlt
|
||||
..
|
||||
127 3 KeyDEL KeyBackspace2
|
||||
..
|
||||
256 6 KeyRune
|
||||
257 4 KeyUp
|
||||
258 4 KeyDown
|
||||
259 4 KeyRight
|
||||
260 4 KeyLeft
|
||||
261 8 KeyUpLeft
|
||||
262 8 KeyUpRight
|
||||
263 8 KeyDownLeft
|
||||
264 8 KeyDownRight
|
||||
265 8 KeyCenter
|
||||
266 5 KeyPgUp
|
||||
267 5 KeyPgDn
|
||||
268 5 KeyHome
|
||||
269 5 KeyEnd
|
||||
270 5 KeyInsert
|
||||
271 5 KeyDelete
|
||||
272 8 KeyHelp
|
||||
273 8 KeyExit
|
||||
274 8 KeyClear
|
||||
275 8 KeyCancel
|
||||
276 8 KeyPrint
|
||||
277 8 KeyPause
|
||||
278 5 KeyBacktab
|
||||
279 5 KeyF1
|
||||
280 5 KeyF2
|
||||
281 5 KeyF3
|
||||
282 5 KeyF4
|
||||
283 5 KeyF5
|
||||
284 5 KeyF6
|
||||
285 5 KeyF7
|
||||
286 5 KeyF8
|
||||
287 5 KeyF9
|
||||
288 5 KeyF10
|
||||
289 5 KeyF11
|
||||
290 5 KeyF12
|
||||
291 8 KeyF13
|
||||
292 8 KeyF14
|
||||
293 8 KeyF15
|
||||
294 8 KeyF16
|
||||
295 8 KeyF17
|
||||
296 8 KeyF18
|
||||
297 8 KeyF19
|
||||
298 8 KeyF20
|
||||
299 8 KeyF21
|
||||
300 8 KeyF22
|
||||
301 8 KeyF23
|
||||
302 8 KeyF24
|
||||
303 8 KeyF25
|
||||
304 8 KeyF26
|
||||
305 8 KeyF27
|
||||
306 8 KeyF28
|
||||
307 8 KeyF29
|
||||
308 8 KeyF30
|
||||
309 8 KeyF31
|
||||
310 8 KeyF32
|
||||
311 8 KeyF33
|
||||
312 8 KeyF34
|
||||
313 8 KeyF35
|
||||
314 8 KeyF36
|
||||
315 8 KeyF37
|
||||
316 8 KeyF38
|
||||
317 8 KeyF39
|
||||
318 8 KeyF40
|
||||
319 8 KeyF41
|
||||
320 8 KeyF42
|
||||
321 8 KeyF43
|
||||
322 8 KeyF44
|
||||
323 8 KeyF45
|
||||
324 8 KeyF46
|
||||
325 8 KeyF47
|
||||
326 8 KeyF48
|
||||
327 8 KeyF49
|
||||
328 8 KeyF50
|
||||
329 8 KeyF51
|
||||
330 8 KeyF52
|
||||
331 8 KeyF53
|
||||
332 8 KeyF54
|
||||
333 8 KeyF55
|
||||
334 8 KeyF56
|
||||
335 8 KeyF57
|
||||
336 8 KeyF58
|
||||
337 8 KeyF59
|
||||
338 8 KeyF60
|
||||
339 8 KeyF61
|
||||
340 8 KeyF62
|
||||
341 8 KeyF63
|
||||
342 8 KeyF64
|
||||
-- --------- -------------- --------------- ----------- ------------- ---------------- ----------
|
||||
%v section # tcell ctrl key tcell ctrl char tcell alias tui constants tcell named keys tcell mods
|
||||
*/
|
||||
@ -1,47 +0,0 @@
|
||||
// +build !windows
|
||||
|
||||
package tui
|
||||
|
||||
import (
|
||||
"io/ioutil"
|
||||
"os"
|
||||
"syscall"
|
||||
)
|
||||
|
||||
var devPrefixes = [...]string{"/dev/pts/", "/dev/"}
|
||||
|
||||
func ttyname() string {
|
||||
var stderr syscall.Stat_t
|
||||
if syscall.Fstat(2, &stderr) != nil {
|
||||
return ""
|
||||
}
|
||||
|
||||
for _, prefix := range devPrefixes {
|
||||
files, err := ioutil.ReadDir(prefix)
|
||||
if err != nil {
|
||||
continue
|
||||
}
|
||||
|
||||
for _, file := range files {
|
||||
if stat, ok := file.Sys().(*syscall.Stat_t); ok && stat.Rdev == stderr.Rdev {
|
||||
return prefix + file.Name()
|
||||
}
|
||||
}
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
// TtyIn returns terminal device to be used as STDIN, falls back to os.Stdin
|
||||
func TtyIn() *os.File {
|
||||
in, err := os.OpenFile(consoleDevice, syscall.O_RDONLY, 0)
|
||||
if err != nil {
|
||||
tty := ttyname()
|
||||
if len(tty) > 0 {
|
||||
if in, err := os.OpenFile(tty, syscall.O_RDONLY, 0); err == nil {
|
||||
return in
|
||||
}
|
||||
}
|
||||
return os.Stdin
|
||||
}
|
||||
return in
|
||||
}
|
||||
@ -1,14 +0,0 @@
|
||||
// +build windows
|
||||
|
||||
package tui
|
||||
|
||||
import "os"
|
||||
|
||||
func ttyname() string {
|
||||
return ""
|
||||
}
|
||||
|
||||
// TtyIn on Windows returns os.Stdin
|
||||
func TtyIn() *os.File {
|
||||
return os.Stdin
|
||||
}
|
||||
@ -1,625 +0,0 @@
|
||||
package tui
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"strconv"
|
||||
"time"
|
||||
)
|
||||
|
||||
// Types of user action
|
||||
type EventType int
|
||||
|
||||
const (
|
||||
Rune EventType = iota
|
||||
|
||||
CtrlA
|
||||
CtrlB
|
||||
CtrlC
|
||||
CtrlD
|
||||
CtrlE
|
||||
CtrlF
|
||||
CtrlG
|
||||
CtrlH
|
||||
Tab
|
||||
CtrlJ
|
||||
CtrlK
|
||||
CtrlL
|
||||
CtrlM
|
||||
CtrlN
|
||||
CtrlO
|
||||
CtrlP
|
||||
CtrlQ
|
||||
CtrlR
|
||||
CtrlS
|
||||
CtrlT
|
||||
CtrlU
|
||||
CtrlV
|
||||
CtrlW
|
||||
CtrlX
|
||||
CtrlY
|
||||
CtrlZ
|
||||
ESC
|
||||
CtrlSpace
|
||||
|
||||
// https://apple.stackexchange.com/questions/24261/how-do-i-send-c-that-is-control-slash-to-the-terminal
|
||||
CtrlBackSlash
|
||||
CtrlRightBracket
|
||||
CtrlCaret
|
||||
CtrlSlash
|
||||
|
||||
Invalid
|
||||
Resize
|
||||
Mouse
|
||||
DoubleClick
|
||||
LeftClick
|
||||
RightClick
|
||||
|
||||
BTab
|
||||
BSpace
|
||||
|
||||
Del
|
||||
PgUp
|
||||
PgDn
|
||||
|
||||
Up
|
||||
Down
|
||||
Left
|
||||
Right
|
||||
Home
|
||||
End
|
||||
Insert
|
||||
|
||||
SUp
|
||||
SDown
|
||||
SLeft
|
||||
SRight
|
||||
|
||||
F1
|
||||
F2
|
||||
F3
|
||||
F4
|
||||
F5
|
||||
F6
|
||||
F7
|
||||
F8
|
||||
F9
|
||||
F10
|
||||
F11
|
||||
F12
|
||||
|
||||
Change
|
||||
BackwardEOF
|
||||
|
||||
AltBS
|
||||
|
||||
AltUp
|
||||
AltDown
|
||||
AltLeft
|
||||
AltRight
|
||||
|
||||
AltSUp
|
||||
AltSDown
|
||||
AltSLeft
|
||||
AltSRight
|
||||
|
||||
Alt
|
||||
CtrlAlt
|
||||
)
|
||||
|
||||
func (t EventType) AsEvent() Event {
|
||||
return Event{t, 0, nil}
|
||||
}
|
||||
|
||||
func (t EventType) Int() int {
|
||||
return int(t)
|
||||
}
|
||||
|
||||
func (t EventType) Byte() byte {
|
||||
return byte(t)
|
||||
}
|
||||
|
||||
func (e Event) Comparable() Event {
|
||||
// Ignore MouseEvent pointer
|
||||
return Event{e.Type, e.Char, nil}
|
||||
}
|
||||
|
||||
func Key(r rune) Event {
|
||||
return Event{Rune, r, nil}
|
||||
}
|
||||
|
||||
func AltKey(r rune) Event {
|
||||
return Event{Alt, r, nil}
|
||||
}
|
||||
|
||||
func CtrlAltKey(r rune) Event {
|
||||
return Event{CtrlAlt, r, nil}
|
||||
}
|
||||
|
||||
const (
|
||||
doubleClickDuration = 500 * time.Millisecond
|
||||
)
|
||||
|
||||
type Color int32
|
||||
|
||||
func (c Color) IsDefault() bool {
|
||||
return c == colDefault
|
||||
}
|
||||
|
||||
func (c Color) is24() bool {
|
||||
return c > 0 && (c&(1<<24)) > 0
|
||||
}
|
||||
|
||||
type ColorAttr struct {
|
||||
Color Color
|
||||
Attr Attr
|
||||
}
|
||||
|
||||
func NewColorAttr() ColorAttr {
|
||||
return ColorAttr{Color: colUndefined, Attr: AttrUndefined}
|
||||
}
|
||||
|
||||
const (
|
||||
colUndefined Color = -2
|
||||
colDefault Color = -1
|
||||
)
|
||||
|
||||
const (
|
||||
colBlack Color = iota
|
||||
colRed
|
||||
colGreen
|
||||
colYellow
|
||||
colBlue
|
||||
colMagenta
|
||||
colCyan
|
||||
colWhite
|
||||
)
|
||||
|
||||
type FillReturn int
|
||||
|
||||
const (
|
||||
FillContinue FillReturn = iota
|
||||
FillNextLine
|
||||
FillSuspend
|
||||
)
|
||||
|
||||
type ColorPair struct {
|
||||
fg Color
|
||||
bg Color
|
||||
attr Attr
|
||||
}
|
||||
|
||||
func HexToColor(rrggbb string) Color {
|
||||
r, _ := strconv.ParseInt(rrggbb[1:3], 16, 0)
|
||||
g, _ := strconv.ParseInt(rrggbb[3:5], 16, 0)
|
||||
b, _ := strconv.ParseInt(rrggbb[5:7], 16, 0)
|
||||
return Color((1 << 24) + (r << 16) + (g << 8) + b)
|
||||
}
|
||||
|
||||
func NewColorPair(fg Color, bg Color, attr Attr) ColorPair {
|
||||
return ColorPair{fg, bg, attr}
|
||||
}
|
||||
|
||||
func (p ColorPair) Fg() Color {
|
||||
return p.fg
|
||||
}
|
||||
|
||||
func (p ColorPair) Bg() Color {
|
||||
return p.bg
|
||||
}
|
||||
|
||||
func (p ColorPair) Attr() Attr {
|
||||
return p.attr
|
||||
}
|
||||
|
||||
func (p ColorPair) HasBg() bool {
|
||||
return p.attr&Reverse == 0 && p.bg != colDefault ||
|
||||
p.attr&Reverse > 0 && p.fg != colDefault
|
||||
}
|
||||
|
||||
func (p ColorPair) merge(other ColorPair, except Color) ColorPair {
|
||||
dup := p
|
||||
dup.attr = dup.attr.Merge(other.attr)
|
||||
if other.fg != except {
|
||||
dup.fg = other.fg
|
||||
}
|
||||
if other.bg != except {
|
||||
dup.bg = other.bg
|
||||
}
|
||||
return dup
|
||||
}
|
||||
|
||||
func (p ColorPair) WithAttr(attr Attr) ColorPair {
|
||||
dup := p
|
||||
dup.attr = dup.attr.Merge(attr)
|
||||
return dup
|
||||
}
|
||||
|
||||
func (p ColorPair) MergeAttr(other ColorPair) ColorPair {
|
||||
return p.WithAttr(other.attr)
|
||||
}
|
||||
|
||||
func (p ColorPair) Merge(other ColorPair) ColorPair {
|
||||
return p.merge(other, colUndefined)
|
||||
}
|
||||
|
||||
func (p ColorPair) MergeNonDefault(other ColorPair) ColorPair {
|
||||
return p.merge(other, colDefault)
|
||||
}
|
||||
|
||||
type ColorTheme struct {
|
||||
Colored bool
|
||||
Input ColorAttr
|
||||
Disabled ColorAttr
|
||||
Fg ColorAttr
|
||||
Bg ColorAttr
|
||||
PreviewFg ColorAttr
|
||||
PreviewBg ColorAttr
|
||||
DarkBg ColorAttr
|
||||
Gutter ColorAttr
|
||||
Prompt ColorAttr
|
||||
Match ColorAttr
|
||||
Current ColorAttr
|
||||
CurrentMatch ColorAttr
|
||||
Spinner ColorAttr
|
||||
Info ColorAttr
|
||||
Cursor ColorAttr
|
||||
Selected ColorAttr
|
||||
Header ColorAttr
|
||||
Border ColorAttr
|
||||
}
|
||||
|
||||
type Event struct {
|
||||
Type EventType
|
||||
Char rune
|
||||
MouseEvent *MouseEvent
|
||||
}
|
||||
|
||||
type MouseEvent struct {
|
||||
Y int
|
||||
X int
|
||||
S int
|
||||
Left bool
|
||||
Down bool
|
||||
Double bool
|
||||
Mod bool
|
||||
}
|
||||
|
||||
type BorderShape int
|
||||
|
||||
const (
|
||||
BorderNone BorderShape = iota
|
||||
BorderRounded
|
||||
BorderSharp
|
||||
BorderHorizontal
|
||||
BorderVertical
|
||||
BorderTop
|
||||
BorderBottom
|
||||
BorderLeft
|
||||
BorderRight
|
||||
)
|
||||
|
||||
type BorderStyle struct {
|
||||
shape BorderShape
|
||||
horizontal rune
|
||||
vertical rune
|
||||
topLeft rune
|
||||
topRight rune
|
||||
bottomLeft rune
|
||||
bottomRight rune
|
||||
}
|
||||
|
||||
type BorderCharacter int
|
||||
|
||||
func MakeBorderStyle(shape BorderShape, unicode bool) BorderStyle {
|
||||
if unicode {
|
||||
if shape == BorderRounded {
|
||||
return BorderStyle{
|
||||
shape: shape,
|
||||
horizontal: '─',
|
||||
vertical: '│',
|
||||
topLeft: '╭',
|
||||
topRight: '╮',
|
||||
bottomLeft: '╰',
|
||||
bottomRight: '╯',
|
||||
}
|
||||
}
|
||||
return BorderStyle{
|
||||
shape: shape,
|
||||
horizontal: '─',
|
||||
vertical: '│',
|
||||
topLeft: '┌',
|
||||
topRight: '┐',
|
||||
bottomLeft: '└',
|
||||
bottomRight: '┘',
|
||||
}
|
||||
}
|
||||
return BorderStyle{
|
||||
shape: shape,
|
||||
horizontal: '-',
|
||||
vertical: '|',
|
||||
topLeft: '+',
|
||||
topRight: '+',
|
||||
bottomLeft: '+',
|
||||
bottomRight: '+',
|
||||
}
|
||||
}
|
||||
|
||||
func MakeTransparentBorder() BorderStyle {
|
||||
return BorderStyle{
|
||||
shape: BorderRounded,
|
||||
horizontal: ' ',
|
||||
vertical: ' ',
|
||||
topLeft: ' ',
|
||||
topRight: ' ',
|
||||
bottomLeft: ' ',
|
||||
bottomRight: ' '}
|
||||
}
|
||||
|
||||
type Renderer interface {
|
||||
Init()
|
||||
Pause(clear bool)
|
||||
Resume(clear bool, sigcont bool)
|
||||
Clear()
|
||||
RefreshWindows(windows []Window)
|
||||
Refresh()
|
||||
Close()
|
||||
|
||||
GetChar() Event
|
||||
|
||||
MaxX() int
|
||||
MaxY() int
|
||||
|
||||
NewWindow(top int, left int, width int, height int, preview bool, borderStyle BorderStyle) Window
|
||||
}
|
||||
|
||||
type Window interface {
|
||||
Top() int
|
||||
Left() int
|
||||
Width() int
|
||||
Height() int
|
||||
|
||||
Refresh()
|
||||
FinishFill()
|
||||
Close()
|
||||
|
||||
X() int
|
||||
Y() int
|
||||
Enclose(y int, x int) bool
|
||||
|
||||
Move(y int, x int)
|
||||
MoveAndClear(y int, x int)
|
||||
Print(text string)
|
||||
CPrint(color ColorPair, text string)
|
||||
Fill(text string) FillReturn
|
||||
CFill(fg Color, bg Color, attr Attr, text string) FillReturn
|
||||
Erase()
|
||||
}
|
||||
|
||||
type FullscreenRenderer struct {
|
||||
theme *ColorTheme
|
||||
mouse bool
|
||||
forceBlack bool
|
||||
prevDownTime time.Time
|
||||
clickY []int
|
||||
}
|
||||
|
||||
func NewFullscreenRenderer(theme *ColorTheme, forceBlack bool, mouse bool) Renderer {
|
||||
r := &FullscreenRenderer{
|
||||
theme: theme,
|
||||
mouse: mouse,
|
||||
forceBlack: forceBlack,
|
||||
prevDownTime: time.Unix(0, 0),
|
||||
clickY: []int{}}
|
||||
return r
|
||||
}
|
||||
|
||||
var (
|
||||
Default16 *ColorTheme
|
||||
Dark256 *ColorTheme
|
||||
Light256 *ColorTheme
|
||||
|
||||
ColPrompt ColorPair
|
||||
ColNormal ColorPair
|
||||
ColInput ColorPair
|
||||
ColDisabled ColorPair
|
||||
ColMatch ColorPair
|
||||
ColCursor ColorPair
|
||||
ColCursorEmpty ColorPair
|
||||
ColSelected ColorPair
|
||||
ColCurrent ColorPair
|
||||
ColCurrentMatch ColorPair
|
||||
ColCurrentCursor ColorPair
|
||||
ColCurrentCursorEmpty ColorPair
|
||||
ColCurrentSelected ColorPair
|
||||
ColCurrentSelectedEmpty ColorPair
|
||||
ColSpinner ColorPair
|
||||
ColInfo ColorPair
|
||||
ColHeader ColorPair
|
||||
ColBorder ColorPair
|
||||
ColPreview ColorPair
|
||||
ColPreviewBorder ColorPair
|
||||
)
|
||||
|
||||
func EmptyTheme() *ColorTheme {
|
||||
return &ColorTheme{
|
||||
Colored: true,
|
||||
Input: ColorAttr{colUndefined, AttrUndefined},
|
||||
Disabled: ColorAttr{colUndefined, AttrUndefined},
|
||||
Fg: ColorAttr{colUndefined, AttrUndefined},
|
||||
Bg: ColorAttr{colUndefined, AttrUndefined},
|
||||
PreviewFg: ColorAttr{colUndefined, AttrUndefined},
|
||||
PreviewBg: ColorAttr{colUndefined, AttrUndefined},
|
||||
DarkBg: ColorAttr{colUndefined, AttrUndefined},
|
||||
Gutter: ColorAttr{colUndefined, AttrUndefined},
|
||||
Prompt: ColorAttr{colUndefined, AttrUndefined},
|
||||
Match: ColorAttr{colUndefined, AttrUndefined},
|
||||
Current: ColorAttr{colUndefined, AttrUndefined},
|
||||
CurrentMatch: ColorAttr{colUndefined, AttrUndefined},
|
||||
Spinner: ColorAttr{colUndefined, AttrUndefined},
|
||||
Info: ColorAttr{colUndefined, AttrUndefined},
|
||||
Cursor: ColorAttr{colUndefined, AttrUndefined},
|
||||
Selected: ColorAttr{colUndefined, AttrUndefined},
|
||||
Header: ColorAttr{colUndefined, AttrUndefined},
|
||||
Border: ColorAttr{colUndefined, AttrUndefined}}
|
||||
}
|
||||
|
||||
func NoColorTheme() *ColorTheme {
|
||||
return &ColorTheme{
|
||||
Colored: false,
|
||||
Input: ColorAttr{colDefault, AttrRegular},
|
||||
Disabled: ColorAttr{colDefault, AttrRegular},
|
||||
Fg: ColorAttr{colDefault, AttrRegular},
|
||||
Bg: ColorAttr{colDefault, AttrRegular},
|
||||
PreviewFg: ColorAttr{colDefault, AttrRegular},
|
||||
PreviewBg: ColorAttr{colDefault, AttrRegular},
|
||||
DarkBg: ColorAttr{colDefault, AttrRegular},
|
||||
Gutter: ColorAttr{colDefault, AttrRegular},
|
||||
Prompt: ColorAttr{colDefault, AttrRegular},
|
||||
Match: ColorAttr{colDefault, Underline},
|
||||
Current: ColorAttr{colDefault, Reverse},
|
||||
CurrentMatch: ColorAttr{colDefault, Reverse | Underline},
|
||||
Spinner: ColorAttr{colDefault, AttrRegular},
|
||||
Info: ColorAttr{colDefault, AttrRegular},
|
||||
Cursor: ColorAttr{colDefault, AttrRegular},
|
||||
Selected: ColorAttr{colDefault, AttrRegular},
|
||||
Header: ColorAttr{colDefault, AttrRegular},
|
||||
Border: ColorAttr{colDefault, AttrRegular}}
|
||||
}
|
||||
|
||||
func errorExit(message string) {
|
||||
fmt.Fprintln(os.Stderr, message)
|
||||
os.Exit(2)
|
||||
}
|
||||
|
||||
func init() {
|
||||
Default16 = &ColorTheme{
|
||||
Colored: true,
|
||||
Input: ColorAttr{colDefault, AttrUndefined},
|
||||
Disabled: ColorAttr{colUndefined, AttrUndefined},
|
||||
Fg: ColorAttr{colDefault, AttrUndefined},
|
||||
Bg: ColorAttr{colDefault, AttrUndefined},
|
||||
PreviewFg: ColorAttr{colUndefined, AttrUndefined},
|
||||
PreviewBg: ColorAttr{colUndefined, AttrUndefined},
|
||||
DarkBg: ColorAttr{colBlack, AttrUndefined},
|
||||
Gutter: ColorAttr{colUndefined, AttrUndefined},
|
||||
Prompt: ColorAttr{colBlue, AttrUndefined},
|
||||
Match: ColorAttr{colGreen, AttrUndefined},
|
||||
Current: ColorAttr{colYellow, AttrUndefined},
|
||||
CurrentMatch: ColorAttr{colGreen, AttrUndefined},
|
||||
Spinner: ColorAttr{colGreen, AttrUndefined},
|
||||
Info: ColorAttr{colWhite, AttrUndefined},
|
||||
Cursor: ColorAttr{colRed, AttrUndefined},
|
||||
Selected: ColorAttr{colMagenta, AttrUndefined},
|
||||
Header: ColorAttr{colCyan, AttrUndefined},
|
||||
Border: ColorAttr{colBlack, AttrUndefined}}
|
||||
Dark256 = &ColorTheme{
|
||||
Colored: true,
|
||||
Input: ColorAttr{colDefault, AttrUndefined},
|
||||
Disabled: ColorAttr{colUndefined, AttrUndefined},
|
||||
Fg: ColorAttr{colDefault, AttrUndefined},
|
||||
Bg: ColorAttr{colDefault, AttrUndefined},
|
||||
PreviewFg: ColorAttr{colUndefined, AttrUndefined},
|
||||
PreviewBg: ColorAttr{colUndefined, AttrUndefined},
|
||||
DarkBg: ColorAttr{236, AttrUndefined},
|
||||
Gutter: ColorAttr{colUndefined, AttrUndefined},
|
||||
Prompt: ColorAttr{110, AttrUndefined},
|
||||
Match: ColorAttr{108, AttrUndefined},
|
||||
Current: ColorAttr{254, AttrUndefined},
|
||||
CurrentMatch: ColorAttr{151, AttrUndefined},
|
||||
Spinner: ColorAttr{148, AttrUndefined},
|
||||
Info: ColorAttr{144, AttrUndefined},
|
||||
Cursor: ColorAttr{161, AttrUndefined},
|
||||
Selected: ColorAttr{168, AttrUndefined},
|
||||
Header: ColorAttr{109, AttrUndefined},
|
||||
Border: ColorAttr{59, AttrUndefined}}
|
||||
Light256 = &ColorTheme{
|
||||
Colored: true,
|
||||
Input: ColorAttr{colDefault, AttrUndefined},
|
||||
Disabled: ColorAttr{colUndefined, AttrUndefined},
|
||||
Fg: ColorAttr{colDefault, AttrUndefined},
|
||||
Bg: ColorAttr{colDefault, AttrUndefined},
|
||||
PreviewFg: ColorAttr{colUndefined, AttrUndefined},
|
||||
PreviewBg: ColorAttr{colUndefined, AttrUndefined},
|
||||
DarkBg: ColorAttr{251, AttrUndefined},
|
||||
Gutter: ColorAttr{colUndefined, AttrUndefined},
|
||||
Prompt: ColorAttr{25, AttrUndefined},
|
||||
Match: ColorAttr{66, AttrUndefined},
|
||||
Current: ColorAttr{237, AttrUndefined},
|
||||
CurrentMatch: ColorAttr{23, AttrUndefined},
|
||||
Spinner: ColorAttr{65, AttrUndefined},
|
||||
Info: ColorAttr{101, AttrUndefined},
|
||||
Cursor: ColorAttr{161, AttrUndefined},
|
||||
Selected: ColorAttr{168, AttrUndefined},
|
||||
Header: ColorAttr{31, AttrUndefined},
|
||||
Border: ColorAttr{145, AttrUndefined}}
|
||||
}
|
||||
|
||||
func initTheme(theme *ColorTheme, baseTheme *ColorTheme, forceBlack bool) {
|
||||
if forceBlack {
|
||||
theme.Bg = ColorAttr{colBlack, AttrUndefined}
|
||||
}
|
||||
|
||||
o := func(a ColorAttr, b ColorAttr) ColorAttr {
|
||||
c := a
|
||||
if b.Color != colUndefined {
|
||||
c.Color = b.Color
|
||||
}
|
||||
if b.Attr != AttrUndefined {
|
||||
c.Attr = b.Attr
|
||||
}
|
||||
return c
|
||||
}
|
||||
theme.Input = o(baseTheme.Input, theme.Input)
|
||||
theme.Disabled = o(theme.Input, o(baseTheme.Disabled, theme.Disabled))
|
||||
theme.Fg = o(baseTheme.Fg, theme.Fg)
|
||||
theme.Bg = o(baseTheme.Bg, theme.Bg)
|
||||
theme.PreviewFg = o(theme.Fg, o(baseTheme.PreviewFg, theme.PreviewFg))
|
||||
theme.PreviewBg = o(theme.Bg, o(baseTheme.PreviewBg, theme.PreviewBg))
|
||||
theme.DarkBg = o(baseTheme.DarkBg, theme.DarkBg)
|
||||
theme.Gutter = o(theme.DarkBg, o(baseTheme.Gutter, theme.Gutter))
|
||||
theme.Prompt = o(baseTheme.Prompt, theme.Prompt)
|
||||
theme.Match = o(baseTheme.Match, theme.Match)
|
||||
theme.Current = o(baseTheme.Current, theme.Current)
|
||||
theme.CurrentMatch = o(baseTheme.CurrentMatch, theme.CurrentMatch)
|
||||
theme.Spinner = o(baseTheme.Spinner, theme.Spinner)
|
||||
theme.Info = o(baseTheme.Info, theme.Info)
|
||||
theme.Cursor = o(baseTheme.Cursor, theme.Cursor)
|
||||
theme.Selected = o(baseTheme.Selected, theme.Selected)
|
||||
theme.Header = o(baseTheme.Header, theme.Header)
|
||||
theme.Border = o(baseTheme.Border, theme.Border)
|
||||
|
||||
initPalette(theme)
|
||||
}
|
||||
|
||||
func initPalette(theme *ColorTheme) {
|
||||
pair := func(fg, bg ColorAttr) ColorPair {
|
||||
if fg.Color == colDefault && (fg.Attr&Reverse) > 0 {
|
||||
bg.Color = colDefault
|
||||
}
|
||||
return ColorPair{fg.Color, bg.Color, fg.Attr}
|
||||
}
|
||||
blank := theme.Fg
|
||||
blank.Attr = AttrRegular
|
||||
|
||||
ColPrompt = pair(theme.Prompt, theme.Bg)
|
||||
ColNormal = pair(theme.Fg, theme.Bg)
|
||||
ColInput = pair(theme.Input, theme.Bg)
|
||||
ColDisabled = pair(theme.Disabled, theme.Bg)
|
||||
ColMatch = pair(theme.Match, theme.Bg)
|
||||
ColCursor = pair(theme.Cursor, theme.Gutter)
|
||||
ColCursorEmpty = pair(blank, theme.Gutter)
|
||||
ColSelected = pair(theme.Selected, theme.Gutter)
|
||||
ColCurrent = pair(theme.Current, theme.DarkBg)
|
||||
ColCurrentMatch = pair(theme.CurrentMatch, theme.DarkBg)
|
||||
ColCurrentCursor = pair(theme.Cursor, theme.DarkBg)
|
||||
ColCurrentCursorEmpty = pair(blank, theme.DarkBg)
|
||||
ColCurrentSelected = pair(theme.Selected, theme.DarkBg)
|
||||
ColCurrentSelectedEmpty = pair(blank, theme.DarkBg)
|
||||
ColSpinner = pair(theme.Spinner, theme.Bg)
|
||||
ColInfo = pair(theme.Info, theme.Bg)
|
||||
ColHeader = pair(theme.Header, theme.Bg)
|
||||
ColBorder = pair(theme.Border, theme.Bg)
|
||||
ColPreview = pair(theme.PreviewFg, theme.PreviewBg)
|
||||
ColPreviewBorder = pair(theme.Border, theme.PreviewBg)
|
||||
}
|
||||
@ -1,20 +0,0 @@
|
||||
package tui
|
||||
|
||||
import "testing"
|
||||
|
||||
func TestHexToColor(t *testing.T) {
|
||||
assert := func(expr string, r, g, b int) {
|
||||
color := HexToColor(expr)
|
||||
if !color.is24() ||
|
||||
int((color>>16)&0xff) != r ||
|
||||
int((color>>8)&0xff) != g ||
|
||||
int((color)&0xff) != b {
|
||||
t.Fail()
|
||||
}
|
||||
}
|
||||
|
||||
assert("#ff0000", 255, 0, 0)
|
||||
assert("#010203", 1, 2, 3)
|
||||
assert("#102030", 16, 32, 48)
|
||||
assert("#ffffff", 255, 255, 255)
|
||||
}
|
||||
@ -1,34 +0,0 @@
|
||||
package util
|
||||
|
||||
import (
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
func convertBoolToInt32(b bool) int32 {
|
||||
if b {
|
||||
return 1
|
||||
}
|
||||
return 0
|
||||
}
|
||||
|
||||
// AtomicBool is a boxed-class that provides synchronized access to the
|
||||
// underlying boolean value
|
||||
type AtomicBool struct {
|
||||
state int32 // "1" is true, "0" is false
|
||||
}
|
||||
|
||||
// NewAtomicBool returns a new AtomicBool
|
||||
func NewAtomicBool(initialState bool) *AtomicBool {
|
||||
return &AtomicBool{state: convertBoolToInt32(initialState)}
|
||||
}
|
||||
|
||||
// Get returns the current boolean value synchronously
|
||||
func (a *AtomicBool) Get() bool {
|
||||
return atomic.LoadInt32(&a.state) == 1
|
||||
}
|
||||
|
||||
// Set updates the boolean value synchronously
|
||||
func (a *AtomicBool) Set(newState bool) bool {
|
||||
atomic.StoreInt32(&a.state, convertBoolToInt32(newState))
|
||||
return newState
|
||||
}
|
||||
@ -1,17 +0,0 @@
|
||||
package util
|
||||
|
||||
import "testing"
|
||||
|
||||
func TestAtomicBool(t *testing.T) {
|
||||
if !NewAtomicBool(true).Get() || NewAtomicBool(false).Get() {
|
||||
t.Error("Invalid initial value")
|
||||
}
|
||||
|
||||
ab := NewAtomicBool(true)
|
||||
if ab.Set(false) {
|
||||
t.Error("Invalid return value")
|
||||
}
|
||||
if ab.Get() {
|
||||
t.Error("Invalid state")
|
||||
}
|
||||
}
|
||||
@ -1,198 +0,0 @@
|
||||
package util
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
"unsafe"
|
||||
)
|
||||
|
||||
const (
|
||||
overflow64 uint64 = 0x8080808080808080
|
||||
overflow32 uint32 = 0x80808080
|
||||
)
|
||||
|
||||
type Chars struct {
|
||||
slice []byte // or []rune
|
||||
inBytes bool
|
||||
trimLengthKnown bool
|
||||
trimLength uint16
|
||||
|
||||
// XXX Piggybacking item index here is a horrible idea. But I'm trying to
|
||||
// minimize the memory footprint by not wasting padded spaces.
|
||||
Index int32
|
||||
}
|
||||
|
||||
func checkAscii(bytes []byte) (bool, int) {
|
||||
i := 0
|
||||
for ; i <= len(bytes)-8; i += 8 {
|
||||
if (overflow64 & *(*uint64)(unsafe.Pointer(&bytes[i]))) > 0 {
|
||||
return false, i
|
||||
}
|
||||
}
|
||||
for ; i <= len(bytes)-4; i += 4 {
|
||||
if (overflow32 & *(*uint32)(unsafe.Pointer(&bytes[i]))) > 0 {
|
||||
return false, i
|
||||
}
|
||||
}
|
||||
for ; i < len(bytes); i++ {
|
||||
if bytes[i] >= utf8.RuneSelf {
|
||||
return false, i
|
||||
}
|
||||
}
|
||||
return true, 0
|
||||
}
|
||||
|
||||
// ToChars converts byte array into rune array
|
||||
func ToChars(bytes []byte) Chars {
|
||||
inBytes, bytesUntil := checkAscii(bytes)
|
||||
if inBytes {
|
||||
return Chars{slice: bytes, inBytes: inBytes}
|
||||
}
|
||||
|
||||
runes := make([]rune, bytesUntil, len(bytes))
|
||||
for i := 0; i < bytesUntil; i++ {
|
||||
runes[i] = rune(bytes[i])
|
||||
}
|
||||
for i := bytesUntil; i < len(bytes); {
|
||||
r, sz := utf8.DecodeRune(bytes[i:])
|
||||
i += sz
|
||||
runes = append(runes, r)
|
||||
}
|
||||
return RunesToChars(runes)
|
||||
}
|
||||
|
||||
func RunesToChars(runes []rune) Chars {
|
||||
return Chars{slice: *(*[]byte)(unsafe.Pointer(&runes)), inBytes: false}
|
||||
}
|
||||
|
||||
func (chars *Chars) IsBytes() bool {
|
||||
return chars.inBytes
|
||||
}
|
||||
|
||||
func (chars *Chars) Bytes() []byte {
|
||||
return chars.slice
|
||||
}
|
||||
|
||||
func (chars *Chars) optionalRunes() []rune {
|
||||
if chars.inBytes {
|
||||
return nil
|
||||
}
|
||||
return *(*[]rune)(unsafe.Pointer(&chars.slice))
|
||||
}
|
||||
|
||||
func (chars *Chars) Get(i int) rune {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
return runes[i]
|
||||
}
|
||||
return rune(chars.slice[i])
|
||||
}
|
||||
|
||||
func (chars *Chars) Length() int {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
return len(runes)
|
||||
}
|
||||
return len(chars.slice)
|
||||
}
|
||||
|
||||
// String returns the string representation of a Chars object.
|
||||
func (chars *Chars) String() string {
|
||||
return fmt.Sprintf("Chars{slice: []byte(%q), inBytes: %v, trimLengthKnown: %v, trimLength: %d, Index: %d}", chars.slice, chars.inBytes, chars.trimLengthKnown, chars.trimLength, chars.Index)
|
||||
}
|
||||
|
||||
// TrimLength returns the length after trimming leading and trailing whitespaces
|
||||
func (chars *Chars) TrimLength() uint16 {
|
||||
if chars.trimLengthKnown {
|
||||
return chars.trimLength
|
||||
}
|
||||
chars.trimLengthKnown = true
|
||||
var i int
|
||||
len := chars.Length()
|
||||
for i = len - 1; i >= 0; i-- {
|
||||
char := chars.Get(i)
|
||||
if !unicode.IsSpace(char) {
|
||||
break
|
||||
}
|
||||
}
|
||||
// Completely empty
|
||||
if i < 0 {
|
||||
return 0
|
||||
}
|
||||
|
||||
var j int
|
||||
for j = 0; j < len; j++ {
|
||||
char := chars.Get(j)
|
||||
if !unicode.IsSpace(char) {
|
||||
break
|
||||
}
|
||||
}
|
||||
chars.trimLength = AsUint16(i - j + 1)
|
||||
return chars.trimLength
|
||||
}
|
||||
|
||||
func (chars *Chars) LeadingWhitespaces() int {
|
||||
whitespaces := 0
|
||||
for i := 0; i < chars.Length(); i++ {
|
||||
char := chars.Get(i)
|
||||
if !unicode.IsSpace(char) {
|
||||
break
|
||||
}
|
||||
whitespaces++
|
||||
}
|
||||
return whitespaces
|
||||
}
|
||||
|
||||
func (chars *Chars) TrailingWhitespaces() int {
|
||||
whitespaces := 0
|
||||
for i := chars.Length() - 1; i >= 0; i-- {
|
||||
char := chars.Get(i)
|
||||
if !unicode.IsSpace(char) {
|
||||
break
|
||||
}
|
||||
whitespaces++
|
||||
}
|
||||
return whitespaces
|
||||
}
|
||||
|
||||
func (chars *Chars) TrimTrailingWhitespaces() {
|
||||
whitespaces := chars.TrailingWhitespaces()
|
||||
chars.slice = chars.slice[0 : len(chars.slice)-whitespaces]
|
||||
}
|
||||
|
||||
func (chars *Chars) ToString() string {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
return string(runes)
|
||||
}
|
||||
return string(chars.slice)
|
||||
}
|
||||
|
||||
func (chars *Chars) ToRunes() []rune {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
return runes
|
||||
}
|
||||
bytes := chars.slice
|
||||
runes := make([]rune, len(bytes))
|
||||
for idx, b := range bytes {
|
||||
runes[idx] = rune(b)
|
||||
}
|
||||
return runes
|
||||
}
|
||||
|
||||
func (chars *Chars) CopyRunes(dest []rune) {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
copy(dest, runes)
|
||||
return
|
||||
}
|
||||
for idx, b := range chars.slice[:len(dest)] {
|
||||
dest[idx] = rune(b)
|
||||
}
|
||||
}
|
||||
|
||||
func (chars *Chars) Prepend(prefix string) {
|
||||
if runes := chars.optionalRunes(); runes != nil {
|
||||
runes = append([]rune(prefix), runes...)
|
||||
chars.slice = *(*[]byte)(unsafe.Pointer(&runes))
|
||||
} else {
|
||||
chars.slice = append([]byte(prefix), chars.slice...)
|
||||
}
|
||||
}
|
||||
@ -1,46 +0,0 @@
|
||||
package util
|
||||
|
||||
import "testing"
|
||||
|
||||
func TestToCharsAscii(t *testing.T) {
|
||||
chars := ToChars([]byte("foobar"))
|
||||
if !chars.inBytes || chars.ToString() != "foobar" || !chars.inBytes {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
|
||||
func TestCharsLength(t *testing.T) {
|
||||
chars := ToChars([]byte("\tabc한글 "))
|
||||
if chars.inBytes || chars.Length() != 8 || chars.TrimLength() != 5 {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
|
||||
func TestCharsToString(t *testing.T) {
|
||||
text := "\tabc한글 "
|
||||
chars := ToChars([]byte(text))
|
||||
if chars.ToString() != text {
|
||||
t.Error()
|
||||
}
|
||||
}
|
||||
|
||||
func TestTrimLength(t *testing.T) {
|
||||
check := func(str string, exp uint16) {
|
||||
chars := ToChars([]byte(str))
|
||||
trimmed := chars.TrimLength()
|
||||
if trimmed != exp {
|
||||
t.Errorf("Invalid TrimLength result for '%s': %d (expected %d)",
|
||||
str, trimmed, exp)
|
||||
}
|
||||
}
|
||||
check("hello", 5)
|
||||
check("hello ", 5)
|
||||
check("hello ", 5)
|
||||
check(" hello", 5)
|
||||
check(" hello", 5)
|
||||
check(" hello ", 5)
|
||||
check(" hello ", 5)
|
||||
check("h o", 5)
|
||||
check(" h o ", 5)
|
||||
check(" ", 0)
|
||||
}
|
||||
@ -1,96 +0,0 @@
|
||||
package util
|
||||
|
||||
import "sync"
|
||||
|
||||
// EventType is the type for fzf events
|
||||
type EventType int
|
||||
|
||||
// Events is a type that associates EventType to any data
|
||||
type Events map[EventType]interface{}
|
||||
|
||||
// EventBox is used for coordinating events
|
||||
type EventBox struct {
|
||||
events Events
|
||||
cond *sync.Cond
|
||||
ignore map[EventType]bool
|
||||
}
|
||||
|
||||
// NewEventBox returns a new EventBox
|
||||
func NewEventBox() *EventBox {
|
||||
return &EventBox{
|
||||
events: make(Events),
|
||||
cond: sync.NewCond(&sync.Mutex{}),
|
||||
ignore: make(map[EventType]bool)}
|
||||
}
|
||||
|
||||
// Wait blocks the goroutine until signaled
|
||||
func (b *EventBox) Wait(callback func(*Events)) {
|
||||
b.cond.L.Lock()
|
||||
|
||||
if len(b.events) == 0 {
|
||||
b.cond.Wait()
|
||||
}
|
||||
|
||||
callback(&b.events)
|
||||
b.cond.L.Unlock()
|
||||
}
|
||||
|
||||
// Set turns on the event type on the box
|
||||
func (b *EventBox) Set(event EventType, value interface{}) {
|
||||
b.cond.L.Lock()
|
||||
b.events[event] = value
|
||||
if _, found := b.ignore[event]; !found {
|
||||
b.cond.Broadcast()
|
||||
}
|
||||
b.cond.L.Unlock()
|
||||
}
|
||||
|
||||
// Clear clears the events
|
||||
// Unsynchronized; should be called within Wait routine
|
||||
func (events *Events) Clear() {
|
||||
for event := range *events {
|
||||
delete(*events, event)
|
||||
}
|
||||
}
|
||||
|
||||
// Peek peeks at the event box if the given event is set
|
||||
func (b *EventBox) Peek(event EventType) bool {
|
||||
b.cond.L.Lock()
|
||||
_, ok := b.events[event]
|
||||
b.cond.L.Unlock()
|
||||
return ok
|
||||
}
|
||||
|
||||
// Watch deletes the events from the ignore list
|
||||
func (b *EventBox) Watch(events ...EventType) {
|
||||
b.cond.L.Lock()
|
||||
for _, event := range events {
|
||||
delete(b.ignore, event)
|
||||
}
|
||||
b.cond.L.Unlock()
|
||||
}
|
||||
|
||||
// Unwatch adds the events to the ignore list
|
||||
func (b *EventBox) Unwatch(events ...EventType) {
|
||||
b.cond.L.Lock()
|
||||
for _, event := range events {
|
||||
b.ignore[event] = true
|
||||
}
|
||||
b.cond.L.Unlock()
|
||||
}
|
||||
|
||||
// WaitFor blocks the execution until the event is received
|
||||
func (b *EventBox) WaitFor(event EventType) {
|
||||
looping := true
|
||||
for looping {
|
||||
b.Wait(func(events *Events) {
|
||||
for evt := range *events {
|
||||
switch evt {
|
||||
case event:
|
||||
looping = false
|
||||
return
|
||||
}
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
@ -1,61 +0,0 @@
|
||||
package util
|
||||
|
||||
import "testing"
|
||||
|
||||
// fzf events
|
||||
const (
|
||||
EvtReadNew EventType = iota
|
||||
EvtReadFin
|
||||
EvtSearchNew
|
||||
EvtSearchProgress
|
||||
EvtSearchFin
|
||||
EvtClose
|
||||
)
|
||||
|
||||
func TestEventBox(t *testing.T) {
|
||||
eb := NewEventBox()
|
||||
|
||||
// Wait should return immediately
|
||||
ch := make(chan bool)
|
||||
|
||||
go func() {
|
||||
eb.Set(EvtReadNew, 10)
|
||||
ch <- true
|
||||
<-ch
|
||||
eb.Set(EvtSearchNew, 10)
|
||||
eb.Set(EvtSearchNew, 15)
|
||||
eb.Set(EvtSearchNew, 20)
|
||||
eb.Set(EvtSearchProgress, 30)
|
||||
ch <- true
|
||||
<-ch
|
||||
eb.Set(EvtSearchFin, 40)
|
||||
ch <- true
|
||||
<-ch
|
||||
}()
|
||||
|
||||
count := 0
|
||||
sum := 0
|
||||
looping := true
|
||||
for looping {
|
||||
<-ch
|
||||
eb.Wait(func(events *Events) {
|
||||
for _, value := range *events {
|
||||
switch val := value.(type) {
|
||||
case int:
|
||||
sum += val
|
||||
looping = sum < 100
|
||||
}
|
||||
}
|
||||
events.Clear()
|
||||
})
|
||||
ch <- true
|
||||
count++
|
||||
}
|
||||
|
||||
if count != 3 {
|
||||
t.Error("Invalid number of events", count)
|
||||
}
|
||||
if sum != 100 {
|
||||
t.Error("Invalid sum", sum)
|
||||
}
|
||||
}
|
||||
@ -1,12 +0,0 @@
|
||||
package util
|
||||
|
||||
type Slab struct {
|
||||
I16 []int16
|
||||
I32 []int32
|
||||
}
|
||||
|
||||
func MakeSlab(size16 int, size32 int) *Slab {
|
||||
return &Slab{
|
||||
I16: make([]int16, size16),
|
||||
I32: make([]int32, size32)}
|
||||
}
|
||||
@ -1,138 +0,0 @@
|
||||
package util
|
||||
|
||||
import (
|
||||
"math"
|
||||
"os"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/mattn/go-isatty"
|
||||
"github.com/mattn/go-runewidth"
|
||||
"github.com/rivo/uniseg"
|
||||
)
|
||||
|
||||
// RunesWidth returns runes width
|
||||
func RunesWidth(runes []rune, prefixWidth int, tabstop int, limit int) (int, int) {
|
||||
width := 0
|
||||
gr := uniseg.NewGraphemes(string(runes))
|
||||
idx := 0
|
||||
for gr.Next() {
|
||||
rs := gr.Runes()
|
||||
var w int
|
||||
if len(rs) == 1 && rs[0] == '\t' {
|
||||
w = tabstop - (prefixWidth+width)%tabstop
|
||||
} else {
|
||||
s := string(rs)
|
||||
w = runewidth.StringWidth(s) + strings.Count(s, "\n")
|
||||
}
|
||||
width += w
|
||||
if limit > 0 && width > limit {
|
||||
return width, idx
|
||||
}
|
||||
idx += len(rs)
|
||||
}
|
||||
return width, -1
|
||||
}
|
||||
|
||||
// Max returns the largest integer
|
||||
func Max(first int, second int) int {
|
||||
if first >= second {
|
||||
return first
|
||||
}
|
||||
return second
|
||||
}
|
||||
|
||||
// Max16 returns the largest integer
|
||||
func Max16(first int16, second int16) int16 {
|
||||
if first >= second {
|
||||
return first
|
||||
}
|
||||
return second
|
||||
}
|
||||
|
||||
// Max32 returns the largest 32-bit integer
|
||||
func Max32(first int32, second int32) int32 {
|
||||
if first > second {
|
||||
return first
|
||||
}
|
||||
return second
|
||||
}
|
||||
|
||||
// Min returns the smallest integer
|
||||
func Min(first int, second int) int {
|
||||
if first <= second {
|
||||
return first
|
||||
}
|
||||
return second
|
||||
}
|
||||
|
||||
// Min32 returns the smallest 32-bit integer
|
||||
func Min32(first int32, second int32) int32 {
|
||||
if first <= second {
|
||||
return first
|
||||
}
|
||||
return second
|
||||
}
|
||||
|
||||
// Constrain32 limits the given 32-bit integer with the upper and lower bounds
|
||||
func Constrain32(val int32, min int32, max int32) int32 {
|
||||
if val < min {
|
||||
return min
|
||||
}
|
||||
if val > max {
|
||||
return max
|
||||
}
|
||||
return val
|
||||
}
|
||||
|
||||
// Constrain limits the given integer with the upper and lower bounds
|
||||
func Constrain(val int, min int, max int) int {
|
||||
if val < min {
|
||||
return min
|
||||
}
|
||||
if val > max {
|
||||
return max
|
||||
}
|
||||
return val
|
||||
}
|
||||
|
||||
func AsUint16(val int) uint16 {
|
||||
if val > math.MaxUint16 {
|
||||
return math.MaxUint16
|
||||
} else if val < 0 {
|
||||
return 0
|
||||
}
|
||||
return uint16(val)
|
||||
}
|
||||
|
||||
// DurWithin limits the given time.Duration with the upper and lower bounds
|
||||
func DurWithin(
|
||||
val time.Duration, min time.Duration, max time.Duration) time.Duration {
|
||||
if val < min {
|
||||
return min
|
||||
}
|
||||
if val > max {
|
||||
return max
|
||||
}
|
||||
return val
|
||||
}
|
||||
|
||||
// IsTty returns true if stdin is a terminal
|
||||
func IsTty() bool {
|
||||
return isatty.IsTerminal(os.Stdin.Fd())
|
||||
}
|
||||
|
||||
// ToTty returns true if stdout is a terminal
|
||||
func ToTty() bool {
|
||||
return isatty.IsTerminal(os.Stdout.Fd())
|
||||
}
|
||||
|
||||
// Once returns a function that returns the specified boolean value only once
|
||||
func Once(nextResponse bool) func() bool {
|
||||
state := nextResponse
|
||||
return func() bool {
|
||||
prevState := state
|
||||
state = false
|
||||
return prevState
|
||||
}
|
||||
}
|
||||
@ -1,40 +0,0 @@
|
||||
package util
|
||||
|
||||
import "testing"
|
||||
|
||||
func TestMax(t *testing.T) {
|
||||
if Max(-2, 5) != 5 {
|
||||
t.Error("Invalid result")
|
||||
}
|
||||
}
|
||||
|
||||
func TestContrain(t *testing.T) {
|
||||
if Constrain(-3, -1, 3) != -1 {
|
||||
t.Error("Expected", -1)
|
||||
}
|
||||
if Constrain(2, -1, 3) != 2 {
|
||||
t.Error("Expected", 2)
|
||||
}
|
||||
|
||||
if Constrain(5, -1, 3) != 3 {
|
||||
t.Error("Expected", 3)
|
||||
}
|
||||
}
|
||||
|
||||
func TestOnce(t *testing.T) {
|
||||
o := Once(false)
|
||||
if o() {
|
||||
t.Error("Expected: false")
|
||||
}
|
||||
if o() {
|
||||
t.Error("Expected: false")
|
||||
}
|
||||
|
||||
o = Once(true)
|
||||
if !o() {
|
||||
t.Error("Expected: true")
|
||||
}
|
||||
if o() {
|
||||
t.Error("Expected: false")
|
||||
}
|
||||
}
|
||||
@ -1,47 +0,0 @@
|
||||
// +build !windows
|
||||
|
||||
package util
|
||||
|
||||
import (
|
||||
"os"
|
||||
"os/exec"
|
||||
"syscall"
|
||||
)
|
||||
|
||||
// ExecCommand executes the given command with $SHELL
|
||||
func ExecCommand(command string, setpgid bool) *exec.Cmd {
|
||||
shell := os.Getenv("SHELL")
|
||||
if len(shell) == 0 {
|
||||
shell = "sh"
|
||||
}
|
||||
return ExecCommandWith(shell, command, setpgid)
|
||||
}
|
||||
|
||||
// ExecCommandWith executes the given command with the specified shell
|
||||
func ExecCommandWith(shell string, command string, setpgid bool) *exec.Cmd {
|
||||
cmd := exec.Command(shell, "-c", command)
|
||||
if setpgid {
|
||||
cmd.SysProcAttr = &syscall.SysProcAttr{Setpgid: true}
|
||||
}
|
||||
return cmd
|
||||
}
|
||||
|
||||
// KillCommand kills the process for the given command
|
||||
func KillCommand(cmd *exec.Cmd) error {
|
||||
return syscall.Kill(-cmd.Process.Pid, syscall.SIGKILL)
|
||||
}
|
||||
|
||||
// IsWindows returns true on Windows
|
||||
func IsWindows() bool {
|
||||
return false
|
||||
}
|
||||
|
||||
// SetNonblock executes syscall.SetNonblock on file descriptor
|
||||
func SetNonblock(file *os.File, nonblock bool) {
|
||||
syscall.SetNonblock(int(file.Fd()), nonblock)
|
||||
}
|
||||
|
||||
// Read executes syscall.Read on file descriptor
|
||||
func Read(fd int, b []byte) (int, error) {
|
||||
return syscall.Read(int(fd), b)
|
||||
}
|
||||
@ -1,83 +0,0 @@
|
||||
// +build windows
|
||||
|
||||
package util
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
"os/exec"
|
||||
"strings"
|
||||
"sync/atomic"
|
||||
"syscall"
|
||||
)
|
||||
|
||||
var shellPath atomic.Value
|
||||
|
||||
// ExecCommand executes the given command with $SHELL
|
||||
func ExecCommand(command string, setpgid bool) *exec.Cmd {
|
||||
var shell string
|
||||
if cached := shellPath.Load(); cached != nil {
|
||||
shell = cached.(string)
|
||||
} else {
|
||||
shell = os.Getenv("SHELL")
|
||||
if len(shell) == 0 {
|
||||
shell = "cmd"
|
||||
} else if strings.Contains(shell, "/") {
|
||||
out, err := exec.Command("cygpath", "-w", shell).Output()
|
||||
if err == nil {
|
||||
shell = strings.Trim(string(out), "\n")
|
||||
}
|
||||
}
|
||||
shellPath.Store(shell)
|
||||
}
|
||||
return ExecCommandWith(shell, command, setpgid)
|
||||
}
|
||||
|
||||
// ExecCommandWith executes the given command with the specified shell
|
||||
// FIXME: setpgid is unused. We set it in the Unix implementation so that we
|
||||
// can kill preview process with its child processes at once.
|
||||
// NOTE: For "powershell", we should ideally set output encoding to UTF8,
|
||||
// but it is left as is now because no adverse effect has been observed.
|
||||
func ExecCommandWith(shell string, command string, setpgid bool) *exec.Cmd {
|
||||
var cmd *exec.Cmd
|
||||
if strings.Contains(shell, "cmd") {
|
||||
cmd = exec.Command(shell)
|
||||
cmd.SysProcAttr = &syscall.SysProcAttr{
|
||||
HideWindow: false,
|
||||
CmdLine: fmt.Sprintf(` /v:on/s/c "%s"`, command),
|
||||
CreationFlags: 0,
|
||||
}
|
||||
return cmd
|
||||
}
|
||||
|
||||
if strings.Contains(shell, "pwsh") || strings.Contains(shell, "powershell") {
|
||||
cmd = exec.Command(shell, "-NoProfile", "-Command", command)
|
||||
} else {
|
||||
cmd = exec.Command(shell, "-c", command)
|
||||
}
|
||||
cmd.SysProcAttr = &syscall.SysProcAttr{
|
||||
HideWindow: false,
|
||||
CreationFlags: 0,
|
||||
}
|
||||
return cmd
|
||||
}
|
||||
|
||||
// KillCommand kills the process for the given command
|
||||
func KillCommand(cmd *exec.Cmd) error {
|
||||
return cmd.Process.Kill()
|
||||
}
|
||||
|
||||
// IsWindows returns true on Windows
|
||||
func IsWindows() bool {
|
||||
return true
|
||||
}
|
||||
|
||||
// SetNonblock executes syscall.SetNonblock on file descriptor
|
||||
func SetNonblock(file *os.File, nonblock bool) {
|
||||
syscall.SetNonblock(syscall.Handle(file.Fd()), nonblock)
|
||||
}
|
||||
|
||||
// Read executes syscall.Read on file descriptor
|
||||
func Read(fd int, b []byte) (int, error) {
|
||||
return syscall.Read(syscall.Handle(fd), b)
|
||||
}
|
||||
@ -1,175 +0,0 @@
|
||||
Execute (Setup):
|
||||
let g:dir = fnamemodify(g:vader_file, ':p:h')
|
||||
unlet! g:fzf_layout g:fzf_action g:fzf_history_dir
|
||||
Log 'Test directory: ' . g:dir
|
||||
Save &acd
|
||||
|
||||
Execute (fzf#run with dir option):
|
||||
let cwd = getcwd()
|
||||
let result = fzf#run({ 'source': 'git ls-files', 'options': '--filter=vdr', 'dir': g:dir })
|
||||
AssertEqual ['fzf.vader'], result
|
||||
AssertEqual 0, haslocaldir()
|
||||
AssertEqual getcwd(), cwd
|
||||
|
||||
execute 'lcd' fnameescape(cwd)
|
||||
let result = sort(fzf#run({ 'source': 'git ls-files', 'options': '--filter e', 'dir': g:dir }))
|
||||
AssertEqual ['fzf.vader', 'test_go.rb'], result
|
||||
AssertEqual 1, haslocaldir()
|
||||
AssertEqual getcwd(), cwd
|
||||
|
||||
Execute (fzf#run with Funcref command):
|
||||
let g:ret = []
|
||||
function! g:FzfTest(e)
|
||||
call add(g:ret, a:e)
|
||||
endfunction
|
||||
let result = sort(fzf#run({ 'source': 'git ls-files', 'sink': function('g:FzfTest'), 'options': '--filter e', 'dir': g:dir }))
|
||||
AssertEqual ['fzf.vader', 'test_go.rb'], result
|
||||
AssertEqual ['fzf.vader', 'test_go.rb'], sort(g:ret)
|
||||
|
||||
Execute (fzf#run with string source):
|
||||
let result = sort(fzf#run({ 'source': 'echo hi', 'options': '-f i' }))
|
||||
AssertEqual ['hi'], result
|
||||
|
||||
Execute (fzf#run with list source):
|
||||
let result = sort(fzf#run({ 'source': ['hello', 'world'], 'options': '-f e' }))
|
||||
AssertEqual ['hello'], result
|
||||
let result = sort(fzf#run({ 'source': ['hello', 'world'], 'options': '-f o' }))
|
||||
AssertEqual ['hello', 'world'], result
|
||||
|
||||
Execute (fzf#run with string source):
|
||||
let result = sort(fzf#run({ 'source': 'echo hi', 'options': '-f i' }))
|
||||
AssertEqual ['hi'], result
|
||||
|
||||
Execute (fzf#run with dir option and noautochdir):
|
||||
set noacd
|
||||
let cwd = getcwd()
|
||||
call fzf#run({'source': ['/foobar'], 'sink': 'e', 'dir': '/tmp', 'options': '-1'})
|
||||
" No change in working directory
|
||||
AssertEqual cwd, getcwd()
|
||||
|
||||
call fzf#run({'source': ['/foobar'], 'sink': 'tabe', 'dir': '/tmp', 'options': '-1'})
|
||||
AssertEqual cwd, getcwd()
|
||||
tabclose
|
||||
AssertEqual cwd, getcwd()
|
||||
|
||||
Execute (Incomplete fzf#run with dir option and autochdir):
|
||||
set acd
|
||||
let cwd = getcwd()
|
||||
call fzf#run({'source': [], 'sink': 'e', 'dir': '/tmp', 'options': '-0'})
|
||||
" No change in working directory even if &acd is set
|
||||
AssertEqual cwd, getcwd()
|
||||
|
||||
Execute (FIXME: fzf#run with dir option and autochdir):
|
||||
set acd
|
||||
call fzf#run({'source': ['/foobar'], 'sink': 'e', 'dir': '/tmp', 'options': '-1'})
|
||||
" Working directory changed due to &acd
|
||||
AssertEqual '/foobar', expand('%')
|
||||
AssertEqual '/', getcwd()
|
||||
|
||||
Execute (fzf#run with dir option and autochdir when final cwd is same as dir):
|
||||
set acd
|
||||
cd /tmp
|
||||
call fzf#run({'source': ['/foobar'], 'sink': 'e', 'dir': '/', 'options': '-1'})
|
||||
" Working directory changed due to &acd
|
||||
AssertEqual '/', getcwd()
|
||||
|
||||
Execute (fzf#wrap):
|
||||
AssertThrows fzf#wrap({'foo': 'bar'})
|
||||
|
||||
let opts = fzf#wrap('foobar')
|
||||
Log opts
|
||||
AssertEqual '~40%', opts.down
|
||||
Assert opts.options =~ '--expect='
|
||||
Assert !has_key(opts, 'sink')
|
||||
Assert has_key(opts, 'sink*')
|
||||
|
||||
let opts = fzf#wrap('foobar', {}, 0)
|
||||
Log opts
|
||||
AssertEqual '~40%', opts.down
|
||||
|
||||
let opts = fzf#wrap('foobar', {}, 1)
|
||||
Log opts
|
||||
Assert !has_key(opts, 'down')
|
||||
|
||||
let opts = fzf#wrap('foobar', {'down': '50%'})
|
||||
Log opts
|
||||
AssertEqual '50%', opts.down
|
||||
|
||||
let opts = fzf#wrap('foobar', {'down': '50%'}, 1)
|
||||
Log opts
|
||||
Assert !has_key(opts, 'down')
|
||||
|
||||
let opts = fzf#wrap('foobar', {'sink': 'e'})
|
||||
Log opts
|
||||
AssertEqual 'e', opts.sink
|
||||
Assert !has_key(opts, 'sink*')
|
||||
|
||||
let opts = fzf#wrap('foobar', {'options': '--reverse'})
|
||||
Log opts
|
||||
Assert opts.options =~ '--expect='
|
||||
Assert opts.options =~ '--reverse'
|
||||
|
||||
let g:fzf_layout = {'window': 'enew'}
|
||||
let opts = fzf#wrap('foobar')
|
||||
Log opts
|
||||
AssertEqual 'enew', opts.window
|
||||
|
||||
let opts = fzf#wrap('foobar', {}, 1)
|
||||
Log opts
|
||||
Assert !has_key(opts, 'window')
|
||||
|
||||
let opts = fzf#wrap('foobar', {'right': '50%'})
|
||||
Log opts
|
||||
Assert !has_key(opts, 'window')
|
||||
AssertEqual '50%', opts.right
|
||||
|
||||
let opts = fzf#wrap('foobar', {'right': '50%'}, 1)
|
||||
Log opts
|
||||
Assert !has_key(opts, 'window')
|
||||
Assert !has_key(opts, 'right')
|
||||
|
||||
let g:fzf_action = {'a': 'tabe'}
|
||||
let opts = fzf#wrap('foobar')
|
||||
Log opts
|
||||
Assert opts.options =~ '--expect=a'
|
||||
Assert !has_key(opts, 'sink')
|
||||
Assert has_key(opts, 'sink*')
|
||||
|
||||
let opts = fzf#wrap('foobar', {'sink': 'e'})
|
||||
Log opts
|
||||
AssertEqual 'e', opts.sink
|
||||
Assert !has_key(opts, 'sink*')
|
||||
|
||||
let g:fzf_history_dir = '/tmp'
|
||||
let opts = fzf#wrap('foobar', {'options': '--color light'})
|
||||
Log opts
|
||||
Assert opts.options =~ "--history '/tmp/foobar'"
|
||||
Assert opts.options =~ '--color light'
|
||||
|
||||
let g:fzf_colors = { 'fg': ['fg', 'Error'] }
|
||||
let opts = fzf#wrap({})
|
||||
Assert opts.options =~ '^--color=fg:'
|
||||
|
||||
Execute (fzf#shellescape with sh):
|
||||
AssertEqual '''''', fzf#shellescape('', 'sh')
|
||||
AssertEqual '''\''', fzf#shellescape('\', 'sh')
|
||||
AssertEqual '''""''', fzf#shellescape('""', 'sh')
|
||||
AssertEqual '''foobar>''', fzf#shellescape('foobar>', 'sh')
|
||||
AssertEqual '''\\\"\\\''', fzf#shellescape('\\\"\\\', 'sh')
|
||||
AssertEqual '''echo ''\''''a''\'''' && echo ''\''''b''\''''''', fzf#shellescape('echo ''a'' && echo ''b''', 'sh')
|
||||
|
||||
Execute (fzf#shellescape with cmd.exe):
|
||||
AssertEqual '^"^"', fzf#shellescape('', 'cmd.exe')
|
||||
AssertEqual '^"\\^"', fzf#shellescape('\', 'cmd.exe')
|
||||
AssertEqual '^"\^"\^"^"', fzf#shellescape('""', 'cmd.exe')
|
||||
AssertEqual '^"foobar^>^"', fzf#shellescape('foobar>', 'cmd.exe')
|
||||
AssertEqual '^"\\\\\\\^"\\\\\\^"', fzf#shellescape('\\\"\\\', 'cmd.exe')
|
||||
AssertEqual '^"echo ''a'' ^&^& echo ''b''^"', fzf#shellescape('echo ''a'' && echo ''b''', 'cmd.exe')
|
||||
|
||||
AssertEqual '^"C:\Program Files ^(x86^)\\^"', fzf#shellescape('C:\Program Files (x86)\', 'cmd.exe')
|
||||
AssertEqual '^"C:/Program Files ^(x86^)/^"', fzf#shellescape('C:/Program Files (x86)/', 'cmd.exe')
|
||||
AssertEqual '^"%%USERPROFILE%%^"', fzf#shellescape('%USERPROFILE%', 'cmd.exe')
|
||||
|
||||
Execute (Cleanup):
|
||||
unlet g:dir
|
||||
Restore
|
||||
2626
.fzf/test/test_go.rb
2626
.fzf/test/test_go.rb
File diff suppressed because it is too large
Load Diff
117
.fzf/uninstall
117
.fzf/uninstall
@ -1,117 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
|
||||
xdg=0
|
||||
prefix='~/.fzf'
|
||||
prefix_expand=~/.fzf
|
||||
fish_dir=${XDG_CONFIG_HOME:-$HOME/.config}/fish
|
||||
|
||||
help() {
|
||||
cat << EOF
|
||||
usage: $0 [OPTIONS]
|
||||
|
||||
--help Show this message
|
||||
--xdg Remove files generated under \$XDG_CONFIG_HOME/fzf
|
||||
EOF
|
||||
}
|
||||
|
||||
for opt in "$@"; do
|
||||
case $opt in
|
||||
--help)
|
||||
help
|
||||
exit 0
|
||||
;;
|
||||
--xdg)
|
||||
xdg=1
|
||||
prefix='"${XDG_CONFIG_HOME:-$HOME/.config}"/fzf/fzf'
|
||||
prefix_expand=${XDG_CONFIG_HOME:-$HOME/.config}/fzf/fzf
|
||||
;;
|
||||
*)
|
||||
echo "unknown option: $opt"
|
||||
help
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
ask() {
|
||||
while true; do
|
||||
read -p "$1 ([y]/n) " -r
|
||||
REPLY=${REPLY:-"y"}
|
||||
if [[ $REPLY =~ ^[Yy]$ ]]; then
|
||||
return 0
|
||||
elif [[ $REPLY =~ ^[Nn]$ ]]; then
|
||||
return 1
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
remove() {
|
||||
echo "Remove $1"
|
||||
rm -f "$1"
|
||||
}
|
||||
|
||||
remove_line() {
|
||||
src=$(readlink "$1")
|
||||
if [ $? -eq 0 ]; then
|
||||
echo "Remove from $1 ($src):"
|
||||
else
|
||||
src=$1
|
||||
echo "Remove from $1:"
|
||||
fi
|
||||
|
||||
shift
|
||||
line_no=1
|
||||
match=0
|
||||
while [ -n "$1" ]; do
|
||||
line=$(sed -n "$line_no,\$p" "$src" | \grep -m1 -nF "$1")
|
||||
if [ $? -ne 0 ]; then
|
||||
shift
|
||||
line_no=1
|
||||
continue
|
||||
fi
|
||||
line_no=$(( $(sed 's/:.*//' <<< "$line") + line_no - 1 ))
|
||||
content=$(sed 's/^[0-9]*://' <<< "$line")
|
||||
match=1
|
||||
echo " - Line #$line_no: $content"
|
||||
[ "$content" = "$1" ] || ask " - Remove?"
|
||||
if [ $? -eq 0 ]; then
|
||||
awk -v n=$line_no 'NR == n {next} {print}' "$src" > "$src.bak" &&
|
||||
mv "$src.bak" "$src" || break
|
||||
echo " - Removed"
|
||||
else
|
||||
echo " - Skipped"
|
||||
line_no=$(( line_no + 1 ))
|
||||
fi
|
||||
done
|
||||
[ $match -eq 0 ] && echo " - Nothing found"
|
||||
echo
|
||||
}
|
||||
|
||||
for shell in bash zsh; do
|
||||
shell_config=${prefix_expand}.${shell}
|
||||
remove "${shell_config}"
|
||||
remove_line ~/.${shell}rc \
|
||||
"[ -f ${prefix}.${shell} ] && source ${prefix}.${shell}" \
|
||||
"source ${prefix}.${shell}"
|
||||
done
|
||||
|
||||
bind_file="${fish_dir}/functions/fish_user_key_bindings.fish"
|
||||
if [ -f "$bind_file" ]; then
|
||||
remove_line "$bind_file" "fzf_key_bindings"
|
||||
fi
|
||||
|
||||
if [ -d "${fish_dir}/functions" ]; then
|
||||
remove "${fish_dir}/functions/fzf.fish"
|
||||
remove "${fish_dir}/functions/fzf_key_bindings.fish"
|
||||
|
||||
if [ -z "$(ls -A "${fish_dir}/functions")" ]; then
|
||||
rmdir "${fish_dir}/functions"
|
||||
else
|
||||
echo "Can't delete non-empty directory: \"${fish_dir}/functions\""
|
||||
fi
|
||||
fi
|
||||
|
||||
config_dir=$(dirname "$prefix_expand")
|
||||
if [[ "$xdg" = 1 ]] && [[ "$config_dir" = */fzf ]] && [[ -d "$config_dir" ]]; then
|
||||
rmdir "$config_dir"
|
||||
fi
|
||||
Loading…
x
Reference in New Issue
Block a user